
{kind=link}
This post was written with Avdhesh Paliwal of Oldcastle APG.
Oldcastle APG, one of the largest global networks of manufacturers in the architectural products industry, was grappling with an inefficient and labor-intensive process for handling proof of delivery (POD) documents, known as ship tickets. The company was processing 100,000–300,000 ship tickets per month across more than 200 facilities. Their existing optical character recognition (OCR) system was unreliable, requiring constant maintenance and manual intervention. It could only accurately read 30–40% of the documents, leading to significant time and resource expenditure.
This post explores how Oldcastle partnered with AWS to transform their document processing workflow using Amazon Bedrock with Amazon Textract. We discuss how Oldcastle overcame the limitations of their previous OCR solution to automate the processing of hundreds of thousands of POD documents each month, dramatically improving accuracy while reducing manual effort. This solution demonstrates a practical, scalable approach that can be adapted to your specific needs, such as similar challenges addressing document processing or using generative AI for business process optimization.
Challenges with document processing
The primary challenge for Oldcastle was to find a solution that could accomplish the following:
- Accurately process a high volume of ship tickets (PODs) with minimal human intervention
- Scale to handle 200,000–300,000 documents per month
- Handle inconsistent inputs like rotated pages and variable formatting
- Improve the accuracy of data extraction from the current 30–40% to a much higher rate
- Add new capabilities like signature validation on PODs
- Provide real-time visibility into outstanding PODs and deliveries
Additionally, Oldcastle needed a solution for processing supplier invoices and matching them against purchase orders, which presented similar challenges due to varying document formats.The existing process required dispatchers at more than 200 facilities to spend 4–5 hours daily manually processing ship tickets. This consumed valuable human resources and led to delays in processing and potential errors in data entry. The IT team was burdened with constant maintenance and development efforts to keep the unreliable OCR system functioning.
Solution overview
AWS Solutions Architects worked closely with Oldcastle engineers to build a solution addressing these challenges. The end-to-end workflow uses Amazon Simple Email Service (Amazon SES) to receive ship tickets, which are sent directly from drivers in the field. The system processes emails at scale using an event-based architecture centered on Amazon S3 Event Notifications. The workflow sends ship ticket documents to an automatic scaling compute job orchestrator. Documents are processed with the following steps:
- The system sends PDF files to Amazon Textract using the Start Document Analysis API with Layout and Signature features.
- Amazon Textract results are processed by an AWS Lambda microservice. This microservice resolves rotation issues with page text and generates a collection of pages of markdown representation of the text.
- The markdown is passed to Amazon Bedrock, which efficiently extracts key values from the markdown text.
- The orchestrator saves the results to their Amazon Relational Database Service (Amazon RDS) for PostgreSQL database.
The following diagram illustrates the solution architecture.
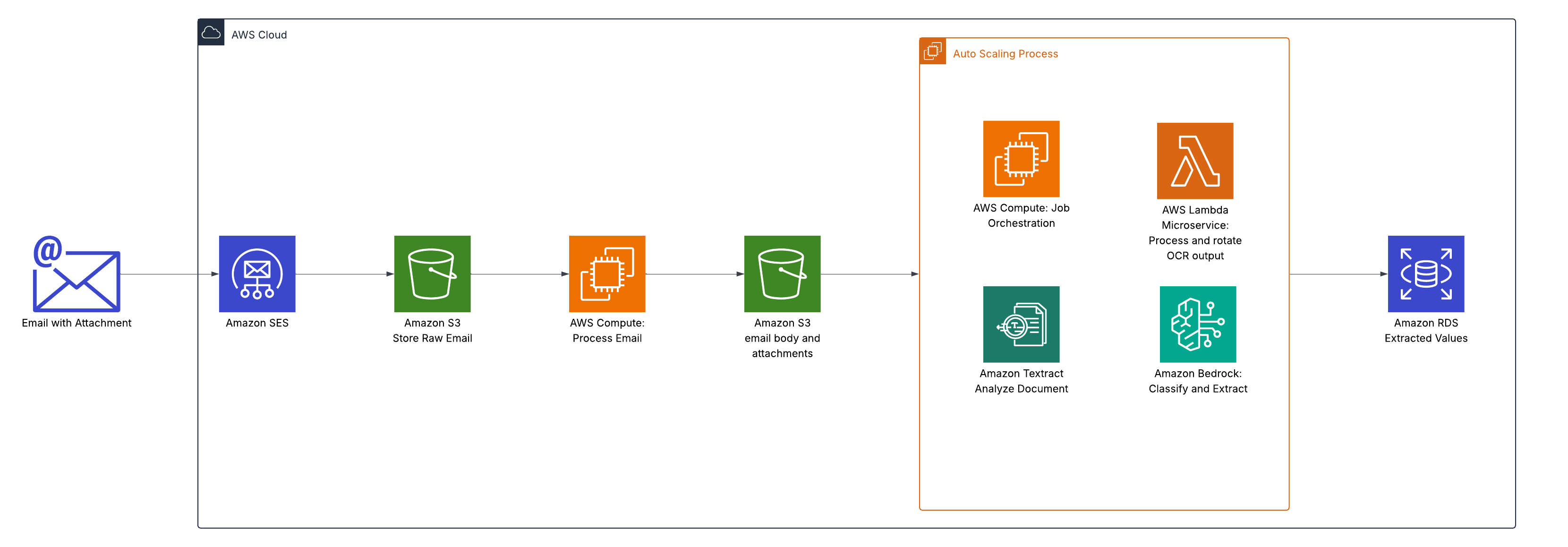
In this architecture, Amazon Textract is an effective solution to handle large PDF files at scale. The output of Amazon Textract contains the necessary geometries used to calculate rotation and fix layout issues before generating markdown. Quality markdown layouts are critical for Amazon Bedrock in identifying the right key-value pairs from the content. We further optimized cost by extracting only the data needed to limit output tokens and by using Amazon Bedrock batch processing to get the lowest token cost. Amazon Bedrock was used for its cost-effectiveness and ability to process format shipping tickets where the fields that need to be extracted are the same.
