

Amazon Simple Storage Service (Amazon S3) is a highly elastic service that automatically scales with application demand, offering the high throughput performance required for modern ML workloads. High-performance client connectors such as the Amazon S3 Connector for PyTorch and Mountpoint for Amazon S3 provide native S3 integration in training pipelines without dealing directly with the S3 REST APIs.
In this post, we present practical techniques and recommendations for optimizing throughput in ML training workloads that read data directly from Amazon S3 general purpose buckets. That said, many of the data loading optimization techniques discussed here are broadly applicable across different storage fabrics.
To validate these recommendations, we benchmarked a representative Computer Vision (CV) training workload—specifically, an image classification task with tens of thousands of small JPEG files. We evaluated multiple data access patterns from S3 buckets and compared the performance of different S3 clients, including the Amazon S3 Connector for PyTorch and Mountpoint for Amazon S3.
Our findings show that consolidating datasets into appropriately sized data shards, typically in the range of 100 MB to 1 GB, combined with sequential access patterns, deliver significantly higher throughput. Caching frequently accessed training data further improves efficiency in multi-epoch training scenarios. Finally, among the S3 clients evaluated, the Amazon S3 Connector for PyTorch consistently achieved the highest throughput, outperforming other commonly used methods for accessing data in S3.
Performance bottlenecks in ML training pipelines
While GPUs play a vital role in accelerating ML computations, training is a multifaceted process with several interdependent stages—any of which can become a bottleneck. The diagram below illustrates a typical end-to-end training pipeline and highlights where these stages occur. Although factors such as the training algorithm, model architecture, implementation details, and hardware all matter, it’s helpful to think of a training workload as a pipeline with the following four recurring high-level steps:
- Reading training samples from persistent storage into memory.
- Pre-processing training samples in memory with steps such as decoding, transforming, and augmenting.
- Updating model parameters based on gradients computed and synchronized across GPUs.
- Saving training checkpoint periodically for fault tolerance by allowing training to resume from the most recent state in case of failures.
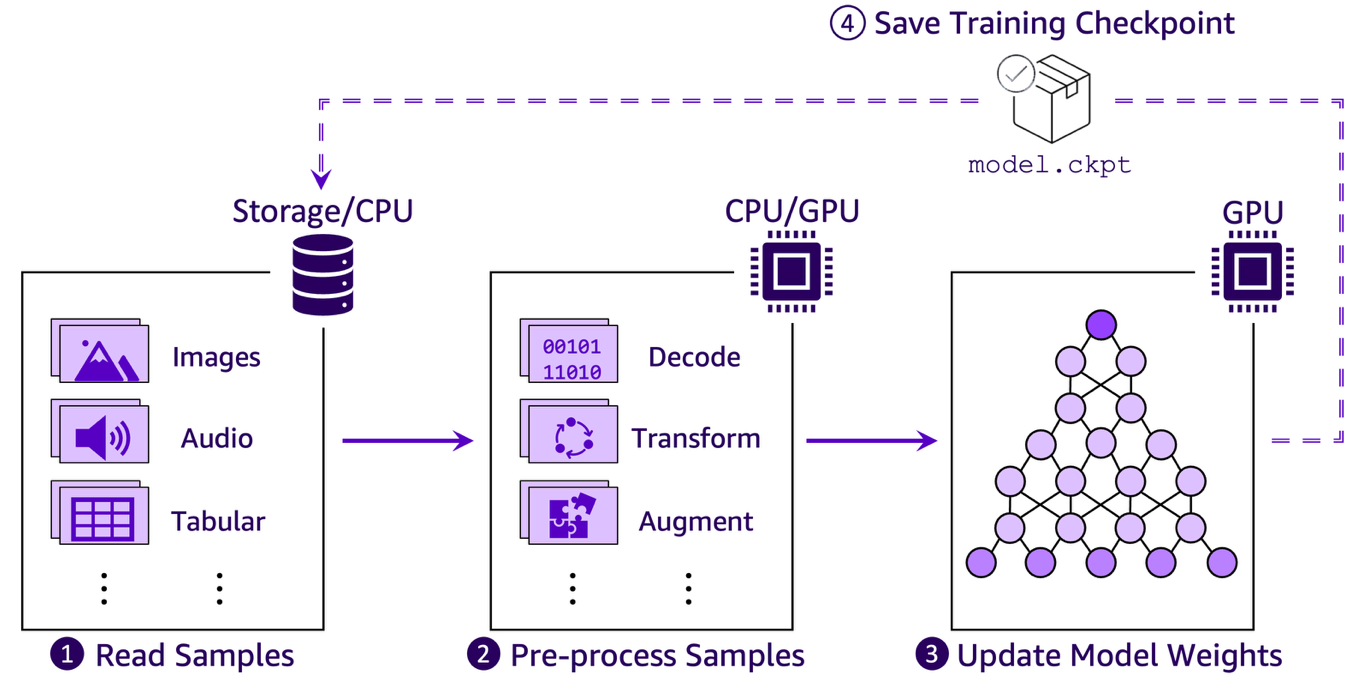
The effective throughput of any ML training pipeline is then constrained by its slowest step. While step 3—the actual computation of model updates—is what we ultimately care about, cloud-based ML workloads could face unique challenges. In cloud environments where compute and storage resources are typically decoupled by design, the data input pipeline (steps 1–2) frequently emerge as the critical bottlenecks. Checkpointing (step 4) could also impact overall training efficiency, but we will not cover it in this post.
