

This post is co-written with Jessie Jiao from Crypto.com. Crypto.com is a crypto exchange and comprehensive trading service serving 140 million users in 90 countries. To improve the service quality of Crypto.com, the firm implemented generative AI-powered assistant services on AWS.
Modern AI assistants—artificial intelligence systems designed to interact with users through natural language, answer questions, and even perform tasks—face increasingly complex challenges in production environments. Beyond handling basic FAQs, they must now execute meaningful actions, adhere to company policies, implement content filtering, escalate to human operators when needed, and manage follow-up tasks. These requirements demand sophisticated systems capable of handling diverse scenarios while maintaining consistency and compliance.
To address these challenges, a modular subsystem architecture proves invaluable. This architectural approach divides an AI system into separate, specialized components that can function independently while working together as a cohesive whole. Such design allows for flexible integration of different processing logics, such as intelligent routing between knowledge bases, dynamic prioritization of information sources, and seamless incorporation of business rules and policies. Each subsystem can be independently developed and optimized for specific tasks while maintaining overall system coherence.
As AI assistant systems grow in complexity, with multiple subsystems handling various workloads, prompt engineering emerges as a critical discipline. This art of carefully crafting input text guides language model responses and facilitates consistent behavior across interconnected components. Crafting effective prompts that work across different subsystems while maintaining consistency and accuracy is both critical and time-intensive. This challenge is particularly acute in enterprise environments where precision and reliability are paramount.
In this post, we explore how we used user and system feedback to continuously improve and optimize our instruction prompts. This feedback-driven approach has enabled us to create more effective prompts that adapt to various subsystems while maintaining high performance across different use cases.
Feedback and reasoning: The key to LLM performance improvement
Although large language models (LLMs) have demonstrated remarkable capabilities, they can sometimes struggle with complex or ambiguous inputs. This is where feedback mechanisms become essential. By incorporating feedback loops, LLMs can learn from their mistakes, refine the instruction, and adapt to challenging scenarios.
One powerful approach is critiquing, where LLMs are paired with an external feedback mechanism that provide critiques or feedback. For instance, when processing documents, if an LLM generates an incorrect summary, a fact-checking tool can identify inaccuracies and provide feedback. The model can then revise its output, leading to improved accuracy and reliability. This iterative process mirrors human learning, where feedback drives continuous improvement. Consider an example where a customer asks an enterprise AI assistant, “I need to increase my credit limit immediately for an emergency purchase.” The assistant might initially respond with approval steps without verification, but a critique system would flag: “Response bypasses required identity verification protocol and fails to assess qualification criteria per company policy.” With this feedback, the assistant can revise its response to include proper authentication steps, eligibility checking, and alternative options for emergency situations—demonstrating how critiquing facilitates adherence to business rules while maintaining helpful customer service.
Unlike traditional machine learning (ML) processes where feedback serves as a loss function to update model weights, these feedback mechanisms operate differently in inference-time LLM applications. Rather than modifying the underlying model parameters, feedback provides supplementary instructions that dynamically guide the model’s behavior. This approach allows for behavioral adaptation without the computational expense of retraining, effectively creating a flexible instruction layer that shapes model outputs while preserving the core capabilities of the pre-trained model. Such runtime adaptability represents a significant advancement in making LLMs more responsive to specific requirements without architectural modifications.
The effectiveness of feedback mechanisms extends beyond simple error correction, enabling LLMs to develop a nuanced understanding of task requirements. Through iterative feedback cycles, models can learn to interpret ambiguous instructions more effectively, identify implicit context, and adapt their processing strategies accordingly. This capability is particularly valuable in enterprise settings where complex, domain-specific tasks require precise interpretation of instructions. By analyzing feedback patterns over time, LLMs can even anticipate potential misunderstandings and proactively adjust their approach, leading to more efficient and accurate outcomes. In our research implementing this approach for financial services classification tasks, we observed substantial performance improvements—from initial accuracy rates of 60% to eventually achieving 100% through systematic feedback incorporation. Each iteration addressed specific weaknesses identified in previous rounds, demonstrating how structured critique leads to continuous model improvement.
