
{kind=link}
In Part 1 of our series, we established the architectural foundation for an enterprise artificial intelligence and machine learning (AI/ML) configuration with Amazon SageMaker Unified Studio projects. We explored the multi-account structure, project organization, multi-tenancy approaches, and repository strategies needed to create a governed AI development environment.
In this post, we focus on implementing this architecture with step-by-step guidance and reference code. We provide a detailed technical walkthrough that addresses the needs of two critical personas in the AI development lifecycle: the administrator who establishes governance and infrastructure through automated templates, and the data scientist who uses SageMaker Unified Studio for model development without managing the underlying infrastructure.
Our implementation guide covers the complete workflow from project initialization to production deployment, showing how the architectural components we discussed in Part 1 come together to create a seamless, secure, and efficient artificial intelligence operations (AIOps) environment.
Solution overview
In the following architecture, we explore an enterprise-grade machine learning operations implementation using SageMaker Unified Studio and other components that effectively addresses the distinct needs of two critical roles in the machine learning (ML) lifecycle. This approach bridges the gap between infrastructure management and data science, creating a streamlined workflow that maintains continuous integration and delivery (CI/CD) repeatability while accelerating model delivery. The implementation revolves around three personas: administrator, data scientist, and ML engineer.
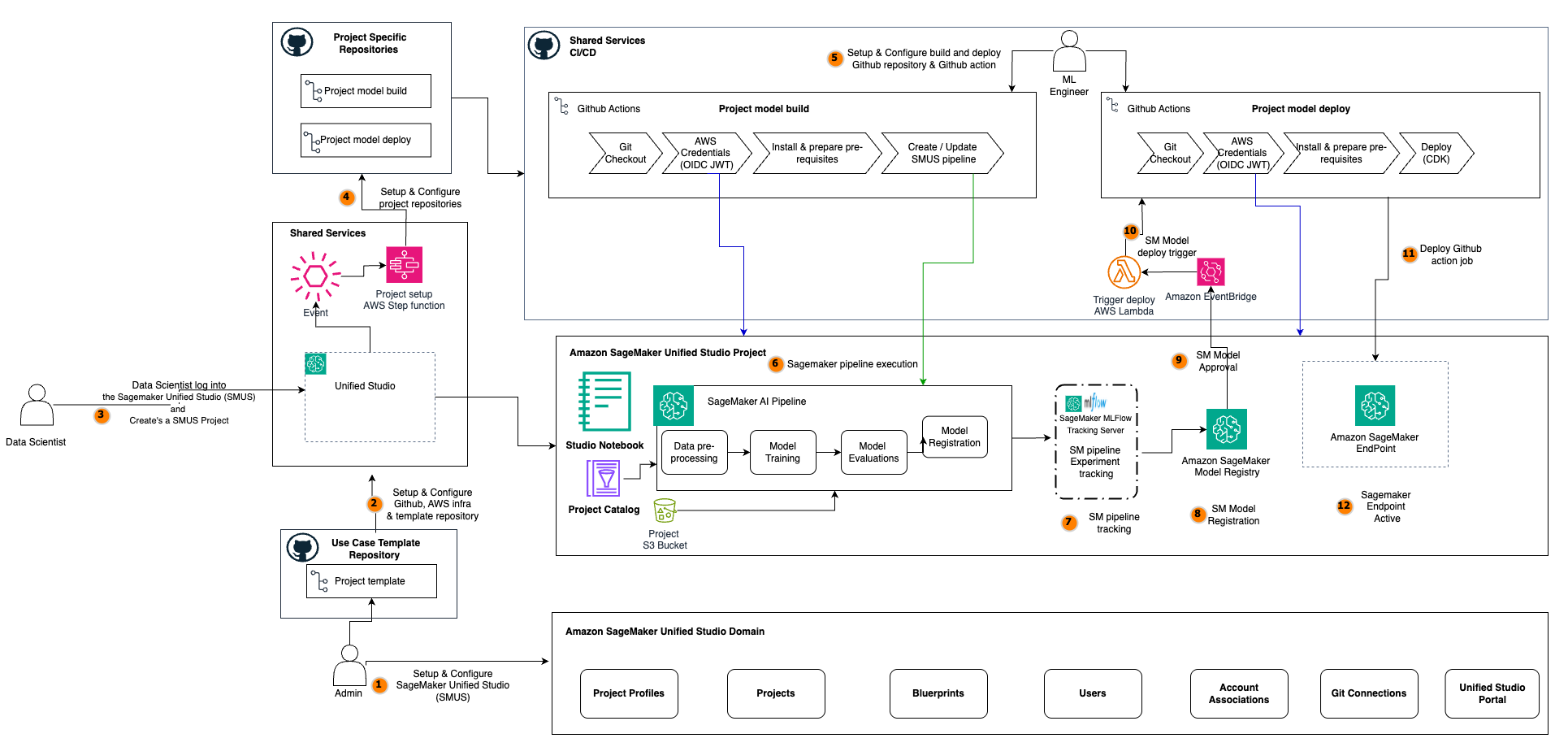
The architecture facilitates a seamless workflow that begins with project initialization and continues through development and deployment phases. Each step is engineered to minimize manual intervention while maximizing traceability, reproducibility, and compliance.
Project initialization phase
The project initialization phase (Steps 1–4) starts with the administrator configuring the SageMaker Unified Studio environment (for more details, see Domains in Amazon SageMaker Unified Studio), setting up the necessary AWS infrastructure, authentication configurations, GitHub connections, and project template repositories.
When the SageMaker Unified Studio foundation is in place, the data scientist logs in to SageMaker Unified Studio and creates a new project. This action triggers a Create Project event that is captured by Amazon EventBridge, which invokes an AWS Lambda function responsible for automating the setup of project-specific resources. As a result, dedicated model build and model deploy repositories are created, configured, and prepopulated with seed code and CI/CD workflows like GitHub action secrets.
Development phase
During the development phase (Steps 5–8), data scientists use the SageMaker Unified Studio project to iteratively build, train, and evaluate ML models. Using SageMaker Unified Studio JupyterLab notebooks, they can write and refine the data preprocessing logic, feature engineering steps, and model training scripts. The SageMaker pipeline, defined in the model build repository, orchestrates the end-to-end workflow. Each pipeline execution is tracked, with metrics and artifacts logged for traceability and experiment management. Upon successful completion, models are registered in Amazon SageMaker Model Registry, where they await validation and approval for deployment.
Deployment phase
In the deployment phase (Steps 9–12), the approval of the model triggers an event that is captured by EventBridge, which invokes a deployment Lambda function.
This function coordinates the execution of the deployment GitHub Actions workflow, which retrieves the latest approved model, applies infrastructure as code (IaC) definitions from the model deploy repository, and provisions or updates the SageMaker endpoint using the AWS Cloud Development Kit (AWS CDK). The deployment pipeline includes checks for configuration validation and rollback procedures, so only validated models are promoted to production. When the endpoint is active, the model is ready to serve predictions, completing the automated journey from development to production deployment.
