

Organizations serving multiple tenants through AI applications face a common challenge: how to track, analyze, and optimize model usage across different customer segments. Although Amazon Bedrock provides powerful foundation models (FMs) through its Converse API, the true business value emerges when you can connect model interactions to specific tenants, users, and use cases.
Using the Converse API requestMetadata parameter offers a solution to this challenge. By passing tenant-specific identifiers and contextual information with each request, you can transform standard invocation logs into rich analytical datasets. This approach means you can measure model performance, track usage patterns, and allocate costs with tenant-level precision—without modifying your core application logic.
Tracking and managing cost through application inference profiles
Managing costs for generative AI workloads is a challenge that organizations face daily, especially when using on-demand FMs that don’t support cost-allocation tagging. When you monitor spending manually and rely on reactive controls, you create risks of overspending while introducing operational inefficiencies.
Application inference profiles address this by allowing custom tags (for example, tenant, project, or department) to be applied directly to on-demand models, enabling granular cost tracking. Combined with AWS Budgets and cost allocation tools, organizations can automate budget alerts, prioritize critical workloads, and enforce spending guardrails at scale. This shift from manual oversight to programmatic control reduces financial risks while fostering innovation through enhanced visibility into AI spend across teams, applications, and tenants.
For tracking multi-tenant costs when dealing with tens to thousands of application inference profiles refer to Manage multi-tenant Amazon Bedrock costs using application inference profiles in the AWS Artificial Intelligence Blog post.
Managing costs and resources in large-scale multi-tenant environments adds complexity when you use application inference profiles in Amazon Bedrock. You face additional considerations when dealing with hundreds of thousands to millions of tenants and complex tagging requirements.
The lifecycle management of these profiles creates operational challenges. You need to handle profile creation, updates, and deletions at scale. Automating these processes requires robust error handling for edge cases like profile naming conflicts, Region-specific replication for high availability, and cascading AWS Identity and Access Management (IAM) policy updates that maintain secure access controls across tenants.
Another layer of complexity arises from cost allocation tagging constraints. Although organizations and teams can add multiple tags per application inference profile resource, organizations with granular tracking needs—such as combining tenant identifiers (tenantId), departmental codes (department), and cost centers (costCenter)—might find this limit restrictive, potentially compromising the depth of cost attribution. These considerations encourage organizations to implement a consumer or client-side tracking approach, and this is where metadata-based tagging might be a better fit.
Using Converse API with request metadata
You can use the Converse API to include request metadata when you call FMs through Amazon Bedrock. This metadata doesn’t affect the model’s response, but you can use it for tracking and logging purposes (JSON object with key-value pairs of metadata).Common uses for request metadata include:
- Adding unique identifiers for tracking requests
- Including timestamp information
- Tagging requests with application-specific information
- Adding version numbers or other contextual data
The request metadata is not typically returned in the API response. It’s primarily used for your own tracking and logging purposes on the client-side.
When using the Converse API, you typically include the request metadata as part of your API call. For example, using the AWS SDK for Python (Boto3), you might structure your request like this:
Solution overview
The following diagram illustrates a comprehensive log processing and analytics architecture across two main environments: a Customer virtual private cloud (VPC) and an AWS Service Account.
In the Customer VPC, the flow begins with Amazon Bedrock invocation logs being processed through an extract, transform, and load (ETL) pipeline managed by AWS Glue. The logs go through a scheduler and transformation process, with an AWS Glue crawler cataloging the data. Failed logs are captured in a separate storage location.
In the AWS Service Account section, the architecture shows the reporting and analysis capabilities. Amazon QuickSight Enterprise edition serves as the primary analytics and visualization service, with tenant-based reporting dashboards.