For deeper insights into these mechanisms, we recommend exploring two key research papers: CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing, which demonstrates how LLMs can self-correct with tool-interactive critiquing, and Reflexion: Language Agents with Verbal Reinforcement Learning, which explores language agents with verbal reinforcement learning. The following figure provides a visual representation of this feedback process.
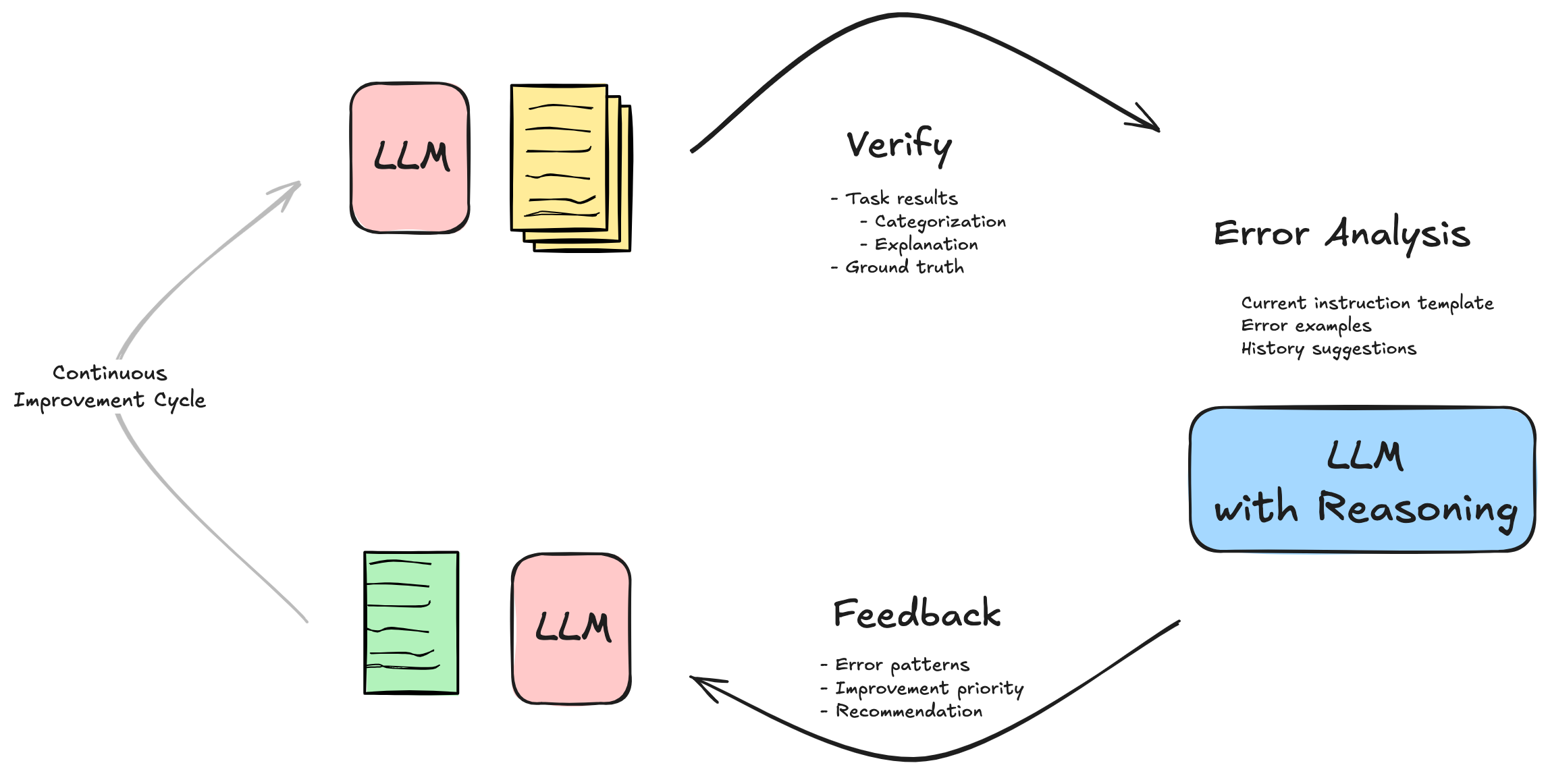
Recent developments in reasoning capabilities have made this feedback process even more powerful. Modern LLMs can now engage in sophisticated analysis of their own outputs, breaking down complex problems into manageable components and systematically evaluating each aspect of their performance. To learn more, see Anthropic’s Claude 3.7 Sonnet hybrid reasoning model is now available in Amazon Bedrock and DeepSeek-R1 now available as a fully managed serverless model in Amazon Bedrock. This self-analysis capability, combined with external feedback, creates a robust framework for continuous improvement.