This architecture follows a comprehensive journey from ML use case project initiation to model deployment, illustrating how you can configure SageMaker Unified Studio projects to create a symbiotic relationship between these personas. The administrator establishes guardrails and automation, and data scientists gain a frictionless experience to rapidly develop, test, and deploy ML models with enterprise-grade governance built in.
AIOps components
The architecture implements a comprehensive AIOps environment that enables seamless operations with governance through three interconnected layers along with the three main personas, as illustrated in the previous diagram. In this section, we describe the layers that are used for describing and grouping the involved workflows for the readers.
AIOps personas
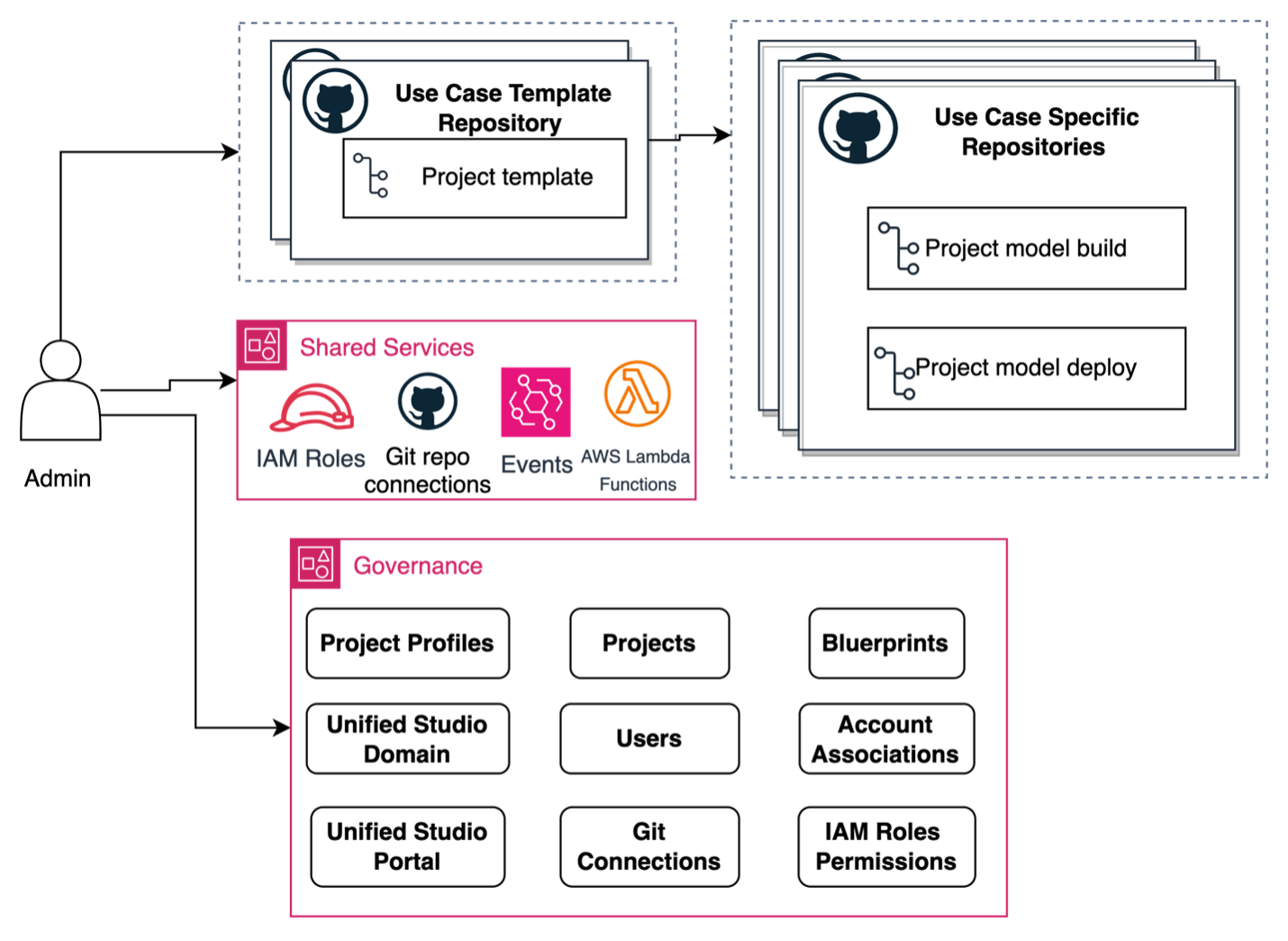
The administrator serves as the foundation builder, setting up the ML project infrastructure according to established organizational guidelines and governance or compliance rules. Their responsibilities include establishing organization-wide templates, security configurations, and infrastructure that enable consistent, secure, and compliant model development. Specifically, they complete the following tasks:
- Create and configure SageMaker Unified Studio domains and other administrative configurations. See the SageMaker Unified Studio Administrator Guide for more information.
- Configure custom ML use case templates for SageMaker Unified Studio ML use cases with GitHub integration.
- Deploy infrastructure, including AWS Step Functions workflows and Lambda functions for automated project setup, which includes use case template selection based on project profile.
- Set up AWS Identity and Access Management (IAM) policies and roles for secure access management.
- Establish CI/CD pipelines (for example, using GitHub Actions) for automated workflows.
- Create standardized model building and deployment patterns.
- Manage access controls across repositories and other SageMaker resources.
The following diagram illustrates the administrator workflow.
The data scientist focuses on extracting value from data through model development without needing to manage infrastructure complexities. With proper AIOps foundations in place, they can efficiently accomplish the following:
- Launch new projects with preconfigured environments and repositories. For more information, see Create a project.
- Develop ML models using the familiar notebook interfaces. For more details, refer to Using the JupyterLab IDE in Amazon SageMaker Unified Studio.
- Register models in SageMaker Model Registry for versioning and governance.
ML engineer perform the following tasks:
- Execute SageMaker pipelines for data preprocessing, training, and evaluation. For more details, see Machine learning.
- Monitor deployment processes and model performance.
Project-specific components
At the core of our architecture are the project-specific repositories that contain the code, configurations, and infrastructure definitions needed for model development and deployment (such as the model build repository and model deployment repository). The model build repository stores the model development code like data preprocessing, feature engineering, and training scripts. The model build code is provided as seed code to help the data science team get started and contains the SageMaker Unified Studio pipeline definitions (for more details, see SageMaker Pipelines) for orchestrating the ML workflow. The following diagram shows this pipeline.
