
{kind=link}
Organizations building custom machine learning (ML) models often have specialized requirements that standard platforms can’t accommodate. For example, healthcare companies need specific environments to protect patient data while meeting HIPAA compliance, financial institutions require specific hardware configurations to optimize proprietary trading algorithms, and research teams need flexibility to experiment with cutting-edge techniques using custom frameworks. These specialized needs drive organizations to build custom training environments that give them control over hardware selection, software versions, and security configurations.
These custom environments provide the necessary flexibility, but they create significant challenges for ML lifecycle management. Organizations typically try to solve these problems by building additional custom tools, and some teams piece together various open source solutions. These approaches further increase operational costs and require engineering resources that could be better used elsewhere.
AWS Deep Learning Containers (DLCs) and managed MLflow on Amazon SageMaker AI offer a powerful solution that addresses both needs. DLCs provide preconfigured Docker containers with frameworks like TensorFlow and PyTorch, including NVIDIA CUDA drivers for GPU support. DLCs are optimized for performance on AWS, regularly maintained to include the latest framework versions and patches, and designed to integrate seamlessly with AWS services for training and inference. AWS Deep Learning AMIs (DLAMIs) are preconfigured Amazon Machine Images (AMIs) for Amazon Elastic Compute Cloud (Amazon EC2) instances. DLAMIs come with popular deep learning frameworks like PyTorch and TensorFlow, and are available for CPU-based instances and high-powered GPU-accelerated instances. They include NVIDIA CUDA, cuDNN, and other necessary tools, with AWS managing the updates of DLAMIs. Together, DLAMIs and DLCs provide ML practitioners with the infrastructure and tools to accelerate deep learning in the cloud at scale.
SageMaker managed MLflow delivers comprehensive lifecycle management with one-line automatic logging, enhanced comparison capabilities, and complete lineage tracking. As a fully managed service on SageMaker AI, it alleviates the operational burden of maintaining tracking infrastructure.
In this post, we show how to integrate AWS DLCs with MLflow to create a solution that balances infrastructure control with robust ML governance. We walk through a functional setup that your team can use to meet your specialized requirements while significantly reducing the time and resources needed for ML lifecycle management.
Solution overview
In this section, we describe the architecture and AWS services used to integrate AWS DLCs with SageMaker managed MLflow to implement the solution.The solution uses several AWS services together to create a scalable environment for ML development:
- AWS DLCs provide preconfigured Docker images with optimized ML frameworks
- SageMaker managed MLflow introduces enhanced model registry capabilities with fine-grained access controls and adds generative AI support through specialized tracking for LLM experiments and prompt management
- Amazon Elastic Container Registry (Amazon ECR) stores and manages container images
- Amazon Simple Storage Service (Amazon S3) stores input and output artifacts
- Amazon EC2 runs the AWS DLCs
For this use case, you will develop a TensorFlow neural network model for abalone age prediction with integrated SageMaker managed MLflow tracking code. Next, you will pull an optimized TensorFlow training container from the AWS public ECR repository and configure an EC2 instance with access to the MLflow tracking server. You will then execute the training process within the DLC while storing model artifacts in Amazon S3 and logging experiment results to MLflow. Finally, you will view and compare experiment results in the MLflow UI to evaluate model performance.
The following diagram that shows the interaction between various AWS services, AWS DLCs, and SageMaker managed MLflow for the solution.