Even the most modern GPUs can’t accelerate training if they’re sitting idle, waiting for data to process. When data starvation occurs, additional investments in more powerful compute hardware deliver diminishing returns—a costly inefficiency in production environments. Achieving maximum GPU utilization requires thoughtful optimization of your data pipeline for a continual flow of training samples that are ready for consumption by the GPUs.
The data loading challenge
One of the most important factors influencing data loading performance from Amazon S3 is the pattern in which data is accessed during training. In particular, the distinction between sequential and random reads plays a role in determining overall throughput and latency. Understanding how these access patterns interact with the underlying characteristics of Amazon S3 is key to designing efficient input pipelines.
Sequential and random reads in ML workloads on Amazon S3
Reading data from Amazon S3 can be compared to the behavior of traditional hard disk drives (HDDs) with mechanical actuator arms. As shown in the illustration below, HDDs read data blocks sequentially when they are located contiguously, allowing the actuator arm to minimize movement. In contrast, random reads require the actuator arm to jump across the disk’s surface to access scattered blocks, introducing delays because of the physical repositioning of the arm.

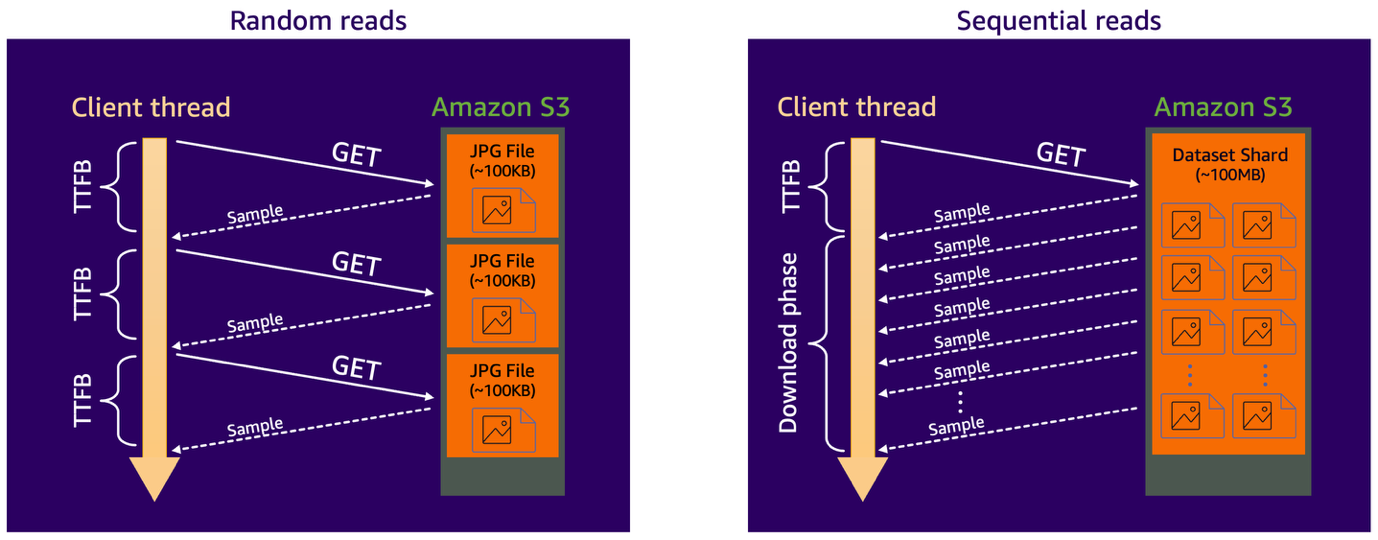
When accessing data on Amazon S3, the situation is somewhat similar to the HDD example. To be precise, each S3 request incurs a time-to-first-byte (TTFB) overhead before actual data transfer begins. This overhead comprises several components: establishing the connection, network round-trip latency, internal operations of S3 (such as locating the data and accessing it on disk), and client-side response handling. While the data transfer time itself scales with the size of the data being retrieved, the TTFB overhead of the S3 GET request is largely fixed and independent of the data object size, which is what the illustration below demonstrates.