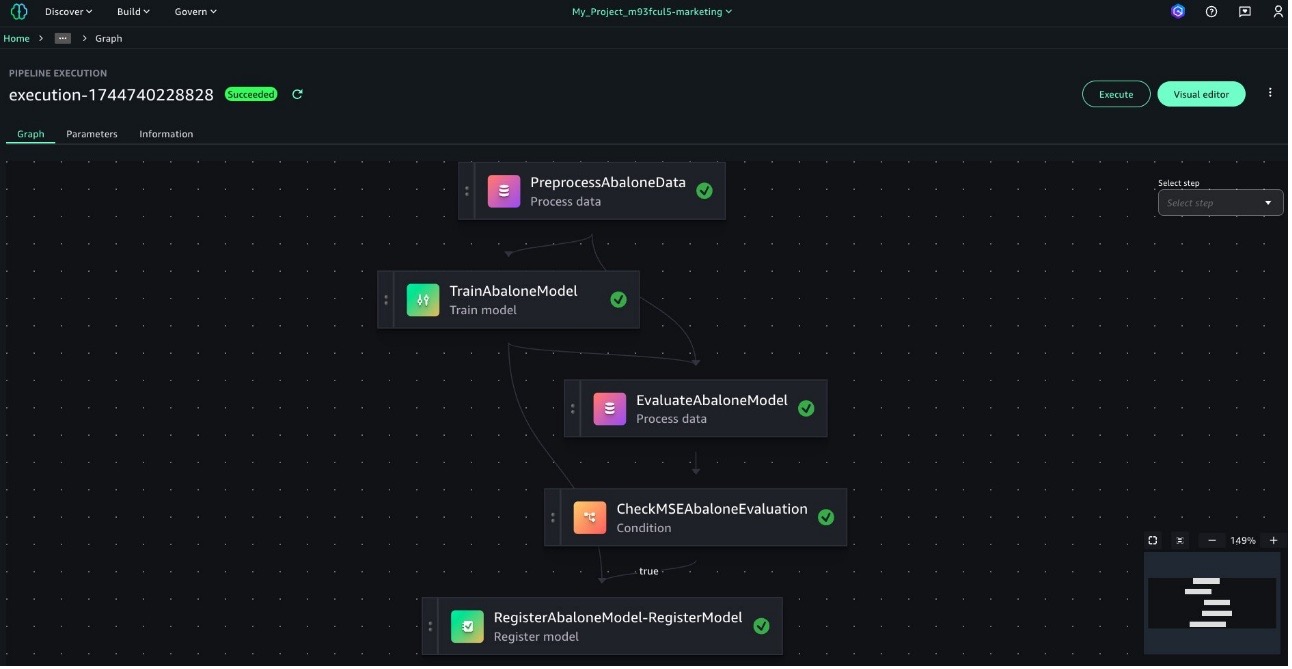
You can extend this pipeline to include organizational best practices like unit tests, integration tests, validation scripts, and GitHub Actions workflow configurations for build automation.
Similarly, the model deploy repository contains IaC for endpoint deployment, defining the endpoint configurations, instance types, and scaling policies. It includes monitoring configurations and alerting thresholds, and stores deployment validation tests and rollback procedures. The following screenshot shows the details of our example repository.
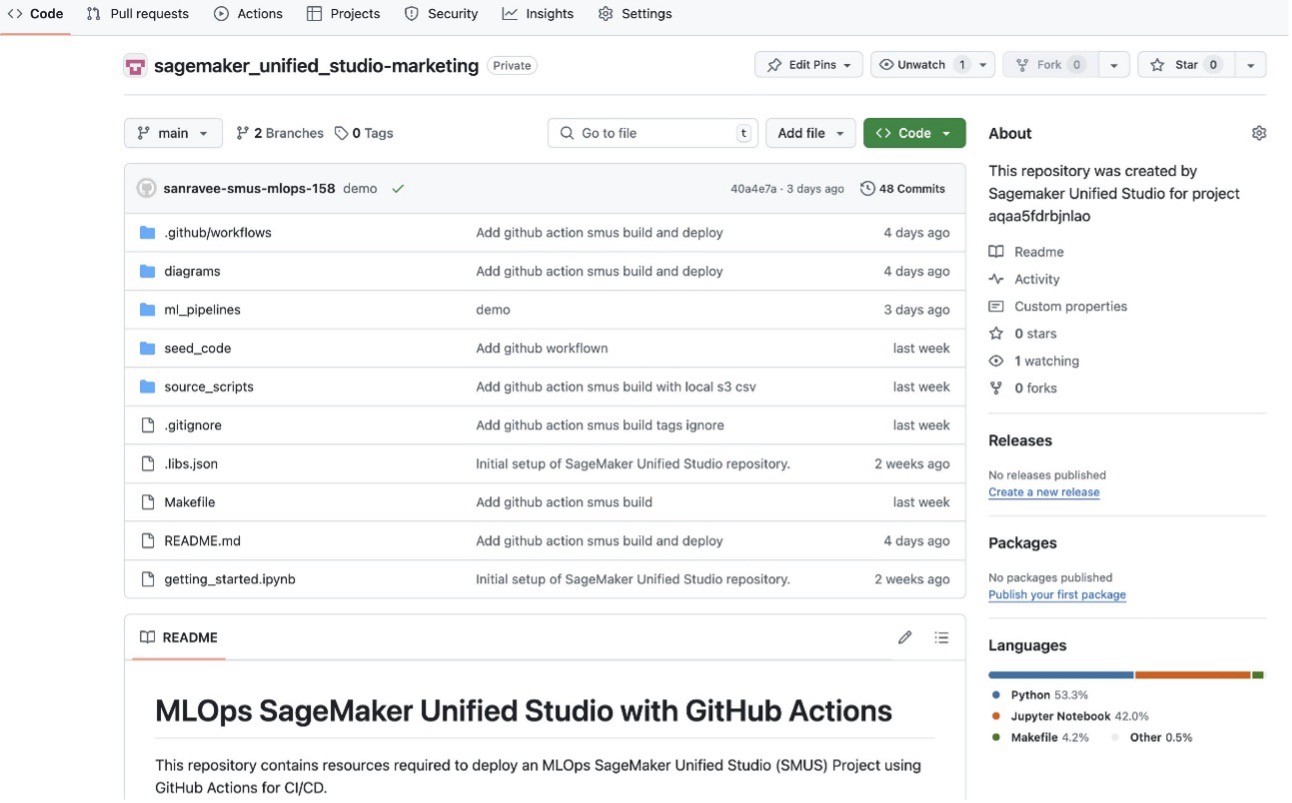
Both repositories are automatically provisioned and seeded with template code when a data scientist initiates a new project through the SageMaker Unified Studio interface.