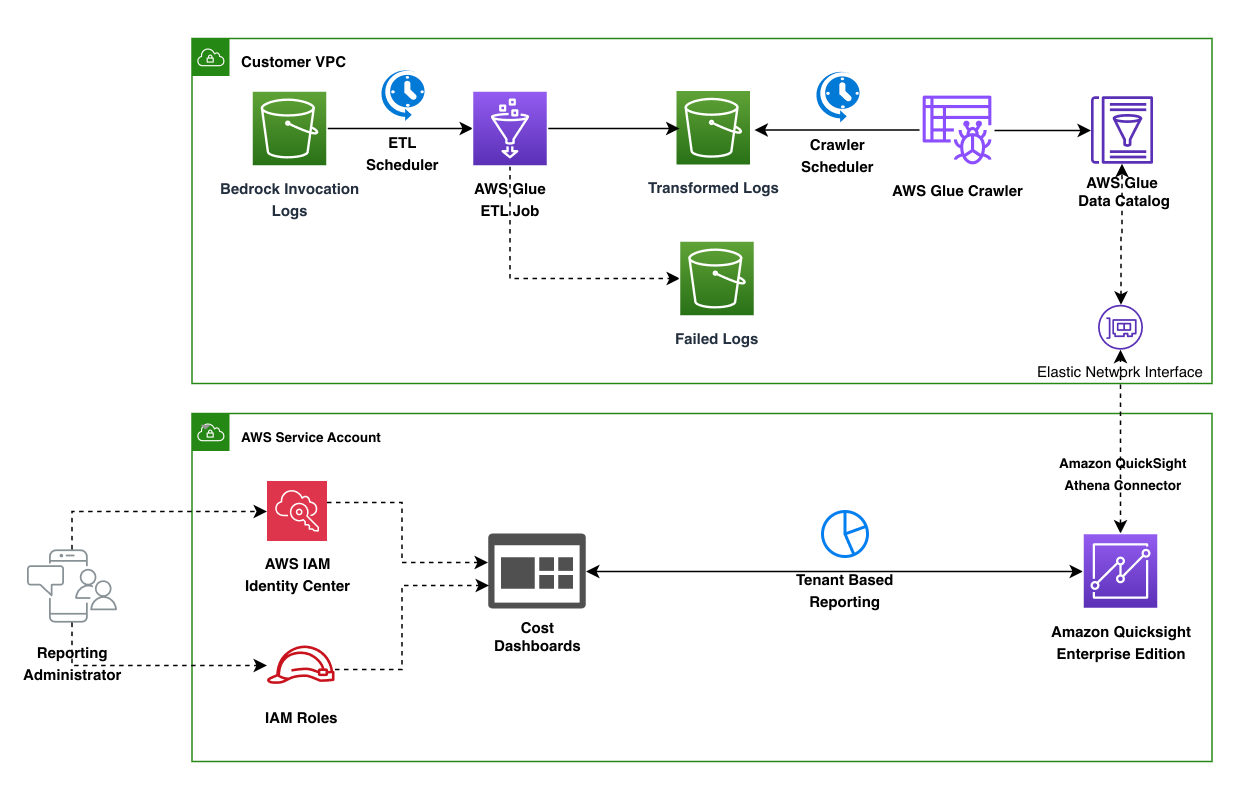
To convert Amazon Bedrock invocation logs with tenant metadata into actionable business intelligence (BI), we’ve designed a scalable data pipeline that processes, transforms, and visualizes this information. The architecture consists of three main components working together to deliver tenant-specific analytics.
The process begins in your customer’s virtual private cloud (VPC), where Amazon Bedrock invocation logs capture each interaction with your AI application. These logs contain valuable information including the requestMetadata parameters you’ve configured to identify tenants, users, and other business contexts.
An ETL scheduler triggers AWS Glue jobs at regular intervals to process these logs. The AWS Glue ETL job extracts the tenant metadata from each log entry, transforms it into a structured format optimized for analysis, and loads the results into a transformed logs bucket. For data quality assurance, records that fail processing are automatically routed to a separate failed logs bucket for troubleshooting.
After the data is transformed, a crawler scheduler activates an AWS Glue crawler to scan the processed logs. The crawler updates the AWS Glue Data Catalog with the latest schema and partition information, making your tenant-specific data immediately discoverable and queryable.