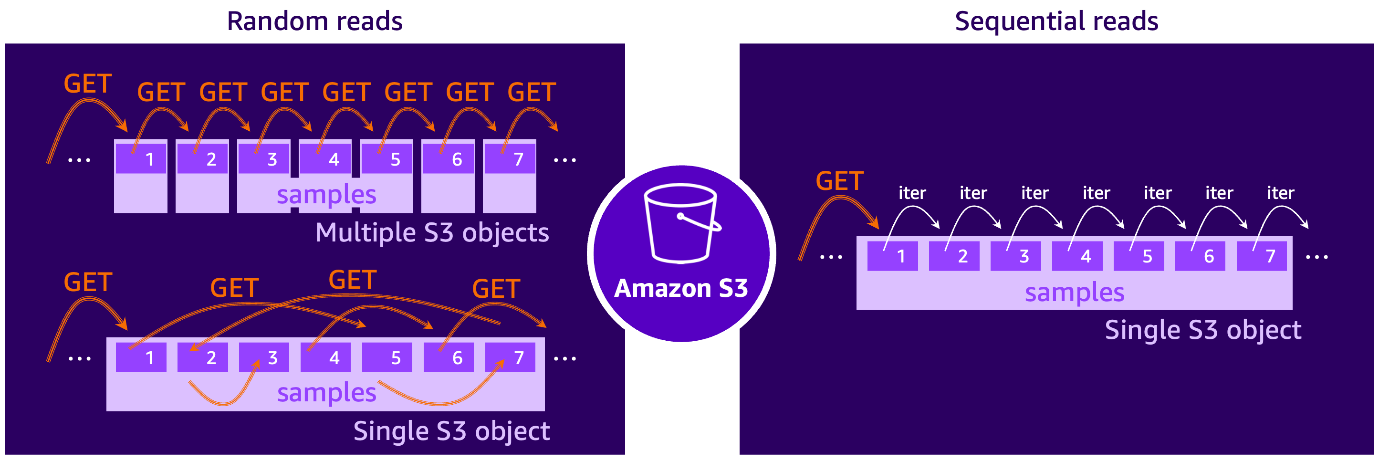
Following the HDD analogy when discussing ML workloads, we can say that we have random read patterns from cloud storage, when, for example, datasets consist of numerous small files stored on S3, with each file containing a single training sample. Alternatively, random S3 access also occurs when training scripts fetch samples from different parts within a larger file shard using, for example, byte-range S3 GET requests. This is akin to watching a YouTube video by constantly skipping scenes back and forth.
Conversely, sequential read patterns occur when datasets are organized into large file shards, with each shard containing many training samples, which can be iterated sequentially one after another. In this case, a single S3 GET request can retrieve multiple samples, enabling much higher data throughput than in the random read scenario. This approach also streamlines data prefetching, as the next batch of samples can be anticipated, fetched, and buffered in-memory, making it readily available for the GPU to grab.
Analyzing throughput implications: a computer vision case study
To better understand how different data access patterns impact performance, let’s look at two scenarios in a computer vision task where the dataset consists of many relatively small image files (around 100 KB each). In the first scenario, the dataset is stored as is in the Amazon S3 Standard storage class, and the training script retrieves each image on demand. This creates a random read access pattern, where each training sample requires its own S3 GET request. Because the time-to-first-byte (TTFB) latency for S3 Standard is on the order of tens of milliseconds, and the actual download time for small files is minimal in comparison, the dataloader’s performance becomes latency-bound. In other words, the client threads spend most of their time idling while waiting for data to arrive.
In the second scenario, the dataset is consolidated into larger file shards (for example, ~100 MB each) before being stored in S3. Now, the dataloader reads multiple training samples sequentially with a single S3 GET request. This shifts the workload to being bandwidth-bound, removing the per-sample TTFB impact and enabling efficient streaming of consecutive samples during the download phase.
Optimization techniques for data loading from Amazon S3
Now that we’ve gone over the random and sequential data access patterns for ML workloads from S3, let’s go over the ways of how we can optimize the data ingestion pipelines in practice.
Use high-performance and file clients optimized for S3
Choosing a performant S3 file client can be challenging given the abundance of options available. To address this, in 2023, AWS introduced two native open source clients for S3: Mountpoint for Amazon S3 and Amazon S3 Connector for PyTorch. Both are built on the AWS Common Runtime (CRT), a collection of highly optimized C-based primitives including a native S3 client that implements best-practice performance optimizations, such as request parallelization, timeouts, retries, and connection reuse so that customers achieve maximum S3 throughput with minimal effort.
Mountpoint for Amazon S3 is an open source file client that you can use to mount an S3 bucket on your compute instance and access it as a local file system without requiring changes to your existing code. This makes it a strong fit for a wide range of workloads, including ML training.
For Kubernetes environments, the Mountpoint for Amazon S3 Container Storage Interface (CSI) Driver extends this capability by presenting an S3 bucket as a storage volume, allowing containers to access S3 objects through a familiar file system interface. With the recent release of Mountpoint for Amazon S3 CSI v2, the driver also introduces shared caching across pods, so distributed ML workloads can reuse locally cached data—boosting both performance and resource efficiency. The CSI driver is compatible with any Kubernetes-based application and can integrate with Amazon Elastic Kubernetes Service (Amazon EKS), where it’s available as a managed add-on for streamlined installation and lifecycle management.
Amazon S3 Connector for PyTorch provides PyTorch-native primitives that tightly integrate S3 with training pipelines. The integration enables high-throughput access to training data and efficient checkpointing directly to Amazon S3. It automatically applies performance optimizations when reading training data or writing model checkpoints.
The connector supports both map-style datasets for random access and iterable-style datasets for streaming sequential access, making it suitable for a variety of ML training patterns. It also includes a built-in checkpointing interface that allows saving and loading checkpoints from S3 without relying on local storage. Installation is lightweight (for example, using pip), and the connector requires no additional file system clients or complex system setup—only minimal changes to your training code, as demonstrated in GitHub.
Shard datasets and use sequential read patterns
An effective strategy for optimizing data loading from S3 is to serialize datasets into fewer, larger file shards, each containing many training samples, and to read those samples sequentially using your dataloader. In our S3 micro-benchmarks, shard sizes between 100 MB–1 GB typically delivered excellent throughput. However, the ideal size might vary depending on your workload. Smaller shards can improve quasi-random sampling behavior from prefetch buffers, while larger shards generally offer better raw throughtput.
