
{kind=link}
Voice AI agents are reshaping how we interact with technology. From customer service and healthcare assistance to home automation and personal productivity, these intelligent virtual assistants are rapidly gaining popularity across industries. Their natural language capabilities, constant availability, and increasing sophistication make them valuable tools for businesses seeking efficiency and individuals desiring seamless digital experiences.
Amazon Nova Sonic delivers real-time, human-like voice conversations through the bidirectional streaming interface. It understands different speaking styles and generates expressive responses that adapt to both the words spoken and the way they are spoken. The model supports multiple languages and offers both masculine and feminine voices, making it ideal for customer support, marketing calls, voice assistants, and educational applications.
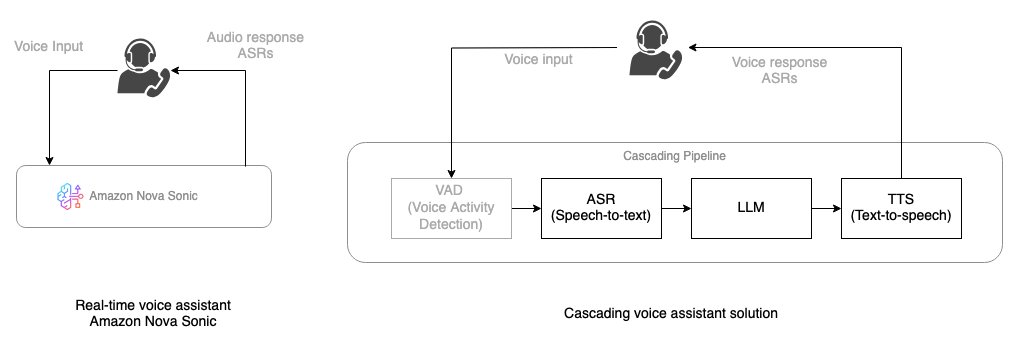
When compared with newer architectures such as Amazon Nova Sonic—which combines speech understanding and generation into a single end-to-end model—classic AI voice chat systems use cascading architectures with sequential processing. These systems process a user’s speech through a distinct pipeline: The cascaded models approach breaks down voice AI processing into separate components:
- Voice activity detection (VAD): A pre-processing VAD is required to detect when the user pauses or stops speaking.
- Speech-to-text (STT): The user’s spoken words are converted into a written text format by an automatic speech recognition (ASR) model.
- Large language model (LLM) processing: The transcribed text is then fed to a LLM or dialogue manager, which analyzes the input and generates a relevant textual response based on the conversation’s context.
- Text-to-speech (TTS): The AI’s text-based reply is then converted back into natural-sounding spoken audio by a TTS model, which is then played to the user.
The following diagram illustrates the conceptual flow of how users interact with Nova Sonic for real-time voice conversations compared to a cascading voice assistant solution.
The core challenges of cascading architecture
While a cascading architecture offers benefits such as modular design, specialized components, and debuggability, cumulative latency and reduced interactivity are its drawbacks.
The cascade effect
Consider a voice assistant handling a simple weather query. In cascading pipelines, each processing step introduces latency and potential errors. Customer implementations showed how initial misinterpretations can compound through the pipeline, often resulting in irrelevant responses. This cascading effect complicated troubleshooting and negatively impacted overall user experience.
Time is everything
Real conversations require natural timing. Sequential processing can create noticeable delays in response times. These interruptions in conversational flow can lead to user friction.
The integration challenge
Voice AI demands more than just speech processing—it requires natural interaction patterns. Customer feedback highlighted how orchestrating multiple components made it difficult to handle dynamic conversation elements like interruptions or rapid exchanges. Engineering resources often focused more on pipeline management.
Resource reality
Cascading architectures require independent computing resources, monitoring, and maintenance for each component. This architectural complexity impacts both development velocity and operational efficiency. Scaling challenges intensify as conversation volumes increase, affecting system reliability and cost optimization.
Impact on voice assistant development
These insights drove key architectural decisions in Nova Sonic development, addressing the fundamental need for unified speech-to-speech processing that enables natural, responsive voice experiences without the complexity of multi-component management.