Results
The implementation using this architecture on AWS brought numerous benefits to Oldcastle:
- Business process improvement – The solution accomplished the following:
- Alleviated the need for manual processing of ship tickets at each facility
- Automated document processing with minimal human intervention
- Improved accuracy and reliability of data extraction
- Enhanced ability to validate signatures and reject incomplete documents
- Provided real-time visibility into outstanding PODs and deliveries
- Productivity gains – Oldcastle saw the following benefits:
- Significantly fewer human hours were spent on manual data entry and document processing
- Staff had more time for more value-added activities
- The IT team benefited from reduced development and maintenance efforts
- Scalability and performance – The team experienced the following performance gains:
- They seamlessly scaled from processing a few thousand documents to 200,000–300,000 documents per month
- The team observed no performance issues with increased volume
- User satisfaction – The solution improved user sentiment in several ways:
- High user confidence in the new system due to its accuracy and reliability
- Positive feedback from business users on the ease of use and effectiveness
- Cost-effective – With this approach, Oldcastle can process documents at less than $0.04 per page
Conclusion
With the success of the AWS implementation, Oldcastle is exploring potential expansion to other use cases such as AP invoice processing, W9 form validation, and automated document approval workflows. This strategic move towards AI-powered document processing is positioning Oldcastle for improved efficiency and scalability in its operations.
Review your current manual document processing procedures and identify where intelligent document processing can help you automate these workflows for your business.
For further exploration and learning, we recommend checking out the following resources:
- Intelligent Document Processing on AWS
- Automate document processing with Amazon Bedrock Prompt Flows
- Intelligent Document Processing with Generative AI
About the authors
 Erik Cordsen is a Solutions Architect at AWS serving customers in Georgia. He is passionate about applying cloud technologies and ML to solve real life problems. When he is not designing cloud solutions, Erik enjoys travel, cooking, and cycling.
Erik Cordsen is a Solutions Architect at AWS serving customers in Georgia. He is passionate about applying cloud technologies and ML to solve real life problems. When he is not designing cloud solutions, Erik enjoys travel, cooking, and cycling.
 Sourabh Jain is a Senior Solutions Architect with over 8 years of experience developing cloud solutions that drive better business outcomes for organizations worldwide. He specializes in architecting and implementing robust cloud software solutions, with extensive experience working alongside global Fortune 500 teams across diverse time zones and cultures.
Sourabh Jain is a Senior Solutions Architect with over 8 years of experience developing cloud solutions that drive better business outcomes for organizations worldwide. He specializes in architecting and implementing robust cloud software solutions, with extensive experience working alongside global Fortune 500 teams across diverse time zones and cultures.
 Avdhesh Paliwal is an accomplished Application Architect at Oldcastle APG with 29 years of extensive ERP experience. His expertise spans Manufacturing, Supply Chain, and Human Resources modules, with a proven track record of designing and implementing enterprise solutions that drive operational efficiency and business value.
Avdhesh Paliwal is an accomplished Application Architect at Oldcastle APG with 29 years of extensive ERP experience. His expertise spans Manufacturing, Supply Chain, and Human Resources modules, with a proven track record of designing and implementing enterprise solutions that drive operational efficiency and business value.