Common file formats for sharding include tar (frequently used in PyTorch through libraries like WebDataset) and TFRecord (used with tf.data in TensorFlow). That said, sharding data doesn’t guarantee sequential reads. If your dataloader randomly accesses samples within a shard—common with formats like Parquet or HDF5, the benefits of sequential access can be lost. To fully realize performance gains, we recommend that you design your data loader so that samples are read in order within each shard.
Parallelization, prefetching, and caching of training samples
Optimizing the data ingestion and preprocessing stages of an ML pipeline is critical to maximizing training throughput, especially when random data access patterns are unavoidable. Techniques such as parallelization, prefetching, and caching play a central role in minimizing I/O bottlenecks and keeping GPUs fully utilized.
Parallelization is one of the most effective ways to improve throughput in data loading pipelines, particularly because data decoding and preprocessing are often embarrassingly parallel, meaning they can be broken down into many independent processes that run simultaneously without needing to communicate. You can use frameworks like TensorFlow (tf.data) and PyTorch (native DataLoader) to tune the size of their worker pools—CPU threads or processes—to parallelize data ingestion.
For sequential access patterns, a good rule is to match the number of worker threads to the number of available CPU cores. However, on instances with a high CPU count (for example, over 20), using a slightly smaller pool can improve efficiency.
In contrast, for random access patterns, particularly when reading directly from S3, larger-than-CPU-count pool sizes have proven beneficial in our benchmarks. For example, on an EC2 instance with 8 vCPUs, increasing the PyTorch num_workers setting to 64 or more significantly improved data throughput.
That said, increasing parallelism is not a silver bullet. Over-parallelizing can overwhelm CPU and memory resources, shifting the bottleneck from I/O to preprocessing. It’s important to benchmark within the context of your specific workload to find the right balance.
Prefetching complements parallelization by decoupling data loading from GPU computation. Using a producer-consumer pattern, prefetching allows data to be prepared asynchronously and buffered in memory so that the next batch is ready when the GPU needs it. Well-sized prefetch buffers and properly tuned worker pool sizes help amortize I/O and preprocessing latency, improving overall training throughput.
Caching is particularly effective for multi-epoch training workloads with random access patterns, where the same data samples are read multiple times. Tools like Mountpoint for Amazon S3 offer built-in caching mechanisms that store dataset objects locally on instance storage (for example, NVMe disks), EBS volumes, or memory. By removing repeated S3 GET requests, caching improves training speed and cost efficiency.
Because the input dataset typically remains static during training, we recommend configuring Mountpoint with indefinite metadata TTL (by setting --metadata-ttl indefinite, see Mountpoint for S3 documentation) to reduce S3 request overhead. Furthermore, in our benchmarks, we also enabled data caching to NVMe, allowing Mountpoint to store objects locally. The cache automatically manages space by evicting the least recently used files, maintaining at least 5% of available space by default (configurable). To benefit fully from caching, make sure that your instance has sufficient disk space to hold frequently accessed data.
Performance case study: data loading from Amazon S3 Standard
To validate the best practices discussed earlier, we conducted a series of benchmarks simulating a realistic computer vision (CV) training workload under both random and sequential data access patterns. While the exact results can vary based on your specific use case, the performance trends and insights are broadly applicable across ML training pipelines.
Benchmark setup
All benchmarks were executed on an Amazon Elastic Compute Cloud (Amazon EC2) g5.8xlarge instance equipped with an NVIDIA A10G GPU and 32 vCPUs. The benchmark workload used the google/vit-base-patch16-224-in21k backbone ViT model for an image classification task, training on a 10 GB dataset containing 100,000 synthetic JPEG images (~115 KB each). The dataset was streamed directly from Amazon S3 Standard on demand by the training script using one of the following S3 clients:
- fsspec-based dataloader – implementation of TorchData DataPipes based on fsspec, a popular open source interface for cloud object stores. Although TorchData deprecated DataPipes in v0.10, fsspec remains widely used for ML data access from S3.
- Mountpoint for Amazon S3 (no data caching) – A high-throughput, open source file client developed by AWS. In this configuration, metadata caching is enabled but training samples are not cached locally between epochs.
- Mountpoint for Amazon S3 (data caching) – Identical to the previous client, but with local disk caching enabled to store frequently accessed samples across epochs.
- S3 Connector for PyTorch – A high-performance, open source S3 interface tightly integrated with PyTorch’s dataset APIs, also maintained by AWS.
Each benchmark configuration streamed the dataset on demand during training, with no prior local downloads or preprocessing.
Benchmark goals
The benchmarks were designed to explore:
- The effect of tuning parallelization settings in the dataloader.
- The performance impact of local disk caching using Mountpoint for Amazon S3.
- The throughput gains from adopting a sequential read pattern.
- The relationship between dataset shard size and sustained data loading performance.
For both access patterns, the preprocessing stage included JPEG decoding and resizing to 224×224×3, followed by batching into mini-batches of 128. This lightweight setup helped us to maintain a realistic end-to-end pipeline while minimizing CPU-bound overhead.
Reproducibility and best practices
To reproduce similar benchmarks in your own environment, we provide a dedicated benchmarking tool that supports a variety of S3 data loading configurations.