Shared services layer
The shared services layer provides the automation, orchestration, and integration capabilities that connect the various components. The CI/CD infrastructure provides the GitHub Actions workflows that execute when ML code is pushed to project repositories. You can replace GitHub Actions with your choice of tooling, like Gitlab or others. For this example, GitHub Actions is integrated using AWS credentials through OIDC/JWT for secure repository-to-AWS authentication. For more information about setting up an IAM OpenID Connect (OIDC) identity provider on GitHub, see Configuring OpenID Connect in Amazon Web Services. GitHub Actions build pipelines are used to orchestrate model training with data preprocessing, model training, evaluation, and model registration steps. Similarly, GitHub Actions deployment pipelines handle model selection and endpoint creation.
The event-driven automation is integrated using Amazon EventBridge for event management and workflow orchestration. It manages the SageMaker Unified Studio project setup Lambda function, which responds to project creation events, and the deploy Lambda function, which coordinates model deployment activities.
Development environment
The development environment centers around the SageMaker Unified Studio project space, which provides data scientists with the tools and resources needed for effective model development. SageMaker Unified Studio JupyterLab notebooks or the Code Editor integrated development environment (IDE) enable interactive development and experimentation, and Amazon SageMaker Catalog organizes and manages ML data assets. A SageMaker Unified Studio project Amazon Simple Storage Service (Amazon S3) bucket is used for storing intermediary training data, validation datasets, and model artifacts. Amazon SageMaker Pipelines facilitates the orchestration of data preprocessing, model training, evaluation, and registration steps, making sure the ML workflow is both reproducible and traceable. The following screenshot shows an example of the pipeline.
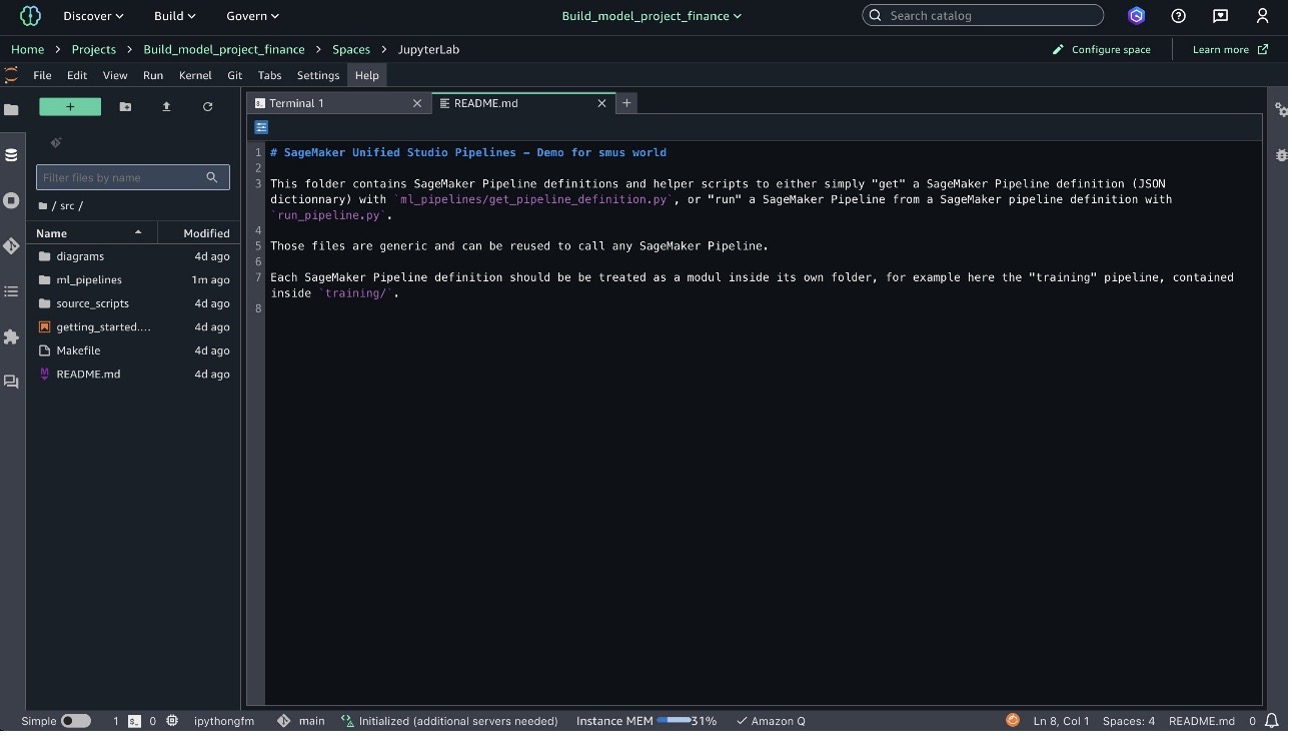
Throughout the workflow, experiment tracking is enabled using SageMaker managed MLflow integration, and model registration is managed through SageMaker Model Registry. After a model is approved, deployment is triggered, and the model is served through a SageMaker endpoint, completing the end-to-end lifecycle from development to production. This architecture provides a scalable, secure, and efficient foundation for ML model development and deployment, maintaining strong governance and control while enabling rapid innovation and collaboration between administrators and data scientists.
Security and governance features
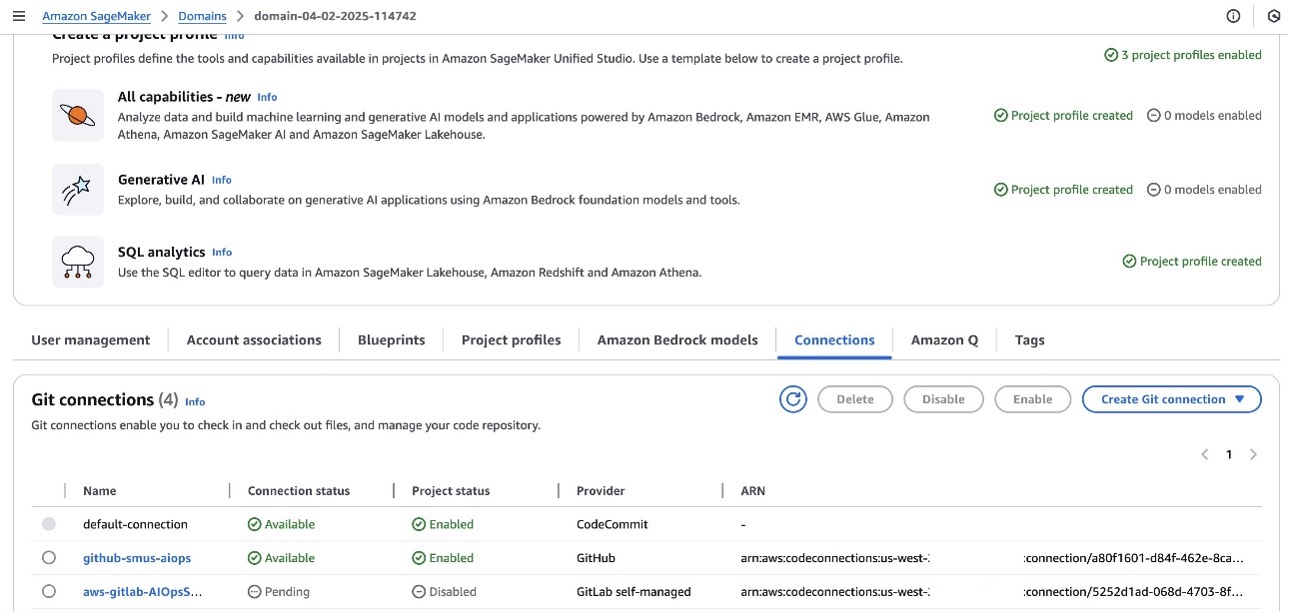
Security and governance are embedded throughout the architecture to maintain compliance with organizational policies and regulatory requirements. Role-based access control is enforced using IAM, clearly separating administrative duties from data science activities. Code and configuration changes are tracked through version-controlled repositories, providing a comprehensive audit trail. Automated CI/CD pipelines incorporate security checks and validation steps, reducing the risk of misconfigurations or unauthorized changes. Centralized governance is maintained through the SageMaker Unified Studio domain project profile, which governs on-demand project configurations.