Consider a scenario where an LLM is tasked with sentiment analysis. Initially, when classifying a mixed review like “The product worked as advertised, but customer service was disappointing,” the model might incorrectly label it as positive. Through error analysis and verification, a critique mechanism (powered by a separate reasoning model) can provide targeted feedback, explaining that negative statements about service quality significantly impact overall sentiment. This feedback doesn’t modify the model’s weights but instead serves as supplementary instruction that enriches the original prompt template, helping the model properly weigh contrasting sentiments within the same text.
Over multiple feedback iterations, the LLM employs reasoning capabilities to incorporate this external feedback and develop more sophisticated classification heuristics. With the critique system continuously verifying outputs and providing constructive guidance, the model learns to identify why certain patterns lead to misclassifications and refines its approach accordingly. When encountering new ambiguous reviews, it can now apply these learned insights to correctly interpret subtle emotional nuances. This demonstrates how reasoning-based feedback effectively modifies the instruction context without requiring parameter adjustments, allowing for continuous improvement through analytical understanding rather than mechanical optimization.
In the next section, we explore how these feedback mechanisms and reasoning capability can be operationalized to enhance workflows.
Solution overview
The integration of feedback and reasoning creates a powerful learning loop: feedback identifies areas for improvement, reasoning capabilities analyze the root causes of issues, and the resulting insights drive specific, actionable changes. This systematic approach to improvement makes sure that each iteration brings the model closer to optimal performance, while maintaining transparency and accountability in the development process.
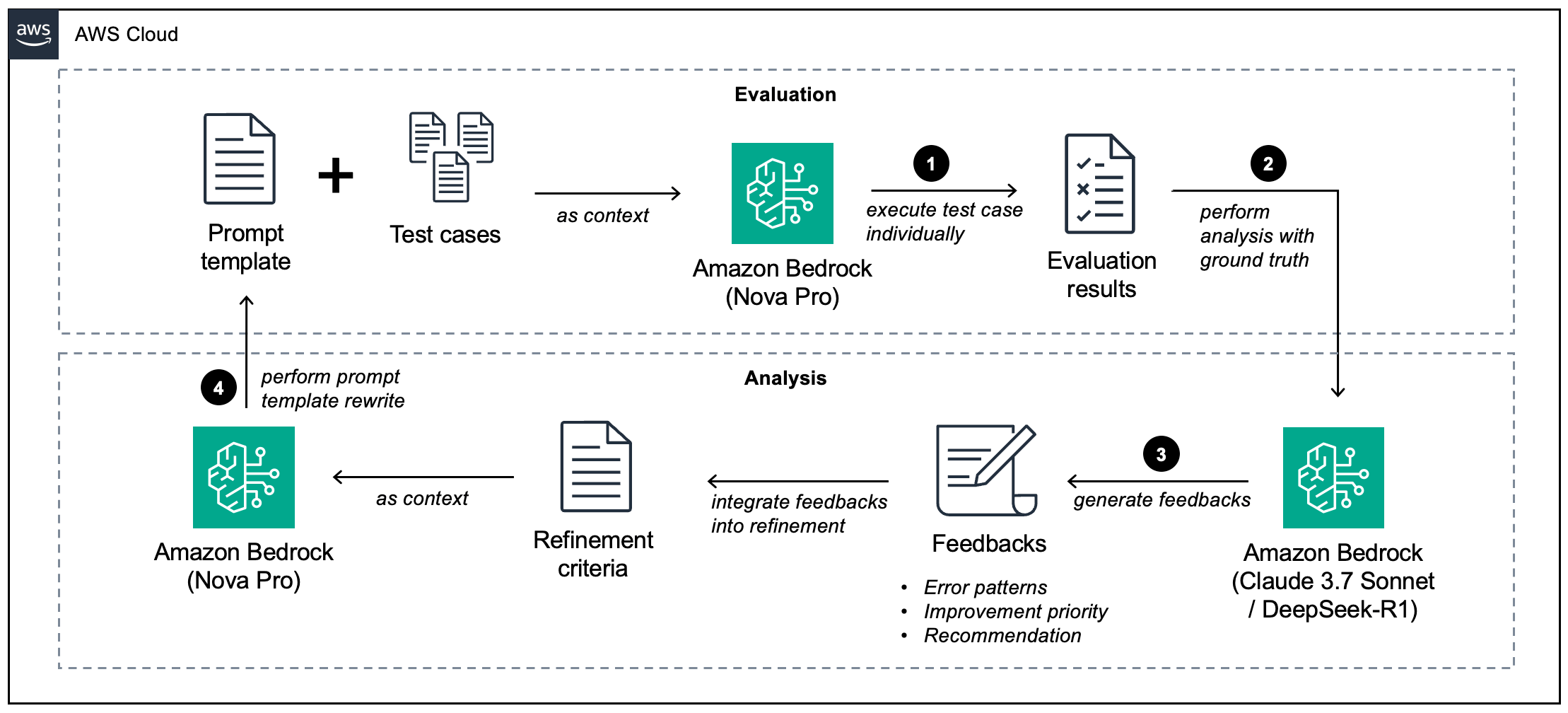
For practical examples and complete implementation code of this process, check out our GitHub repository. This repository includes sample datasets, evaluation frameworks, and ready-to-use templates for each step of the optimization workflow.