Comparing the two approaches
To compare the speech-to-speech and cascaded approach to building voice AI agents, consider the following:
| Consideration | Speech-to-speech (Nova Sonic) | Cascaded models |
| Latency |
Optimized latency performance and TTFA We evaluate the latency performance of Nova Sonic model using the Time to First Audio (TTFA 1.09) metric. TTFA measures the elapsed time from the completion of a user’s spoken query until the first byte of response audio is received. See technical report and model card. |
Potential added latency and errors Cascaded models can use multiple models across speech recognition, language understanding, and voice generation, but are challenged by added latency and potential error propagation between stages. By using modern asynchronous orchestration frameworks like Pipecat and LiveKit, you can minimize latency. Streaming components and using text-to-speech fillers help maintain natural conversational flow and reduce delays |
| Architecture and development complexity |
Simplified architecture Nova Sonic combines speech-to-text, natural language understanding, and text-to-speech in the one model with built-in tool use and barge-in detection, providing an event-driven architecture for key input and output events, and a bidirectional streaming API for a simplified developer experience. |
Potential complexity in architecture Developers need to select best-in-class models for each stage of the pipeline, while orchestrating additional components such as asynchronous pipelines for delegated agents and tool use, TTS fillers and (VAD). |
| Model selection and customization |
Less control over individual components Amazon Nova Sonic allows customization of voices, built-in tool use and integrations to Amazon Bedrock Knowledge Bases and Amazon Bedrock AgentCore. However, it offers less granular control over individual model components compared to fully modular cascaded systems. |
Potential granular control over each step Cascaded models provide more control over each step by allowing individual tuning, replacement, and optimization of each model components such as STT, language understanding, and TTS independently. This includes models from Amazon Bedrock Marketplace, Amazon SageMaker AI and fine–tuned models. This modularity enables selection and flexibility of models, making it ideal for complex or specialized capabilities requiring tailored performance. |
| Cost structure |
Simplified cost structure through an integrated approach Amazon Nova Sonic is priced on a token-based consumption model. |
Potential complexity in costs associated with multiple components Cascaded models consist of multiple components whose costs need to be estimated. This is especially important at scale and high volumes. |
| Language and accent support | Languages supported by Nova Sonic | Potential broader language support through specialized models including the ability to switch languages mid-conversation |
| Region availability | Regions supported by Nova Sonic | Potential broader region support because of the broad selection of models and ability to self-host models on Amazon Elastic Kubernetes Service (Amazon EKS) or Amazon SageMaker. |
The two approaches also have some shared traits.
| Telephony and transport options | Both cascaded and speech-to-speech approaches support a variety of telephony and transport protocols such as WebRTC and WebSocket, enabling real-time, low-latency audio streaming over the web and phone networks. These protocols facilitate seamless, bidirectional audio exchange crucial for natural conversational experiences, allowing voice AI systems to integrate easily with existing communication infrastructures while maintaining responsiveness and audio quality. |
| Evaluations, observability, and testing | Both cascaded and speech-to-speech voice AI approaches can be systematically evaluated, observed, and tested for reliable comparison. Investing in a voice AI evaluation and observability system is recommended to gain confidence in production accuracy and performance. Such a system should be capable of tracing the entire input-to-output pipeline, capturing metrics and conversation data end-to-end to comprehensively assess quality, latency, and conversational robustness over time. |