Solution code
You can follow and execute the full code from the GitHub repository. You will find detailed instructions in the repository readme documentation for setup, prerequisites, and execution steps.
Set up a project with a template
Before diving into the setup process, let’s understand two key concepts in SageMaker Unified Studio: project profiles and projects.
Project profiles define the template configurations for projects in your SageMaker Unified Studio domains. A project profile is a collection of environment blueprints that configure project data and compute assets and determine which capabilities are available to project users. Only domain administrators can create and manage these project profiles, maintaining organizational control over project configurations. For more information about project profiles, see Project profiles in Amazon SageMaker Unified Studio.
Projects in SageMaker Unified Studio are containers where users organize their ML development work. Each project provides a collaboration space through source control repositories and creates permission boundaries for project artifacts and resources. Projects are created using templates defined in the project profile, which controls the tools and capabilities available within the project. For more information about project, see Projects.
As described earlier in this post, the required infrastructure for project automation must be deployed in your AWS account before data scientists can create projects. After administrators have configured the SageMaker Unified Studio domain, established project templates, and deployed the Step Functions and Lambda functions responsible for project automation, the project creation process can begin.
When a data scientist creates a new project in SageMaker Unified Studio, they select from available project templates defined in the project profile and configure the GitHub integration by selecting the Git connection and choosing to create a new repository and branch. SageMaker Unified Studio then initiates project creation based on the parameters defined during project creation. This project creation process generates a CreateProject API call that is logged in AWS CloudTrail. An EventBridge rule monitors these CloudTrail logs and triggers the pre-deployed Step Functions workflow when it detects the CreateProject event. The workflow waits for SageMaker Unified Studio to complete the initial project creation, then retrieves the project template ID and Git repository details from the event payload.
The following diagram illustrates the Step Functions workflow.
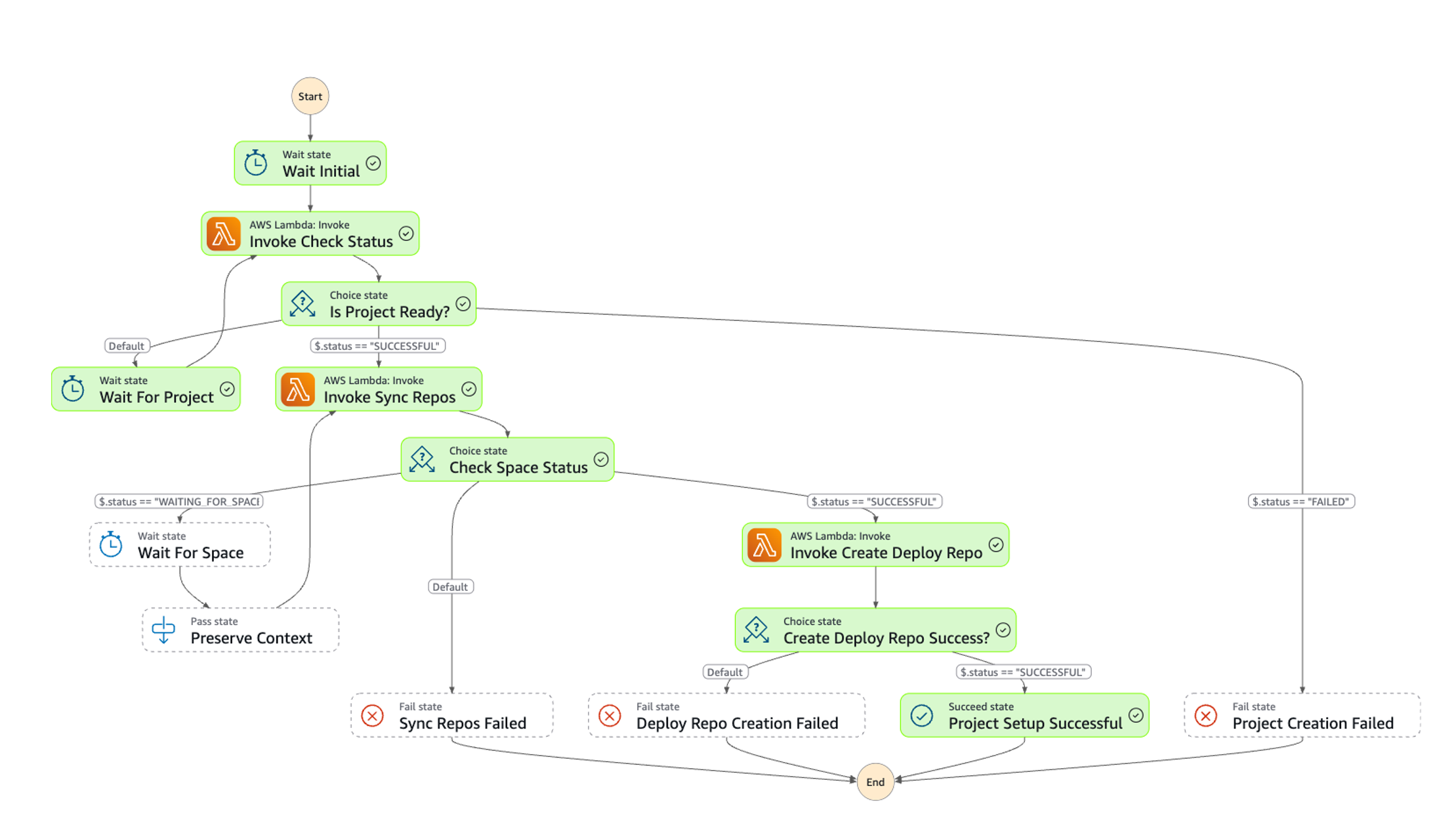
The Step Functions workflow makes API calls to the Amazon DataZone client to get the project profile name. SageMaker uses Amazon DataZone to manage underlying components of SageMaker Unified Studio projects. Based on the project template name from the event, it identifies and fetches the corresponding seed code from the source Git repository. For example, if the project template name is regression, the workflow locates and retrieves the regression-specific code from the source repository and pushes it to the newly created build repository. The workflow also creates and configures the required GitHub secrets for CI/CD pipeline operations.