This automated cataloging creates a unified view of tenant interactions across your Amazon Bedrock applications. The data catalog connects to your analytics environment through an elastic network interface, that provides secure access while maintaining network isolation.
Your reporting infrastructure in the Amazon QuickSight account transforms tenant data into actionable insights. Amazon QuickSight Enterprise edition serves as your visualization service and connects to the data catalog through the QuickSight to Amazon Athena connector.
Your reporting administrators can create tenant-based dashboards that show usage patterns, popular queries, and performance metrics segmented by tenant. Cost dashboards provide financial insights into model usage by tenant, helping you understand the economics of your multi-tenant AI application.
Monitoring and analyzing Amazon Bedrock performance metrics
The following Amazon QuickSight dashboard demonstrates how you can visualize your Amazon Bedrock usage data across multiple dimensions. You can examine your usage patterns through four key visualization panels.
Using the Bedrock Usage Summary horizontal bar chart shown in the top left, you can compare token usage across tenant groups. You get clear visibility into each tenant’s consumption levels. The Token Usage by Company pie chart in the top right breaks down token usage distribution by company, showing relative shares among organizations.
Token Usage by Department horizontal bar chart in the bottom left reveals departmental consumption. You can see how different business functions such as Finance, Research, HR, and Sales use Amazon Bedrock services. The Model Distribution graphic in the bottom right displays model distribution metrics with a circular gauge showing complete coverage.
