
{kind=link}
Large language models (LLMs) have become increasingly prevalent across both consumer and enterprise applications. However, their tendency to “hallucinate” information and deliver incorrect answers with seeming confidence has created a trust problem. Think of LLMs as you would a human expert: we typically trust experts who can back up their claims with references and walk us through their reasoning process. The same principle applies to LLMs – they become more trustworthy when they can demonstrate their thought process and cite reliable sources for their information. Fortunately, with proper prompting, LLMs can be instructed to provide these citations, making their outputs more verifiable and dependable.
In this post, we demonstrate how to prompt Amazon Nova understanding models to cite sources in responses. Further, we will also walk through how we can evaluate the responses (and citations) for accuracy.
What are citations and why are they useful?
Citations are references to sources that indicate where specific information, ideas, or concepts in a work originated. Citations play a crucial role in addressing the following issues, enhancing the credibility, usability, and ethical grounding of LLM-based applications.
- Ensuring factual accuracy: LLMs are prone to “hallucinations,” where they generate plausible but incorrect information. Citations allow users to verify claims by tracing them back to reliable sources, improving factual correctness and reducing misinformation risks.
- Building trust and transparency: Citations foster trust in AI-generated content so users can cross-check information and understand its origins. This transparency is vital for applications in research, healthcare, law, and education.
- Supporting ethical practices: Citing sources ensures proper attribution to original authors, respecting intellectual property rights and scholarly contributions. It prevents plagiarism and promotes ethical AI use.
- Enhancing usability: Citations improve user experience by providing a pathway to explore related materials. Features like inline citations or bibliographies help users find relevant sources easily.
- Addressing Limitations of LLMs: LLMs often fabricate references due to their inability to access real-time data or remember training sources accurately. Retrieval augmented generation (RAG) systems and citation tools mitigate this issue by grounding responses in external data.
- Professional and academic standards: In academic contexts, citations are indispensable for replicating research methods and validating findings. AI-generated outputs must adhere to these standards to maintain scholarly integrity.
Citations with Amazon Nova models
Amazon Nova, launched in Dec 2024, is a new generation of foundation models that deliver frontier intelligence and industry leading price performance, available on Amazon Bedrock. Amazon Nova models include four understanding models (Nova Micro, Nova Lite, Nova Pro and Nova Premier), two creative content generation models (Nova Canvas and Nova Reel), and one speech-to-speech model (Nova Sonic). Through seamless integration with Amazon Bedrock, developers can build and scale generative AI applications with Amazon Nova foundation models.
Citations for the Amazon Nova understanding models can be achieved by crafting prompts where we instruct the model to cite its sources and indicate the response format. To illustrate this, we’ve picked an example where we ask questions to Nova Pro about Amazon shareholder letters. We will include the shareholder letter in the prompt as context and ask Nova Pro to answer questions and include citations from the letter(s).
Here’s an example prompt that we constructed for Amazon Nova Pro following best practices for prompt engineering for Amazon Nova.
Note the output format that we included in the prompt to distinguish the actual answers from the citations.
System prompt
User Prompt
Here’s the response from Nova Pro for the above prompt
As you can see Nova Pro is following our instructions and providing the answer along with the citations. We’ve verified the quotes are indeed present in the 2009 shareholder letter.
Here’s another user prompt (with the same system prompt as above) along with the model’s response
User Prompt:
Model response
Evaluating citations
While citations are good, it’s important to evaluate that the model is following our instructions and including the citation verbatim from the context and not making up the citations.
To evaluate the citations at scale, we used another LLM to judge the responses from Amazon Nova Pro. We used the LLM-as-a-judge technique in Amazon Bedrock evaluations and evaluated 10 different prompts. LLM-as-a-judge on Amazon Bedrock Model Evaluation provides a comprehensive, end-to-end solution for assessing and optimizing AI model performance. This automated process uses the power of LLMs to evaluate responses across multiple metric categories (such as correctness, completeness, harmfulness, helpfulness and more) offering insights that can significantly improve your AI applications.
We prepared the input dataset for evaluation. The input dataset is a jsonl file containing our prompts that we want to evaluate. Each line in the jsonl file must include key-value pairs. Here are the required and optional fields for the input dataset:
- prompt (required): This key indicates the input for various tasks. It can be used for general text generation where the model needs to provide a response, question-answering tasks where the model must answer a specific question, text summarization tasks where the model needs to summarize a given text, or classification tasks where the model must categorize the provided text.
- referenceResponse (optional – used for specific metrics with ground truth): This key contains the ground truth or correct response. It serves as the reference point against which the model’s responses will be evaluated if it is provided.
- category (optional): This key is used to generate evaluation scores reported by category, helping organize and segment evaluation results for better analysis.
Here’s an example jsonl file for evaluating our prompts (full jsonl file not shown for brevity).
We then started a model evaluation job using the Bedrock API with Anthropic Claude 3.5 Sonnet v1 as the evaluator/judge model. We have open sourced our code on the AWS Samples GitHub.