Next, the workflow creates a deployment repository using the naming format projectid-domainid-deploy-repo. It copies the template-specific deployment code from the source Git repository to this new repository. Administrators can modify this naming convention by updating the code associated with the deploy repository creation.
The workflow is complete when the initial deployment is finished, providing a fully configured development environment aligned with the selected project template.
This automation provides a consistent project setup while maintaining organizational standards. The project creation process configures two repositories with automated CI/CD workflows for model building and deployment, as illustrated in the following screenshot.

Access the SageMaker Catalog dataset in the SageMaker pipeline
SageMaker Catalog provides a streamlined mechanism for discovering, accessing, and using enterprise data assets within your ML pipelines. Before accessing datasets in SageMaker pipelines, data scientists must subscribe to datasets through SageMaker Catalog. This subscription process creates the necessary permissions and resource links to make the data accessible within the project boundary. Refer to Request subscription to assets in Amazon SageMaker Unified Studio to request subscription to a dataset in SageMaker Catalog.
The following diagram illustrates this workflow.
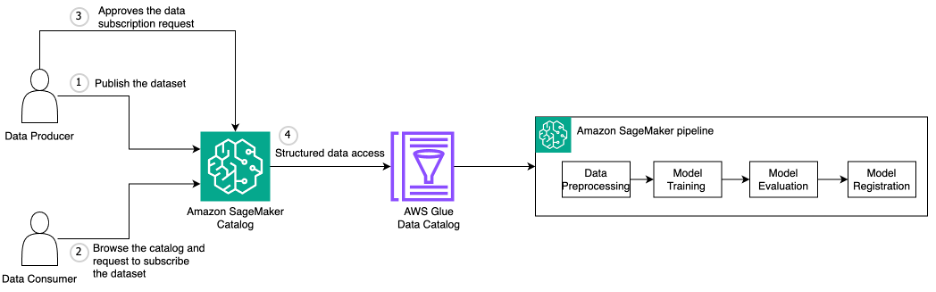
After the datasets are successfully subscribed, they can be accessed within the project by SageMaker Pipelines using AWS Glue Data Catalog integration for structured data published as AWS Glue tables. This approach offers advantages like SQL-based querying capabilities for pre-training data filtering, schema validation, and support for partitioned datasets. SageMaker Catalog handles the permission mapping between your project and the subscribed datasets. If you need access to unstructured data that isn’t managed through AWS Glue tables, you can leverage the S3 Object collections feature supported in SageMaker Catalog as described in the documentation.
After you configure data access, the next step is to integrate the data processing step into the pipeline. This step includes logic to read the dataset, perform required preprocessing, and save the processed data for subsequent steps in the pipeline, such as model training. After the pipeline is defined with these steps, it can be executed and monitored using SageMaker Unified Studio. You can navigate to the ML Pipelines section to view the status of each step, including the data processing step.
Run the model build and deploy CI/CD pipelines
The automation of ML workflows through CI/CD pipelines is crucial for maintaining consistent and reliable model development and deployment processes. In our implementation, we use GitHub Actions to create two distinct pipelines: one for model building and another for deployment. Both repositories come configured with the SageMaker Unified Studio project creation event. You can reconfigure this setup and architecture to function with your preferred CI/CD tooling, such as Gitlab.
Model build pipeline
The model build pipeline automatically triggers when code changes are pushed to the main branch or pull requests are created. For more details, see Performing Git operations.
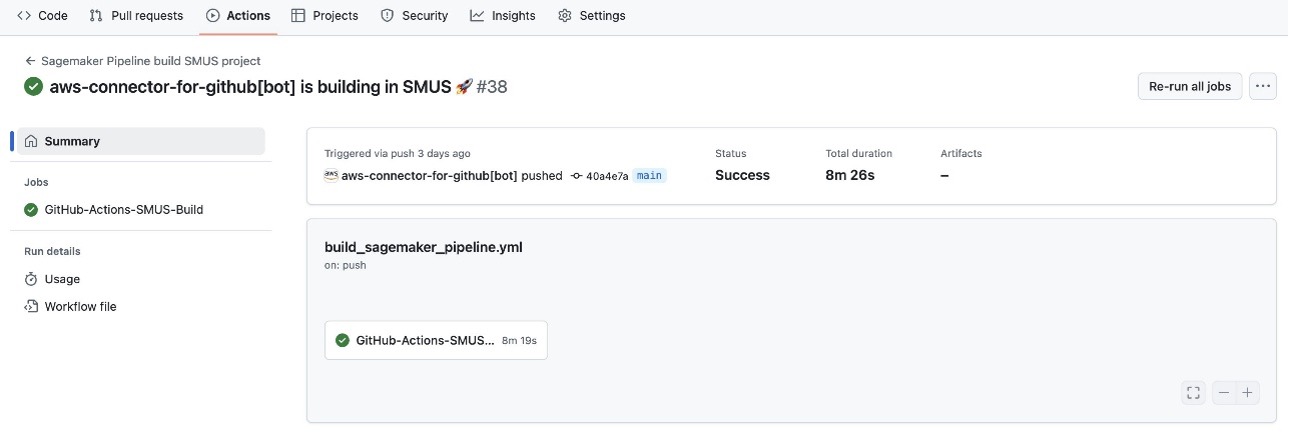
This pipeline uses AWS OIDC GitHub authentication for secure, token-based access to AWS services, alleviating the need to store long-term credentials in GitHub. Upon activation, the pipeline executes a series of steps, including code checkout, environment setup, dependency installation, and SageMaker pipeline updates.