You can filter and drill down into your data using the top filter controls for Year, Month, Day, Tenant, and Model selections. This enables detailed temporal and organizational analysis of your Amazon Bedrock consumption patterns.
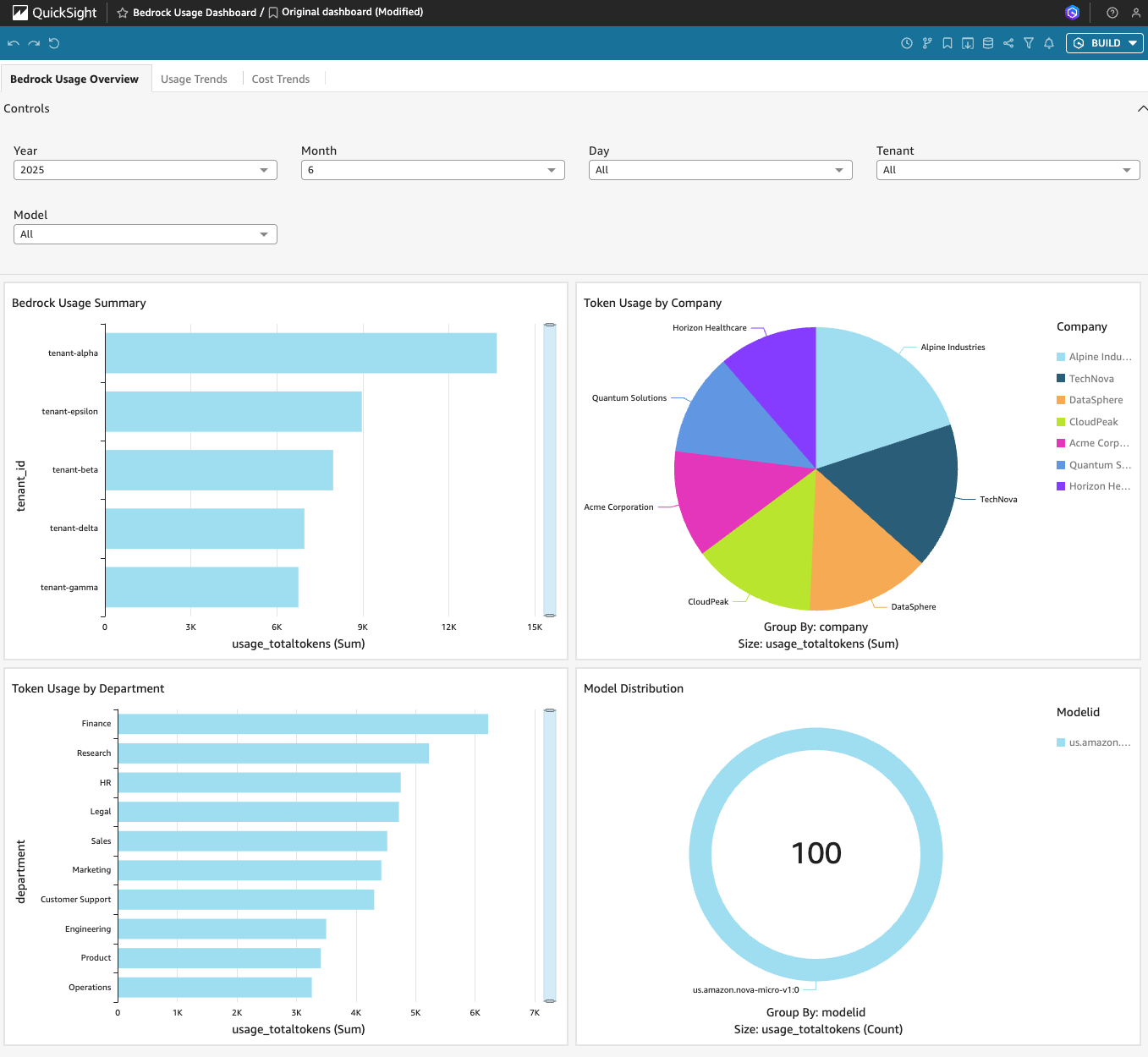
Bedrock Usage Overview QuickSight dashboard
The comprehensive dashboard show in the following image provides vital insights into AWS Amazon Bedrock usage patterns and performance metrics across different environments. This “Usage Trends” visualization suite includes key metrics such as token usage trends, input and output token distribution, latency analysis, and environment-wide usage breakdown.
Using the dashboard, stakeholders can make data-driven decisions about resource allocation, performance optimization, and usage patterns across different deployment stages. With intuitive controls for year, month, day, tenant, and model selection, teams can quickly filter and analyze specific usage scenarios.
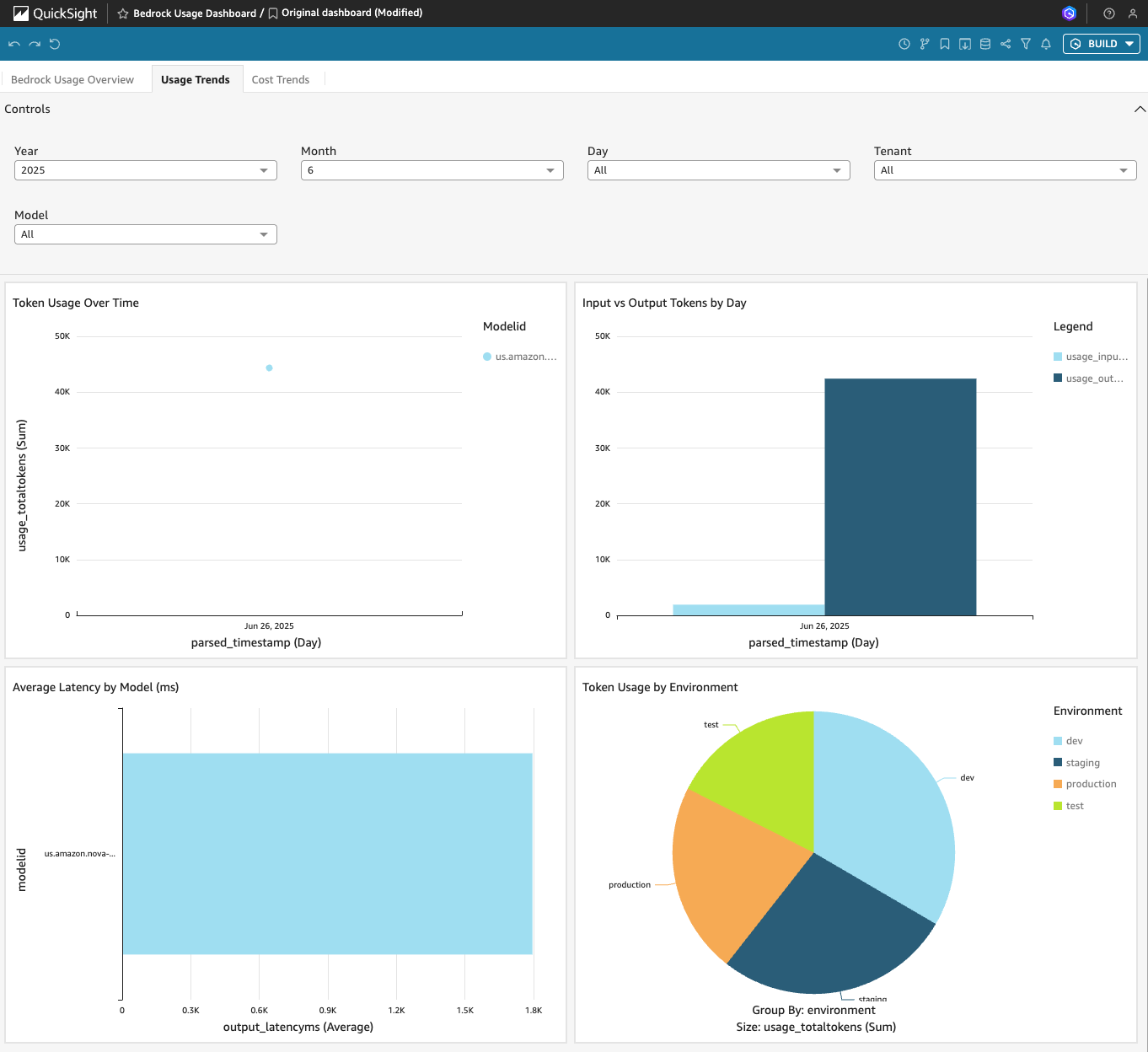
Usage Trends QuickSight Dashboard
Access to these insights is carefully managed through AWS IAM Identity Center and role-based permissions, so tenant data remains protected while still enabling powerful analytics.
By implementing this architecture, you transform basic model invocation logs into a strategic asset. Your business can answer sophisticated questions about tenant behavior, optimize model performance for specific customer segments, and make data-driven decisions about your AI application’s future development—all powered by the metadata you’ve thoughtfully included in your Amazon Bedrock Converse API requests.
Customize the solution