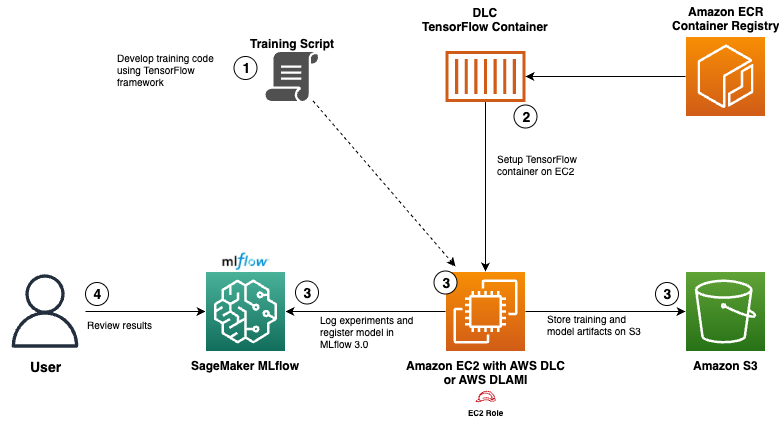
The workflow consists of the following steps:
- Develop a TensorFlow neural network model for abalone age prediction. Integrate SageMaker managed MLflow tracking within the model code to log parameters, metrics, and artifacts.
- Pull an optimized TensorFlow training container from the AWS public ECR repository. Configure Amazon EC2 and DLAMI with access to the MLflow tracking server using an AWS Identity and Access Management (IAM) role for EC2.
- Execute the training process within the DLC running on Amazon EC2, store model artifacts in Amazon S3, and log all experiment results and register model in MLflow.
- Compare experiment results through the MLflow UI.
Prerequisites
To follow along with this walkthrough, make sure you have the following prerequisites:
- An AWS account with billing enabled.
- An EC2 instance (t3.large or larger) running Ubuntu 20.4 or later with at least 20 GB of available disk space for Docker images and containers.
- Docker (latest) installed on the EC2 instance.
- The AWS Command Line Interface (AWS CLI) version 2.0 or later.
- An IAM role with permissions for the following:
- Amazon EC2 to talk to SageMaker managed MLflow.
- Amazon ECR to pull the TensorFlow container.
- SageMaker managed MLflow to track experiments and register models.
- An Amazon SageMaker Studio domain. To create a domain, refer to Guide to getting set up with Amazon SageMaker AI. Add the