Our proposed solution uses two foundation models (FMs) through Amazon Bedrock: Amazon Nova for executing instructional tasks and optimizing the instruction prompt, and Anthropic’s Claude 3.7 or DeepSeek-R1 for error analysis and feedback generation. Amazon Bedrock, a fully managed service, provides access to high-performance FMs from leading AI companies, enabling flexible model selection and testing. You can explore illustration_notebook_optimization_prompt.ipynb for a quick walkthrough of the high-level process for LLM optimization, which demonstrates key concepts and implementation details in an accessible format.
LLM optimization workflow
The following is the high-level process for LLM optimization:
- The process begins with a precise articulation of task requirements and success criteria. This crucial first step involves three key components: defining specific task objectives, crafting a well-structured prompt template with clear instructions, and assembling a comprehensive evaluation dataset with verified ground truth labels. During this phase, we establish quantifiable success metrics and acceptance criteria to measure improvement effectively. The Amazon Nova Pro understanding model is configured to provide both task outputs and detailed explanations for its decisions, enabling transparency in the evaluation process.
For illustration, we started with a simple prompt template to categorize customer inquiries into multiple classes, such as PASSWORD_RESET, ESCALATION, and OUT_OF_SCOPE. This initial template provided only basic category definitions without detailed guidance on edge cases or classification priorities, serving as our baseline for improvement. You can refer to the test case dataset and initial template.
- Following the setup, we conduct rigorous testing against ground truth data to evaluate model performance. This evaluation focuses on both successful and failed cases, with particular emphasis on analyzing misclassifications. The model’s generated explanations for each decision serve as valuable insights into its reasoning process. We collect both quantitative performance metrics (accuracy, precision, recall) and qualitative insights into error patterns, creating a comprehensive performance baseline.