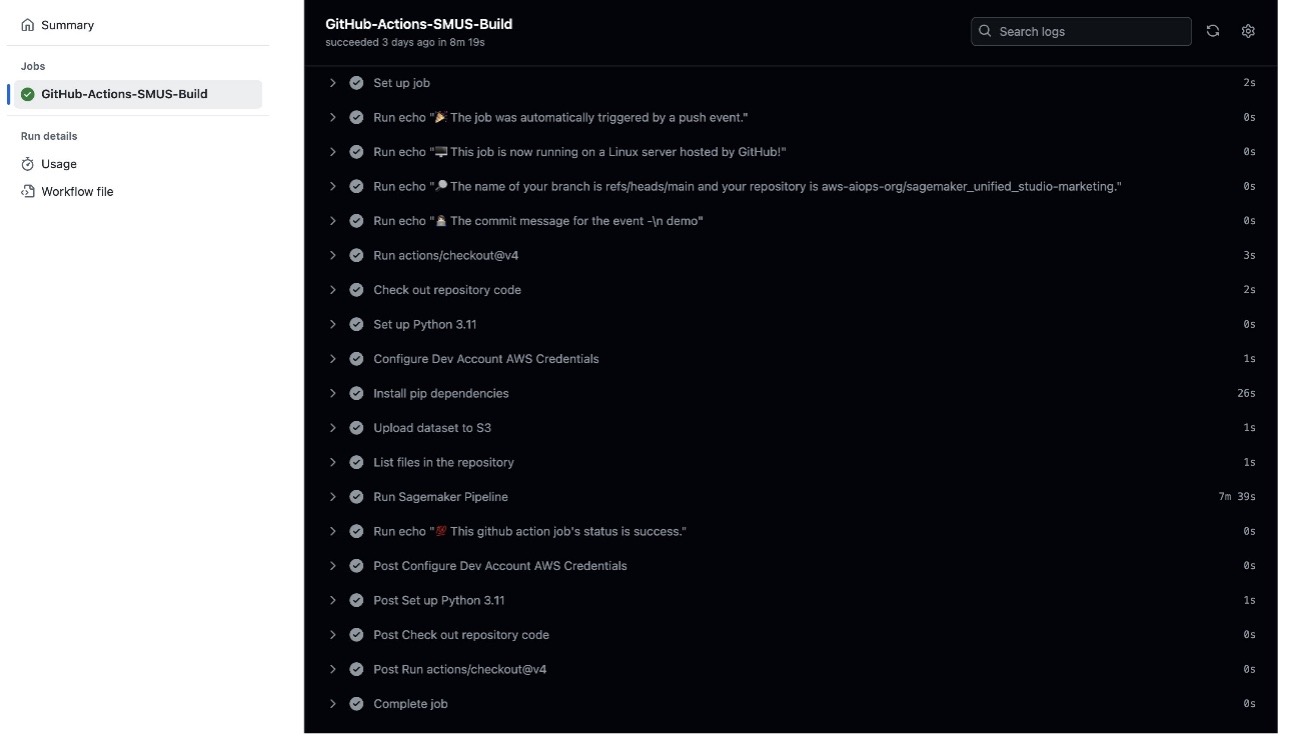
The build process validates the ML pipeline definition and makes sure the components are properly configured before initiating the training process.
Model deployment pipeline
Similarly for model deployment, we’ve implemented a separate pipeline that activates either through manual triggers or automatically when a model receives approval in SageMaker Model Registry. This deployment pipeline handles the creation and updating of SageMaker endpoints, managing model versions, and configuring staging and production environments. It includes error handling with automatic rollback capabilities using AWS CDK code and logging to Amazon CloudWatch through the AWS CloudFormation stack.
The deployment process can be altered to further suit your requirements with scenarios where additional model deployment steps and workflows are needed before serving a model on the endpoint.
Both pipelines follow IaC principles, with modifications version-controlled in Git repositories. This approach provides transparency, reproducibility, and proper change management. The pipeline definitions include:
- Specific IAM roles with least-privilege access
- Environment-specific configurations
- Resource provisioning scripts
For teams adopting this setup, we recommend the following best practices:
- Maintain separate roles and permissions for build and deploy pipelines. See Security best practices in IAM for more information.
- Implement comprehensive testing at each stage.
- Use environment-specific configurations through GitHub secrets and variables.
- Enable detailed logging and monitoring.
- Regularly audit and update pipeline configurations.
This CI/CD implementation creates a streamlined, secure, and maintainable AIOps workflow that supports both rapid development and stable production deployments. The automation reduces manual intervention, minimizes errors, and accelerates the model development lifecycle while maintaining security and governance requirements.
Validate project deployment
After you create a project using SageMaker Unified Studio project templates, validate the successful setup of all components:
- Your GitHub organization should contain two new repositories with the template-specific seed code and GitHub Actions workflows for automated model build and deployment pipelines.
- In the SageMaker Unified Studio UI, on the Build menu, choose ML Pipelines under Orchestration to view your pipeline executions. You can verify the execution status and results of each pipeline run.
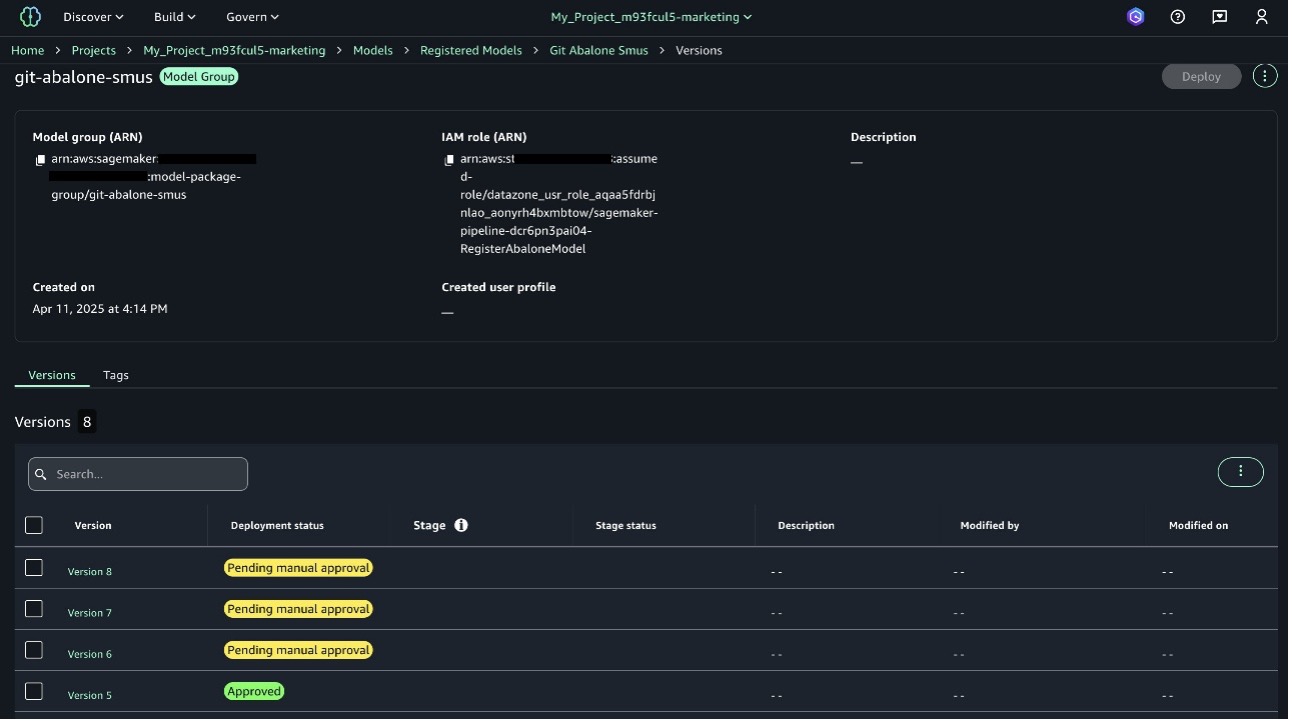
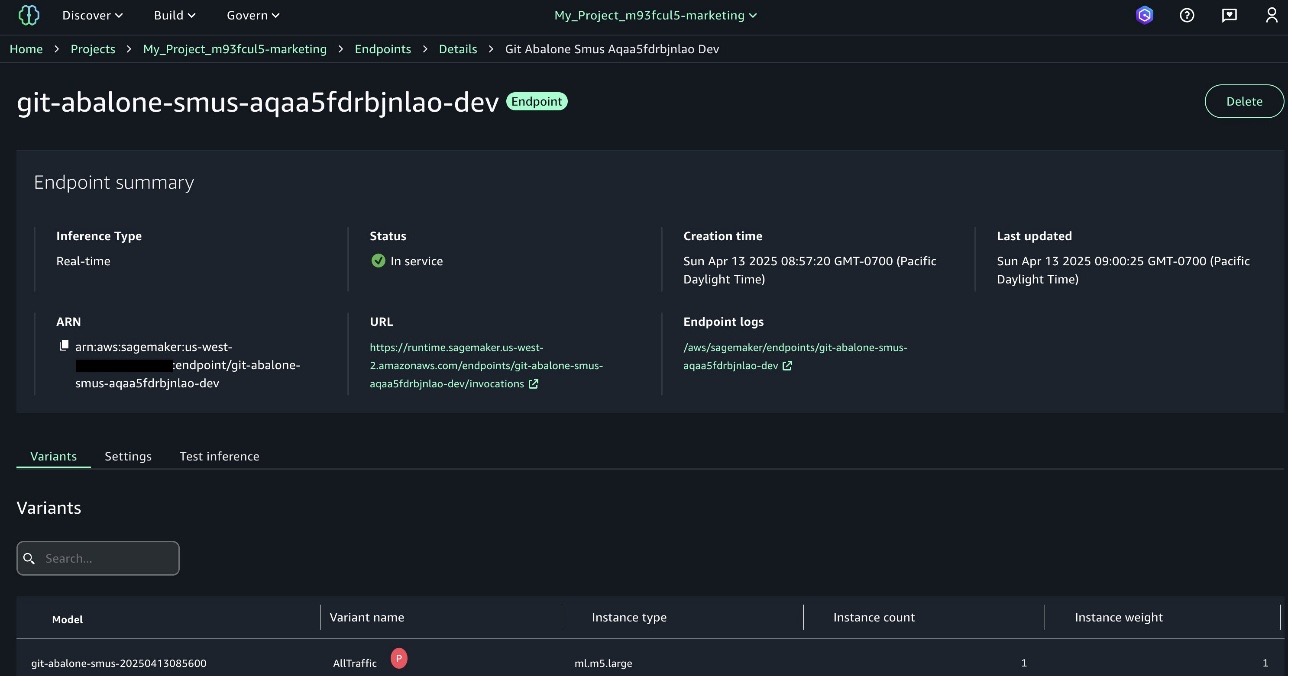
- The SageMaker Unified Studio Model Registry in the AI OPS section contains your registered model package with status and version information.
- Finally, verify the model inference endpoint by navigating to the SageMaker Unified Studio Model Registry. On the Build menu, choose Inference endpoints under Machine Learning & Generative AI to view your endpoint name and its In Service status.
These validations confirm successful project creation, model training, and deployment through the automated workflows.
Clean up
To avoid unnecessary costs, remember to delete resources such as the SageMaker MLflow tracking server, SageMaker pipelines and SageMaker endpoints.
Conclusion
In this two-part series, we provided a comprehensive framework for setting up and automating AIOps workflows with SageMaker Unified Studio projects. In Part 1, we established the architectural foundation, and in this post, we presented the practical implementation that addresses various concerns, including multi-tenancy, security, governance, scalability, repeatability, and reliability.