| Developer frameworks | Both cascaded and speech-to-speech approaches are well supported by leading open-source voice AI frameworks like Pipecat and LiveKit. These frameworks provide modular, flexible pipelines and real-time processing capabilities that developers can use to build, customize, and orchestrate voice AI models efficiently across different components and interaction styles. |
When to use each approach
The following diagram shows a practical framework to guide your architecture decision:
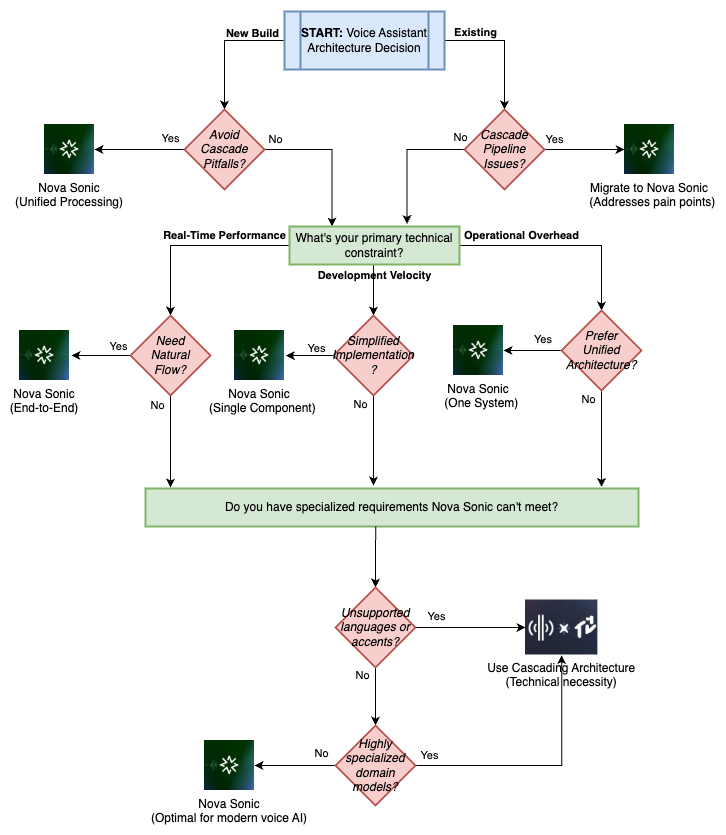
Use speech-to-speech when:
- Simplicity of implementation is important
- The use case fits within Nova Sonic’s capabilities
- You’re looking for a real-time chat experience that feels human-like and delivers low latency
Use cascaded models when:
- Customization of individual components is required
- You need to use specialized models from the Amazon Bedrock Marketplace, Amazon SageMaker AI, or fine-tuned models for your specific domain
- You need support for languages or accents not covered by Nova Sonic
- The use case requires specialized processing at specific stages
Conclusion
In this post, you learned how Amazon Nova Sonic is designed to solve some of the challenges faced by cascaded approaches, simplify building voice AI agents, and provide natural conversational capabilities. We also provided guidance on when to choose each approach to help you make informed decisions for your voice AI projects. If you’re looking to enhance your cascaded voice system, you know have the basics of how to migrate to Nova Sonic so you can offer seamless, real-time conversational experiences with a simplified architecture.
To learn more, see Amazon Nova Sonic and contact your account team to explore how you can accelerate your voice AI initiatives.
Resources
- Amazon Nova Sonic Technical Report and Model Card
- Amazon Nova Sonic User Guide
- Amazon Nova Sonic and Amazon Bedrock AgentCore
- Amazon Nova Sonic Telephony Integration Guide
- Amazon Nova Sonic and Pipecat
- Amazon Nova Sonic and LiveKit
About the authors
 Daniel Wirjo is a Solutions Architect at AWS, focused on AI and SaaS startups. As a former startup CTO, he enjoys collaborating with founders and engineering leaders to drive growth and innovation on AWS. Outside of work, Daniel enjoys taking walks with a coffee in hand, appreciating nature, and learning new ideas.
Daniel Wirjo is a Solutions Architect at AWS, focused on AI and SaaS startups. As a former startup CTO, he enjoys collaborating with founders and engineering leaders to drive growth and innovation on AWS. Outside of work, Daniel enjoys taking walks with a coffee in hand, appreciating nature, and learning new ideas.
 Ravi Thakur is a Sr Solutions Architect at AWS based in Charlotte, NC. He has cross‑industry experience across retail, financial services, healthcare, and energy & utilities, and specializes in solving complex business challenges using well‑architected cloud patterns. His expertise spans microservices, cloud‑native architectures, and generative AI. Outside of work, Ravi enjoys motorcycle rides and family getaways.
Ravi Thakur is a Sr Solutions Architect at AWS based in Charlotte, NC. He has cross‑industry experience across retail, financial services, healthcare, and energy & utilities, and specializes in solving complex business challenges using well‑architected cloud patterns. His expertise spans microservices, cloud‑native architectures, and generative AI. Outside of work, Ravi enjoys motorcycle rides and family getaways.
 Lana Zhang is a Senior Specialist Solutions Architect for Generative AI at AWS within the Worldwide Specialist Organization. She specializes in AI/ML, with a focus on use cases such as AI voice assistants and multimodal understanding. She works closely with customers across diverse industries, including media and entertainment, gaming, sports, advertising, financial services, and healthcare, to help them transform their business solutions through AI.
Lana Zhang is a Senior Specialist Solutions Architect for Generative AI at AWS within the Worldwide Specialist Organization. She specializes in AI/ML, with a focus on use cases such as AI voice assistants and multimodal understanding. She works closely with customers across diverse industries, including media and entertainment, gaming, sports, advertising, financial services, and healthcare, to help them transform their business solutions through AI.