The Converse metadata cost reporting solution provides several customization points to adapt to your specific multi-tenant requirements and business needs. You can modify the ETL process by editing the AWS Glue ETL script at `cdk/glue/bedrock_logs_transform.py` to extract additional metadata fields or transform data according to your tenant structure. Schema definitions can be updated in the corresponding JSON files to accommodate custom tenant attributes or hierarchical organizational data.
For organizations with evolving pricing models, the pricing data stored in `cdk/glue/pricing.csv` can be updated to reflect current Amazon Bedrock costs, including cache read and write pricing. Edit the .csv file and upload it to your transformed data Amazon Simple Storage Service (Amazon S3) bucket, then run the pricing crawler to refresh the data catalog. This makes sure your cost allocation dashboards are accurate as pricing changes.
QuickSight dashboards offer extensive customization capabilities directly through the console interface. You can modify existing visualizations to focus on specific tenant metrics, add filters for departmental or regional views, and create new analytical insights that align with your business reporting requirements. You can save customized versions in the dashboard editor while preserving the original template for future reference.
Clean up
To avoid incurring future charges, delete the resources. Because the solution is deployed using AWS Cloud Development Kit (AWS CDK) cleaning up resources is straightforward. From the command line change into the CDK directory at the root of the converse-metadata-cost-reporting repo and enter the following command to delete the deployed resources. You can also find the instructions in README.md.
Conclusion
Implementing tenant-specific metadata with Amazon Bedrock Converse API creates a powerful foundation for AI application analytics. This approach transforms standard invocation logs into a strategic asset that drives business decisions and improves customer experiences.