For consistent and meaningful results:
- Use identical EC2 instance types for each S3 client.
- Place each test dataset in separate S3 buckets to isolate traffic and avoid cross-client interference.
- Run experiments in the same AWS Region as your S3 buckets to minimize latency and network variability.
You can get clean measurements and reliably compare different data loading strategies in your own workloads by following these best practices.
Single-epoch benchmark with random access
To evaluate the effect of parallelization when streaming datasets directly from Amazon S3, we ran a one-epoch benchmark (a single full sweep through the training dataset) to avoid interference from potential OS-level caching.
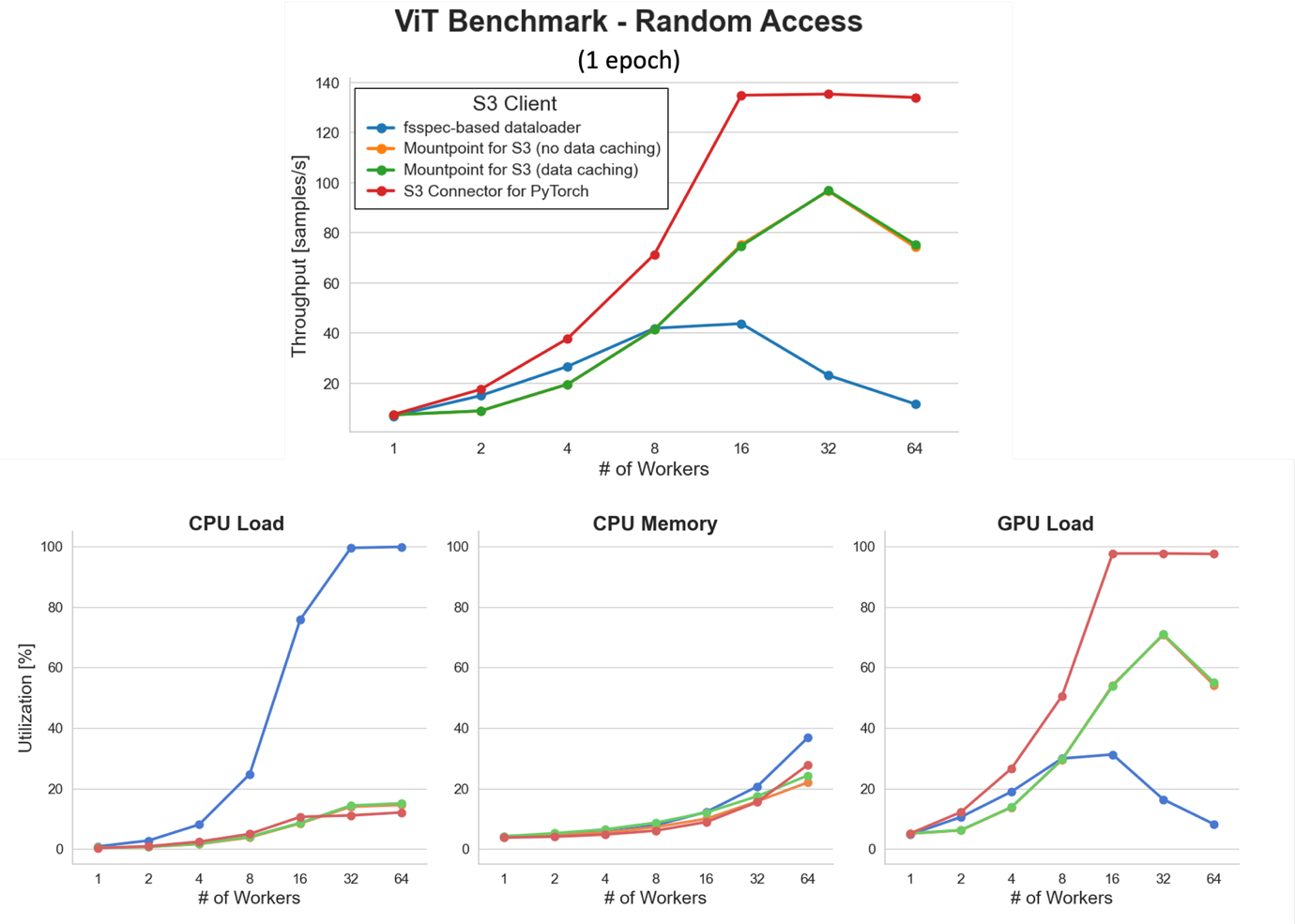
At low worker counts, all S3 clients exhibit data ingestion bottlenecks, limiting overall throughput. As the degree of parallelization increases, throughput improves significantly. Notably, the S3 Connector for PyTorch reaches near GPU saturation (at ~138 samples/sec) with over 16 workers.
However, aggressive scaling of the worker pool increases CPU and memory pressure. This is particularly evident with the fsspec-based dataloader, which reaches ~100% CPU utilization at 32 workers, causing a CPU-bound bottleneck that degrades GPU utilization and reduces overall sample throughput. In contrast, the S3 Connector for PyTorch maintains better efficiency under load, highlighting the importance of using a high-performance S3 client.
Mountpoint for Amazon S3, with and without data caching, delivers nearly identical performance in this one-epoch benchmark—as expected, because each sample is read only once and caching offers no advantage. We will revisit caching benefits in the multi-epoch scenario discussed next.