sagemaker-mlflow:AccessUIpermission to the SageMaker execution role created. This permission makes it possible to navigate to MLflow from the SageMaker Studio console. - A SageMaker managed MLflow tracking server set up in SageMaker AI.
- Internet access from the EC2 instance to download the abalone dataset.
- The GitHub repository cloned to your EC2 instance.
Deploy the solution
Detailed step-by-step instructions are available in the accompanying GitHub repository’s README file. The walkthrough covers the entire workflow—from provisioning infrastructure and setting up permissions to executing your first training job with comprehensive experiment tracking.
Analyze experiment results
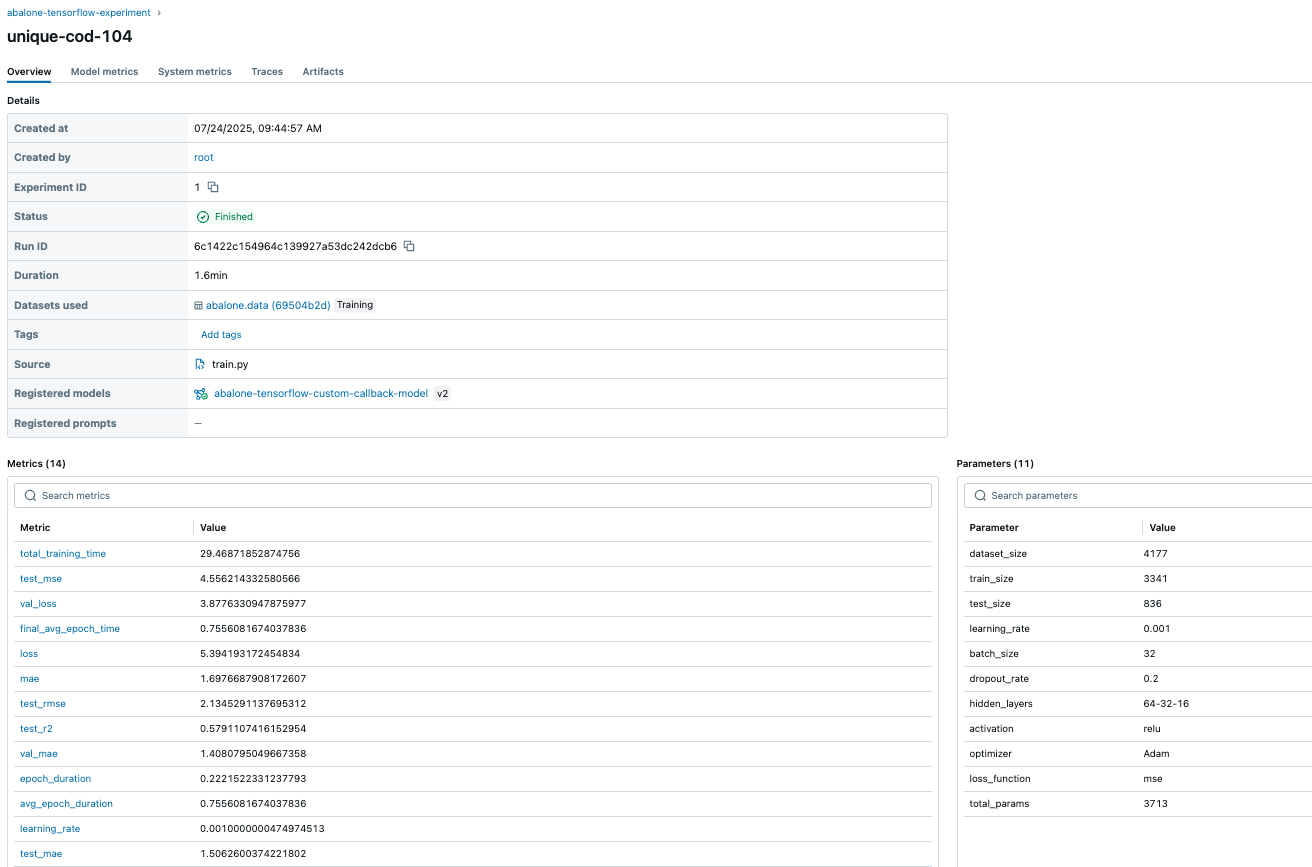
After you’ve implemented the solution following the steps in the README file, you can access and analyze your experiment results. The following screenshots demonstrate how SageMaker managed MLflow provides comprehensive experiment tracking, model governance, and auditability for your deep learning workloads. When training is complete, all experiment metrics, parameters, and artifacts are automatically captured in MLflow, providing a central location to track and compare your model development journey. The following screenshot shows the experiment abalone-tensorflow-experiment with a run named unique-cod-104. This dashboard gives you a complete overview of all experiment runs, so you can compare different approaches and model iterations at a glance.