During this step, we compare model predictions to ground truth labels and record both quantitative metrics and detailed error cases. For example, when a customer urgently reports unauthorized account changes with “Someone must have accessed my account…I need this fixed immediately”, the model might incorrectly classify it as CARD_DISPUTE instead of the correct ESCALATION category. Each prediction is logged with its success status (true/false), the model’s explanation, and the correct label. This comprehensive analysis creates a structured dataset of both successful classifications and failure cases, providing critical input for the reasoning-based optimization in the next step.
- The key step of our optimization process lies in systematic error analysis using a dedicated reasoning framework. This framework examines the model’s explanations for each error case, identifying root causes and pattern recognition failures. Beyond individual error analysis, we employ pattern recognition to identify systemic issues across multiple cases. The reasoning model, in our case Anthropic’s Claude 3.7, incorporates historical feedback and learning patterns to generate specific, actionable feedback for prompt improvement. This critical step produces structured, detailed recommendations for prompt optimization.
The reasoning model analyzed classification performance through a structured framework that identified error patterns, investigated prompt-specific root causes, considered historical context from previous iterations, and suggested targeted improvements. This methodical approach focused exclusively on enhancing prompt clarity, structure, and precision—avoiding model or data modifications outside the scope of prompt engineering. By systematically addressing ambiguities and refining classification criteria, we achieved progressively better performance with each iteration. See the following code:
You can see the detailed implementation in error_analysis_with_reasoning.py.
- Using the structured feedback from the reasoning framework, we implement targeted modifications to the prompt template. These refinements might include enhancing instruction clarity, adjusting classification parameters, or restructuring the prompt format. Each modification directly addresses specific issues identified in the analysis phase, making sure changes are evidence-based and purposeful. The focus remains on improving the instruction layer rather than modifying the underlying model architecture.
To implement these structured improvements, we developed a systematic prompt rewriting mechanism encoded in our prompt_rewrite.py module. This component transforms analytical feedback into concrete prompt enhancements through a dedicated template-based approach. The rewriting process follows a methodical workflow: it preserves essential components like placeholders, incorporates specific improvements identified in the analysis, and makes sure modifications directly address root causes from the feedback. This systematic rewriting approach guarantees that each iteration builds upon previous learnings rather than making arbitrary changes.
- The optimization process concludes each iteration by testing the refined prompt against the evaluation dataset. We measure performance improvements through comparative analysis of key metrics and conduct quality assessments of new outputs. This phase initiates the next iteration cycle, where successful changes are incorporated into the baseline, and newly identified challenges inform the next round of optimization. This creates a sustainable improvement loop that progressively enhances prompt effectiveness while maintaining detailed documentation of successful strategies.
Through our iterative refinement process, we transformed a basic prompt into a highly effective instruction set for LLMs. Each iteration strategically addressed specific weaknesses identified through our structured analysis framework. For complete documentation of each iteration’s analysis and improvements, see iteration_log.
What began as a simple prompt evolved into a comprehensive set of instructions incorporating nuanced task boundaries, explicit priority rules for edge cases, hierarchical decision criteria, and precise handling instructions for corner cases. Rather than modify model weights or architecture, our approach used targeted feedback from a critique mechanism to enhance the instruction layer, effectively guiding model behavior without retraining. Each iteration built upon lessons from previous rounds, systematically addressing error patterns revealed through our critique framework. The feedback served as supplementary instructions that enriched the original prompt template, allowing the model to develop increasingly sophisticated processing heuristics over time.
Results
Through these iterative approaches, we benchmarked the solution on the production system. Our comparative analysis between the initial and final prompts revealed several important patterns:
- Boundary confusion was resolved by adding explicit prioritization rules between overlapping categories
- Edge case handling improved by incorporating specific examples that defined thresholds for categorization
- Decision transparency increased through structured reasoning requirements in the output format
- Classification consistency was enhanced by adding counterexamples to help prevent overcategorization in sensitive areas
Through 10 deliberate iterations and the incorporation of detailed task-specific instructions, we achieved a remarkable 34-percentage-point improvement in task effectiveness, transforming a basic prompt with 60% accuracy into a robust classification system with 94% accuracy on challenging cases. This validates not only our iterative optimization strategy but demonstrates how systematic prompt refinement can dramatically enhance LLM model performance without modifying the underlying model architecture.