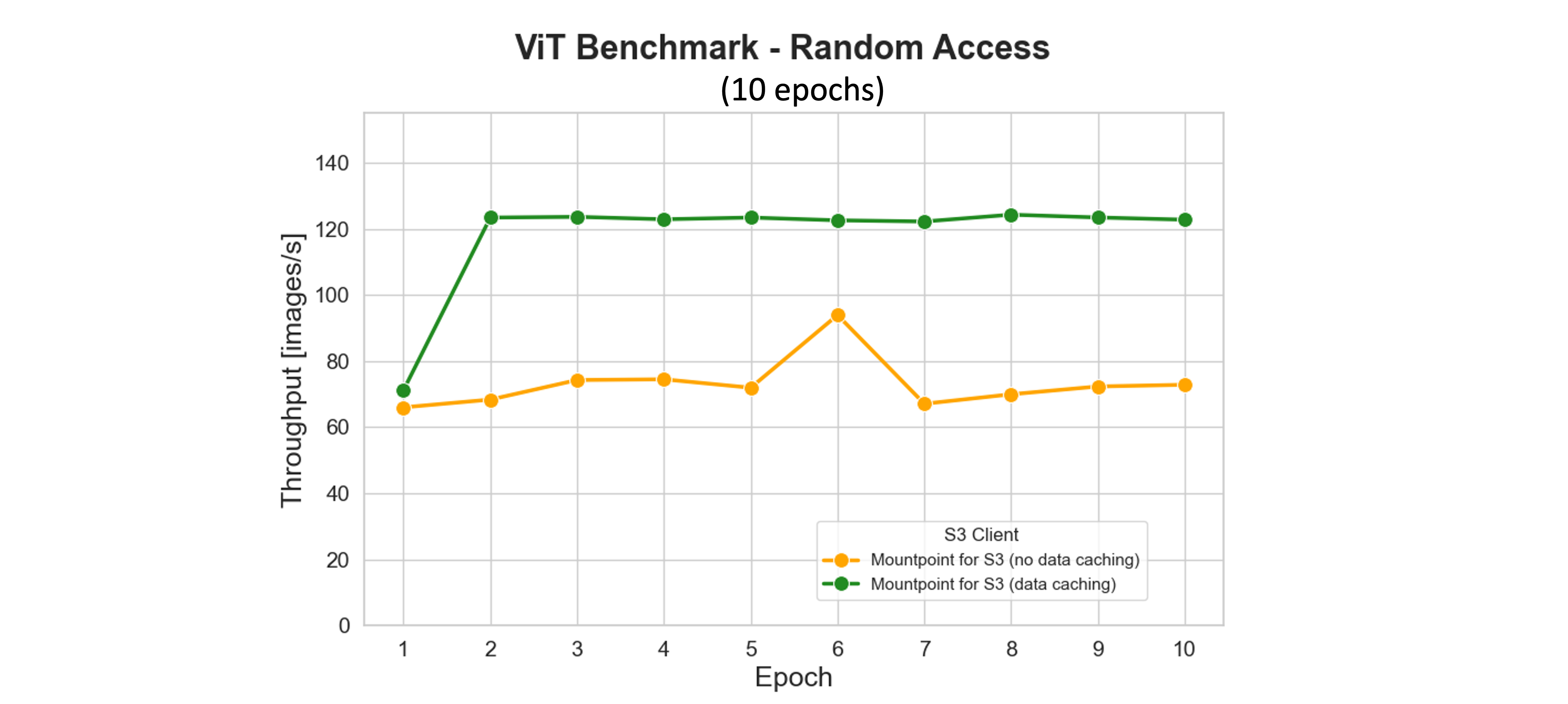
Multi-epoch benchmark with random access
The caching feature of Mountpoint for Amazon S3 significantly boosts training performance by storing frequently accessed S3 objects on local storage, reducing retrieval latency and request costs across epochs. In our benchmark, dataset files accessed during the first epoch are cached locally. From the second epoch onward, the entire dataset is served from disk—fully saturating the GPU and maximizing throughput, even with a dataloader worker pool of 16.