The architecture can deliver immediate benefits through automated processing of tenant metadata. You gain visibility into usage patterns across customer segments. You can allocate costs accurately and identify opportunities for model optimization based on tenant-specific needs. For implementation details, refer to the converse-metadata-cost-reporting GitHub repository.
This solution enables measurable business outcomes. Product teams can prioritize features on tenant usage data. Customer success managers can provide personalized guidance using tenant-specific insights. Finance teams can develop more accurate pricing models based on actual usage patterns across different customer segments. As AI applications become increasingly central to business operations, understanding how different tenants interact with your models becomes essential. Implementing the requestMetadata parameter in your Amazon Bedrock Converse API calls today builds the analytics foundation for your future AI strategy. Start small by identifying key tenant identifiers for your metadata, then expand your analytics capabilities as you gather more data. The flexible architecture described here scales with your needs. You can continuously refine your understanding of tenant behavior and deliver increasingly personalized AI experiences.
About the authors
 Praveen Chamarthi brings exceptional expertise to his role as a Senior AI/ML Specialist at Amazon Web Services (AWS), with over two decades in the industry. His passion for machine learning and generative AI, coupled with his specialization in ML inference on Amazon SageMaker, enables him to empower organizations across the Americas to scale and optimize their ML operations. When he’s not advancing ML workloads, Praveen can be found immersed in books or enjoying science fiction films.
Praveen Chamarthi brings exceptional expertise to his role as a Senior AI/ML Specialist at Amazon Web Services (AWS), with over two decades in the industry. His passion for machine learning and generative AI, coupled with his specialization in ML inference on Amazon SageMaker, enables him to empower organizations across the Americas to scale and optimize their ML operations. When he’s not advancing ML workloads, Praveen can be found immersed in books or enjoying science fiction films.
 Srikanth Reddy is a Senior AI/ML Specialist with Amazon Web Services (AWS). He is responsible for providing deep, domain-specific expertise to enterprise customers, helping them use AWS AI and ML capabilities to their fullest potential.
Srikanth Reddy is a Senior AI/ML Specialist with Amazon Web Services (AWS). He is responsible for providing deep, domain-specific expertise to enterprise customers, helping them use AWS AI and ML capabilities to their fullest potential.
 Dhawal Patel is a Principal Machine Learning Architect at Amazon Web Services (AWS). He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and AI. He focuses on deep learning, including natural language processing (NLP) and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at Amazon Web Services (AWS). He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and AI. He focuses on deep learning, including natural language processing (NLP) and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
 Alma Mohapatra is an Enterprise Support Manager helping strategic AI/ML customers optimize their workloads on HPC environments. She guides organizations through performance challenges and infrastructure optimization for LLMs across distributed GPU clusters. Alma translates technical requirements into practical solutions while collaborating with Technical Account Managers to ensure AI/ML initiatives meet business objectives.
Alma Mohapatra is an Enterprise Support Manager helping strategic AI/ML customers optimize their workloads on HPC environments. She guides organizations through performance challenges and infrastructure optimization for LLMs across distributed GPU clusters. Alma translates technical requirements into practical solutions while collaborating with Technical Account Managers to ensure AI/ML initiatives meet business objectives.
 John Boren is a Solutions Architect at AWS GenAI Labs in Seattle where he develops full-stack Generative AI demos. Originally from Alaska, he enjoys hiking, traveling, continuous learning, and fishing.
John Boren is a Solutions Architect at AWS GenAI Labs in Seattle where he develops full-stack Generative AI demos. Originally from Alaska, he enjoys hiking, traveling, continuous learning, and fishing.
 Rahul Sharma is a Senior Specialist Solutions Architect at AWS, helping AWS customers build ML and Generative AI solutions. Prior to joining AWS, Rahul has spent several years in the finance and insurance industries, helping customers build data and analytics platforms.
Rahul Sharma is a Senior Specialist Solutions Architect at AWS, helping AWS customers build ML and Generative AI solutions. Prior to joining AWS, Rahul has spent several years in the finance and insurance industries, helping customers build data and analytics platforms.
")




")