The following screenshot shows the detailed information for run unique-cod-104, including the registered model abalone-tensorflow-custom-callback-model (version v2). This view provides critical information about model provenance, showing exactly which experiment run produced which model version, which is a key component of model governance.
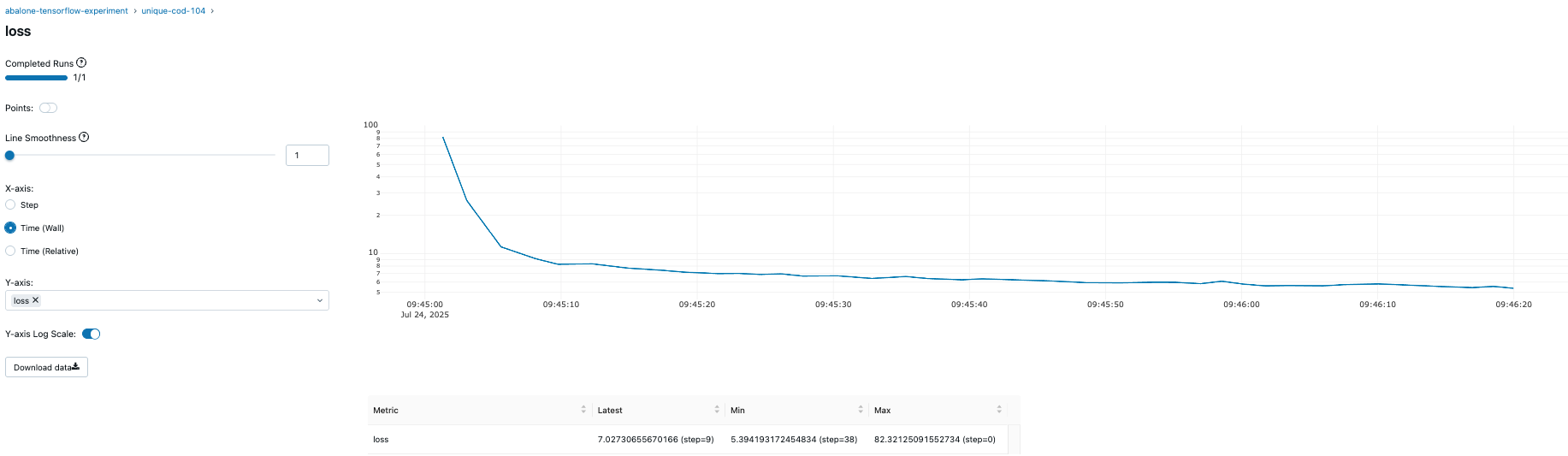
The following visualization tracks the training loss across epochs, captured using a custom callback. Such metrics help you understand model convergence patterns and evaluate training performance, giving insights into potential optimization opportunities.
The registered models view illustrated in the following screenshot shows how abalone-tensorflow-custom-callback-model is tracked in the model registry. This integration enables versioning, model lifecycle management, and deployment tracking.
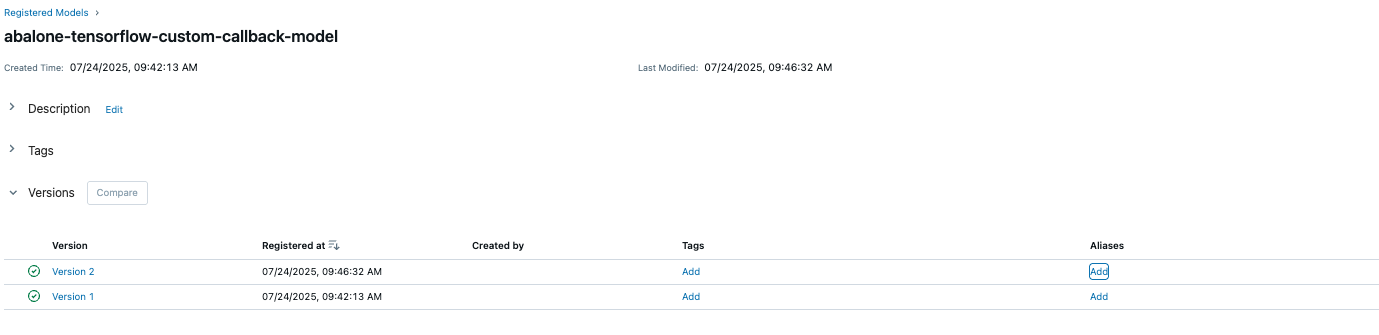
The following screenshot illustrates one of the solution’s most powerful governance features. When logging a model with mlflow.tensorflow.log_model() using the registered_model_name parameter, the model is automatically registered in the Amazon SageMaker Model Registry. This creates full traceability from experiment to deployed model, establishing an audit trail that connects your training runs directly to production models.