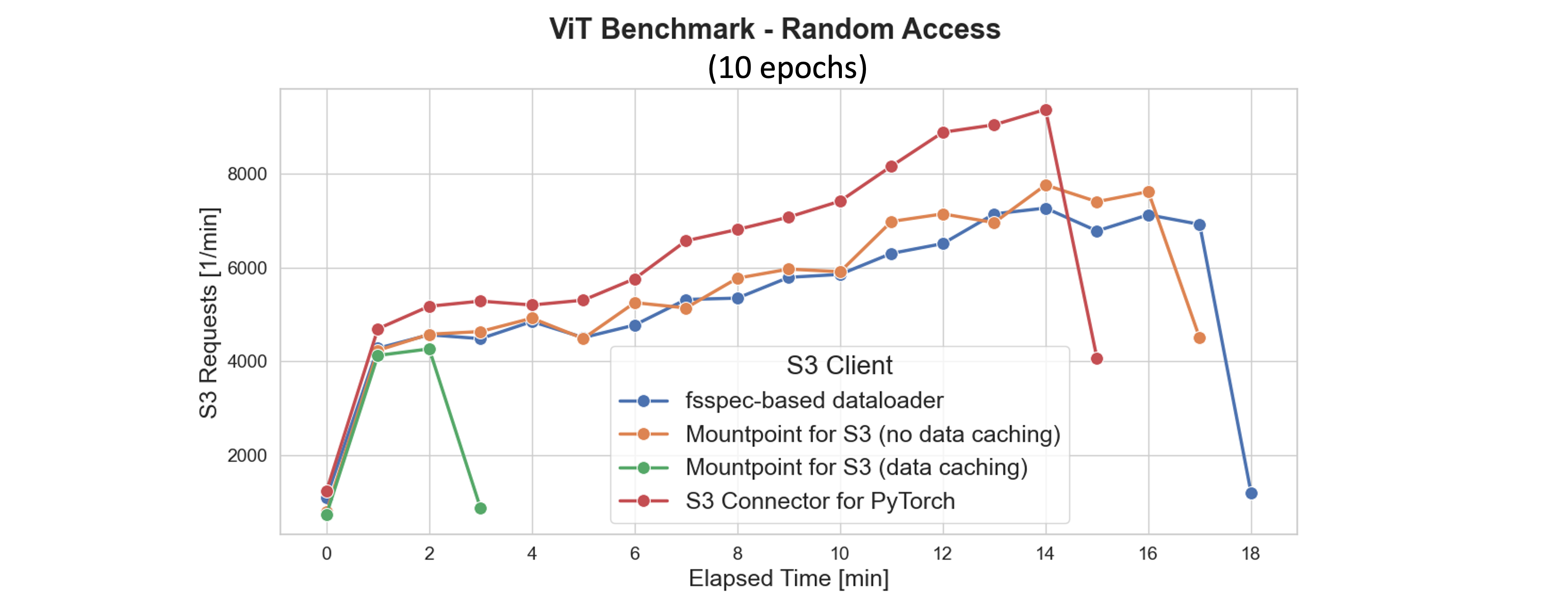
As illustrated in the following plot, caching not only accelerates training but also minimizes network traffic and S3 request volume. By the end of the first epoch (around the 2-minute mark), Mountpoint removes further GET, LIST, and HEAD requests to S3. In contrast, S3 clients without caching continuously re-download the same data each epoch, incurring higher latency and operational costs.
Single-epoch benchmark with sequential access
To validate the benefits of sequential data access, we reran the benchmarks using the same setup as before (with 8 dataloader workers), but switched to a serialized dataset in tar-format with shard sizes ranging from 4 MB–256 MB.
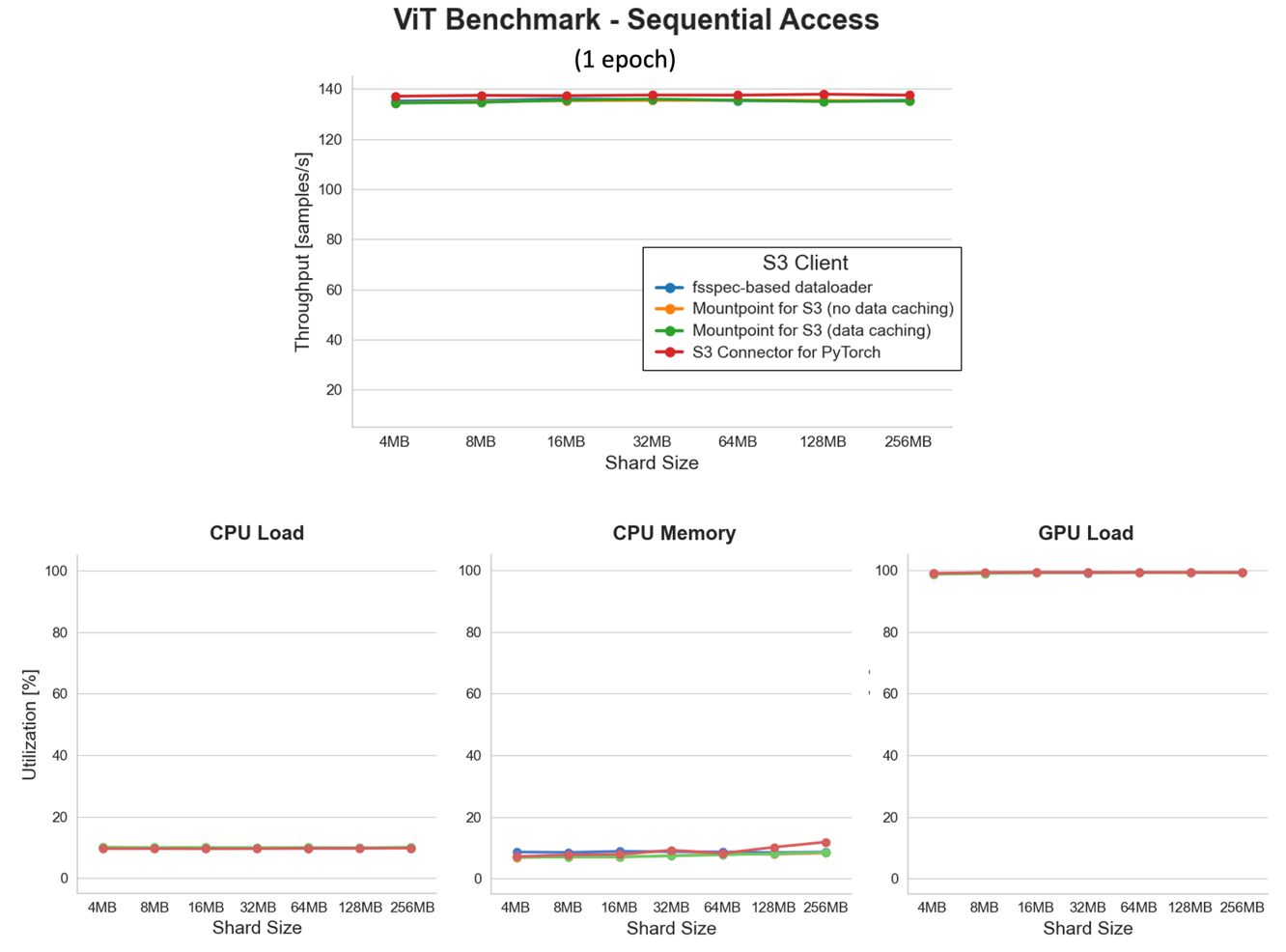
At first glance, the results of this benchmark might seem unspectacular—all the line plots are flat. But wait, isn’t that the spectacular part? The GPU load is consistently flat at ~100% utilization, meaning we’re fully saturating our GPUs across all file shard sizes. Combine that with consistently low CPU usage, and you’ve got yourself a pretty remarkable achievement!