We evaluated our prompts and responses for the following built-in metrics
- Helpfulness
- Correctness
- Professional style and tone
- Faithfulness
- Completeness
- Coherence
- Following instructions
- Relevance
- Readability
- Harmfuless
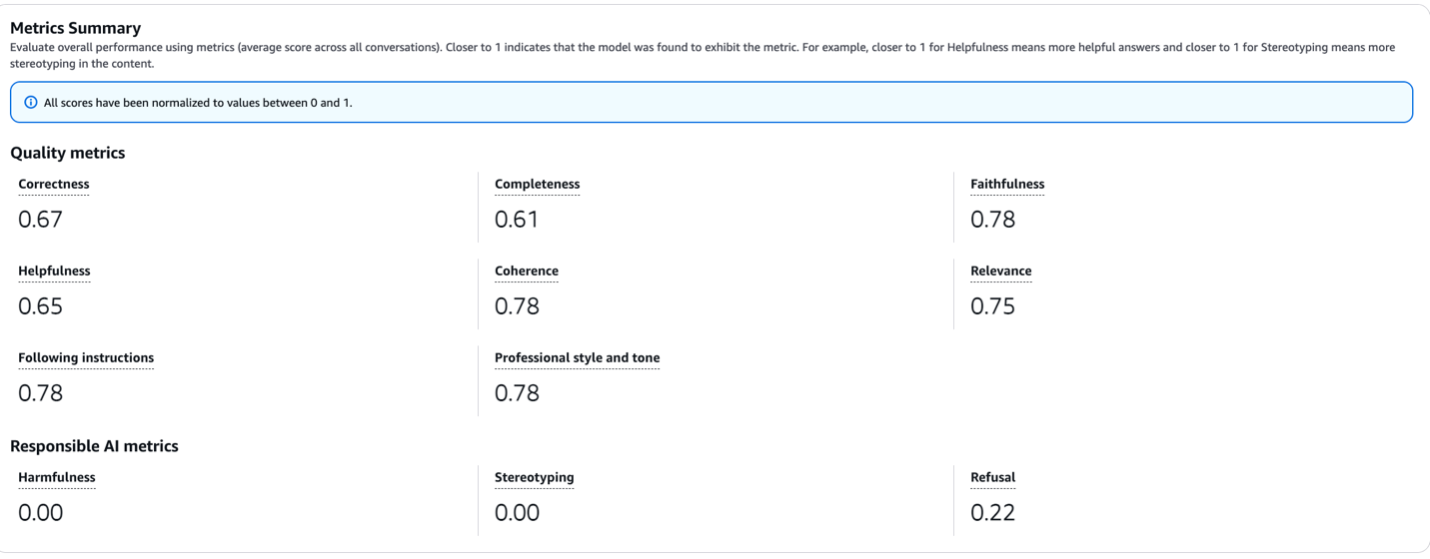
Here’s the result summary of our evaluation. As you can see, Nova Pro had a 0.78 score on coherence and faithfulness and 0.67 on correctness. The high scores indicate that Nova Pro’s responses were holistic, useful, complete and accurate while being coherent as evaluated by Claude 3.5 Sonnet.
Conclusion
In this post, we walked through how we can prompt Amazon Nova understanding models to cite sources from the context through simple instructions. Amazon Nova’s capability to include citations in its responses demonstrates a practical approach to implementing this feature, showcasing how simple instructions can lead to more reliable and trustworthy AI interactions. The evaluation of these citations, using an LLM-as-a-judge technique, further underscores the importance of assessing the quality and faithfulness of AI-generated responses. To learn more about prompting for Amazon Nova models please visit this prompt library. You can learn more about Amazon Bedrock evaluations on the AWS website.
About the authors
 Sunita Koppar is a Senior Specialist Solutions Architect in Generative AI and Machine Learning at AWS, where she partners with customers across diverse industries to design solutions, build proof-of-concepts, and drive measurable business outcomes. Beyond her professional role, she is deeply passionate about learning and teaching Sanskrit, actively engaging with student communities to help them upskill and grow.
Sunita Koppar is a Senior Specialist Solutions Architect in Generative AI and Machine Learning at AWS, where she partners with customers across diverse industries to design solutions, build proof-of-concepts, and drive measurable business outcomes. Beyond her professional role, she is deeply passionate about learning and teaching Sanskrit, actively engaging with student communities to help them upskill and grow.
 Veda Raman is a Senior Specialist Solutions Architect for generative AI and machine learning at AWS. Veda works with customers to help them architect efficient, secure, and scalable machine learning applications. Veda specializes in generative AI services like Amazon Bedrock and Amazon SageMaker.
Veda Raman is a Senior Specialist Solutions Architect for generative AI and machine learning at AWS. Veda works with customers to help them architect efficient, secure, and scalable machine learning applications. Veda specializes in generative AI services like Amazon Bedrock and Amazon SageMaker.