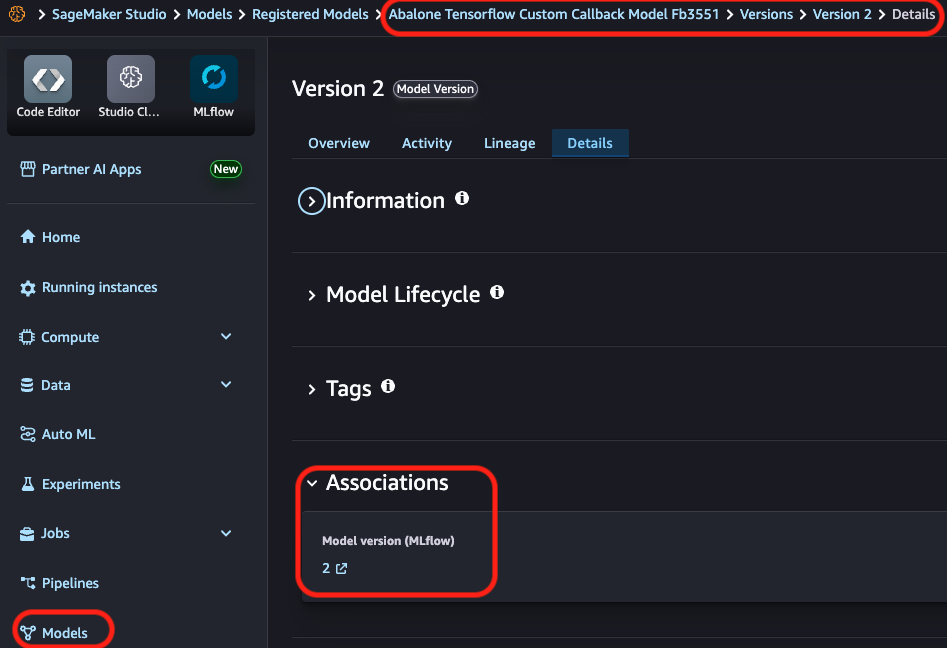
This seamless integration between your custom training environments and SageMaker governance tools helps you maintain visibility and compliance throughout your ML lifecycle.
The model artifacts are automatically uploaded to Amazon S3 after training completion, as illustrated in the following screenshot. This organized storage structure makes sure all model components including weights, configurations, and associated metadata are securely preserved and accessible through a standardized path.
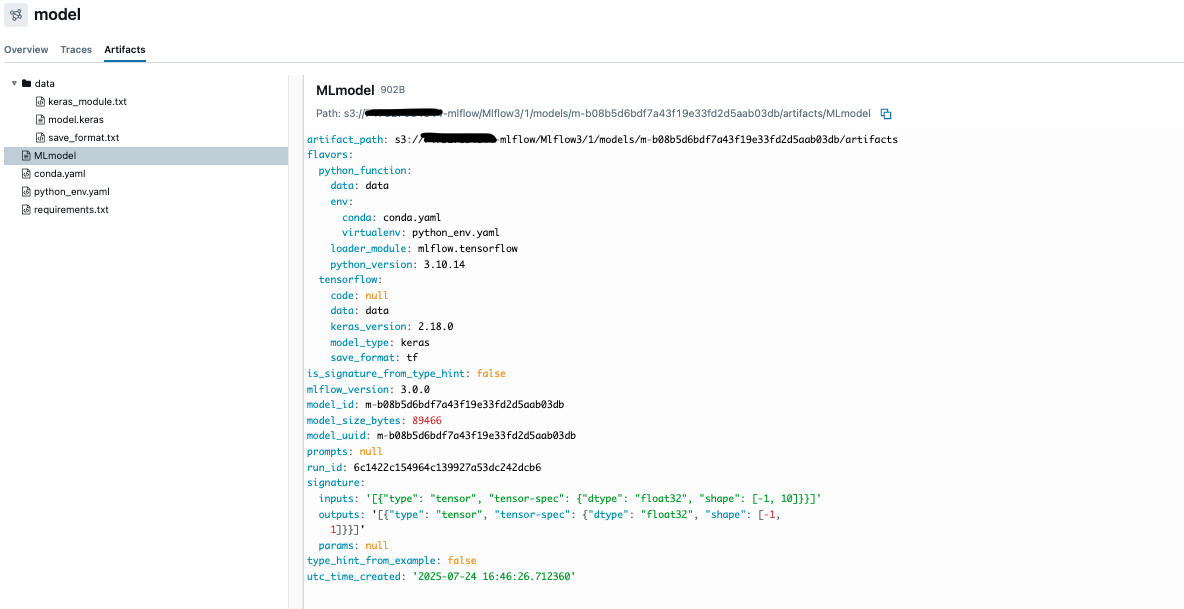
Cost implications
The following resources incur costs. Refer to the respective pricing page to estimate costs.