Conclusion
The integration of feedback mechanisms into AI assistant systems represents a significant leap forward in conversational AI capabilities. By implementing robust feedback loops, we’ve demonstrated how AI assistants can evolve from static question-answering systems to dynamic, self-improving resources. The modular subsystem architecture, combined with continuous prompt optimization through feedback, enables AI assistants to handle increasingly complex tasks while maintaining compliance and accuracy.
As we’ve shown through practical examples and research insights, feedback-driven systems not only produce better outputs but also allow for more effective and streamlined input instructions over time. This efficiency gain is particularly valuable in enterprise environments where precision and adaptability are crucial, and where model retraining is costly or impractical. Each iteration builds upon lessons from previous rounds, systematically addressing error patterns revealed through our critique framework.
Looking ahead, the continued refinement of feedback mechanisms and prompt engineering techniques will be essential for developing next-generation AI assistant systems. By embracing these approaches, organizations can create AI assistants that not only meet current demands but also adapt to future challenges, delivering increasingly sophisticated and reliable interactions. We invite you to try our proposed feedback-driven prompt optimization approach in your own applications. For those interested in implementing these techniques, Amazon Bedrock provides an ideal landscape for exploring these methods in your specific business contexts, offering a selection of FMs with flexible deployment options.
About the authors
 Jessie Jiao is a Senior Software Engineer at crypto.com, where she leverages her extensive experience in designing, building, and implementing enterprise applications with LLM models and AI technologies. She is passionate about harnessing the power of AI to drive business transformation and enhance operational efficiency.
Jessie Jiao is a Senior Software Engineer at crypto.com, where she leverages her extensive experience in designing, building, and implementing enterprise applications with LLM models and AI technologies. She is passionate about harnessing the power of AI to drive business transformation and enhance operational efficiency.
 Gary Lo is a Solutions Architect at AWS based in Hong Kong. He is a highly passionate IT professional with over 10 years of experience in designing and implementing critical and complex solutions for distributed systems, web applications, and mobile platforms for startups and enterprise companies. Outside of the office, he enjoys cooking and sharing the latest technology trends and insights on his social media platforms with thousands of followers.
Gary Lo is a Solutions Architect at AWS based in Hong Kong. He is a highly passionate IT professional with over 10 years of experience in designing and implementing critical and complex solutions for distributed systems, web applications, and mobile platforms for startups and enterprise companies. Outside of the office, he enjoys cooking and sharing the latest technology trends and insights on his social media platforms with thousands of followers.
 Yanwei Cui, PhD, is a Senior Machine Learning Specialist Solutions Architect at AWS. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building AI-powered industrial applications in computer vision, natural language processing, and online user behavior prediction. At AWS, he shares his domain expertise and helps customers unlock business potentials and drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
Yanwei Cui, PhD, is a Senior Machine Learning Specialist Solutions Architect at AWS. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building AI-powered industrial applications in computer vision, natural language processing, and online user behavior prediction. At AWS, he shares his domain expertise and helps customers unlock business potentials and drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
 Michelle Hong, PhD, works as Prototyping Solutions Architect at Amazon Web Services, where she helps customers build innovative applications using a variety of AWS components. She demonstrated her expertise in machine learning, particularly in natural language processing, to develop data-driven solutions that optimize business processes and improve customer experiences.
Michelle Hong, PhD, works as Prototyping Solutions Architect at Amazon Web Services, where she helps customers build innovative applications using a variety of AWS components. She demonstrated her expertise in machine learning, particularly in natural language processing, to develop data-driven solutions that optimize business processes and improve customer experiences.
")




")