We demonstrated how to scale your AIOps for build and deployment pipelines across a large number of projects. The automated workflows for project setup, model building, and deployment reduce manual bottlenecks while providing consistent application of best practices across your AI workloads.
The AIOps solution we’ve shared, along with implementation code, provides a good starting point for your own AIOps implementation. This approach can help organizations efficiently operationalize their AI initiatives, reducing the time from idea to production while maintaining appropriate security and governance controls.
The flexibility of the framework accommodates various use cases, from traditional ML models to generative AI applications, making it a valuable foundation for any organization’s AI journey. We encourage you to experiment with the architectures presented in this post, scale it to multiple projects and accounts, adapt it to your specific needs, and share your feedback as you build your AIOps capabilities on AWS. See Getting Started documentation and the solution code for this blog from the GitHub repository to start building your ML use cases.
About the Authors
 Ram Vittal is a GenAI/ML Specialist SA at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure, scalable, reliable GenAI/ML solutions to help customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides motorcycle and walks with his sheep-a-doodle!
Ram Vittal is a GenAI/ML Specialist SA at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure, scalable, reliable GenAI/ML solutions to help customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides motorcycle and walks with his sheep-a-doodle!
 Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customer through their AIOps journey across model training, GenAI applications like Agents, and scaling GenAI use-cases. He also focuses on Go-To-Market strategies helping AWS build and align products to solve industry challenges in the GenerativeAI space. You can find Sandeep on LinkedIn.
Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customer through their AIOps journey across model training, GenAI applications like Agents, and scaling GenAI use-cases. He also focuses on Go-To-Market strategies helping AWS build and align products to solve industry challenges in the GenerativeAI space. You can find Sandeep on LinkedIn.
 Koushik Konjeti is a Senior Solutions Architect at Amazon Web Services. He has a passion for aligning architectural guidance with customer goals, ensuring solutions are tailored to their unique requirements. Outside of work, he enjoys playing cricket and tennis.
Koushik Konjeti is a Senior Solutions Architect at Amazon Web Services. He has a passion for aligning architectural guidance with customer goals, ensuring solutions are tailored to their unique requirements. Outside of work, he enjoys playing cricket and tennis.
 Vaibhav Sabharwal is a Senior Solutions Architect with Amazon Web Services (AWS) based out of New York. He is passionate about learning new cloud technologies and assisting customers in building cloud adoption strategies, designing innovative solutions, and driving operational excellence. As a member of the Financial Services Technical Field Community at AWS, he actively contributes to the collaborative efforts within the industry.
Vaibhav Sabharwal is a Senior Solutions Architect with Amazon Web Services (AWS) based out of New York. He is passionate about learning new cloud technologies and assisting customers in building cloud adoption strategies, designing innovative solutions, and driving operational excellence. As a member of the Financial Services Technical Field Community at AWS, he actively contributes to the collaborative efforts within the industry.