- Amazon EC2 On-Demand – Refer to the instance size and AWS Region where it has been provisioned. Storage using Amazon Elastic Block Store (Amazon EBS) is additional.
- SageMaker managed MLflow – You can find the details under On-demand pricing for SageMaker MLflow for tracking and storage.
- Amazon S3 – Refer to pricing for storage and requests.
- SageMaker Studio – There is no additional charges for using the SageMaker Studio UI. However, any EFS or EBS volumes attached, jobs or resources launched from SageMaker Studio applications, or JupyterLab applications will incur costs.
Clean up
Complete the following steps to clean up your resources:
- Delete the MLflow tracking server, because it continues to incur costs as long as it’s running:
- Stop the EC2 instance to avoid incurring additional costs:
- Remove training data, model artifacts, and MLflow experiment data from S3 buckets:
- Review and clean up any temporary IAM roles created for the EC2 instnce.
- Delete your SageMaker Studio domain.
Conclusion
AWS DLCs and SageMaker managed MLflow provide ML teams a solution that balances the trade-off between governance and flexibility. This integration helps data scientists seamlessly track experiments and deploy models for inference, and helps administrators establish secure, scalable SageMaker managed MLflow environments. Organizations can now standardize their ML workflows using either AWS DLCs or DLAMIs while accommodating specialized requirements, ultimately accelerating the journey from model experimentation to business impact with greater control and efficiency.
In this post, we explored how to integrate custom training environments with SageMaker managed MLflow to gain comprehensive experiment tracking and model governance. This approach maintains the flexibility of your preferred development environment while benefiting from centralized tracking, model registration, and lineage tracking. The integration provides a perfect balance between customization and standardization, so teams can innovate while maintaining governance best practices.
Now that you understand how to track training in DLCs with SageMaker managed MLflow, you can implement this solution in your own environment. All code examples and implementation details from this post are available in our GitHub repository.
For more information, refer to the following resources:
- AWS Deep Learning AMIs Developer Guide
- AWS Deep Learning Containers Developer Guide
- Amazon SageMaker AI Developer Guide
- Accelerate generative AI development using managed MLflow on Amazon SageMaker AI
About the authors
 Gunjan Jain, an AWS Solutions Architect based in Southern California, specializes in guiding large financial services companies through their cloud transformation journeys. He expertly facilitates cloud adoption, optimization, and implementation of Well-Architected best practices. Gunjan’s professional focus extends to machine learning and cloud resilience, areas where he demonstrates particular enthusiasm. Outside of his professional commitments, he finds balance by spending time in nature.
Gunjan Jain, an AWS Solutions Architect based in Southern California, specializes in guiding large financial services companies through their cloud transformation journeys. He expertly facilitates cloud adoption, optimization, and implementation of Well-Architected best practices. Gunjan’s professional focus extends to machine learning and cloud resilience, areas where he demonstrates particular enthusiasm. Outside of his professional commitments, he finds balance by spending time in nature.
 Rahul Easwar is a Senior Product Manager at AWS, leading managed MLflow and Partner AI Apps within the SageMaker AIOps team. With over 15 years of experience spanning startups to enterprise technology, he leverages his entrepreneurial background and MBA from Chicago Booth to build scalable ML platforms that simplify AI adoption for organizations worldwide. Connect with Rahul on LinkedIn to learn more about his work in ML platforms and enterprise AI solutions.
Rahul Easwar is a Senior Product Manager at AWS, leading managed MLflow and Partner AI Apps within the SageMaker AIOps team. With over 15 years of experience spanning startups to enterprise technology, he leverages his entrepreneurial background and MBA from Chicago Booth to build scalable ML platforms that simplify AI adoption for organizations worldwide. Connect with Rahul on LinkedIn to learn more about his work in ML platforms and enterprise AI solutions.