Entitlement benchmark with sequential access
The results of the previous benchmark raise an interesting question: what is the theoretical maximum throughput that we can achieve in this setup with sequential access? To find out, we ran an entitlement benchmark where we removed the GPU-bound model training stage from the equation entirely and kept only reading and preprocessing stages on CPUs. The results for a worker pool size of 8 are shown in the following plot.
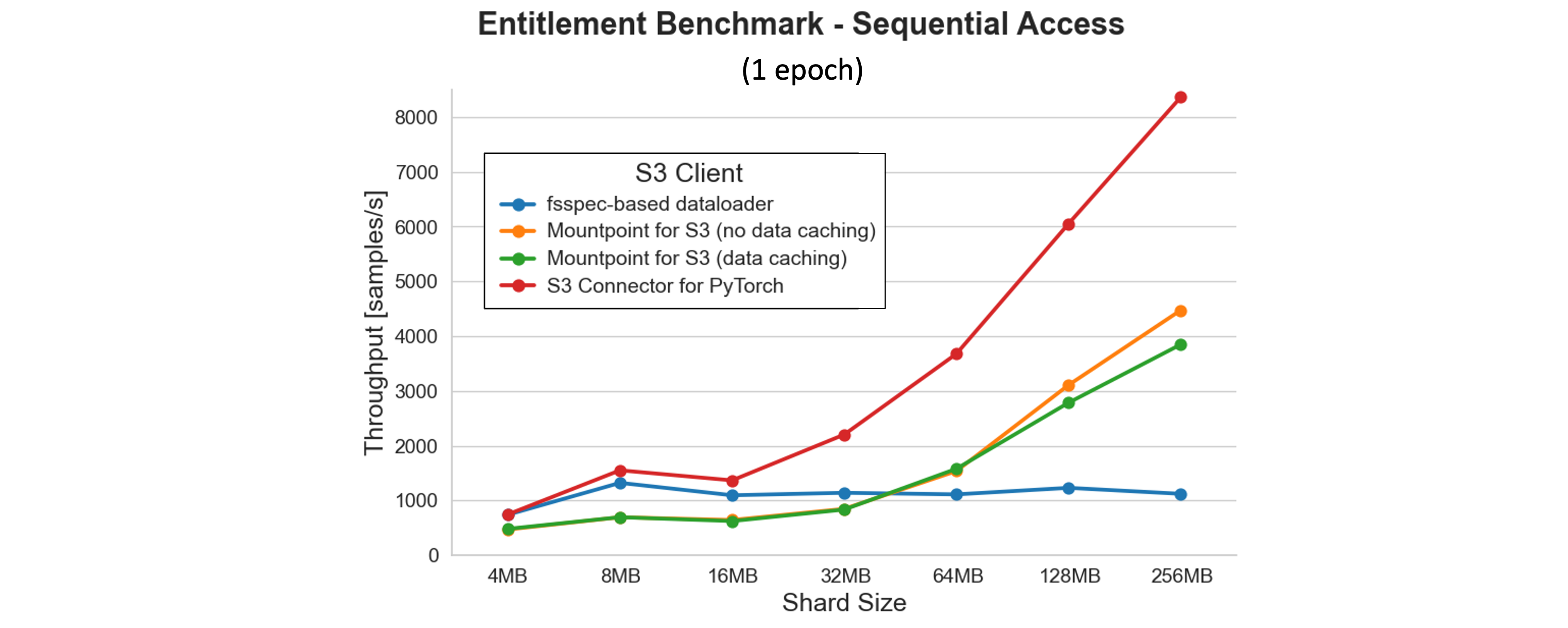
The results show that throughput improves with larger shard sizes for all clients, except for the fsspec-based dataloader. The S3 Connector for PyTorch delivers the highest performance, reaching over 8,000 samples/s at the largest tested shard size. With higher parallelism (32–64 workers) or larger shards, throughput scales further, exceeding 12,000 samples/s in our extended tests.
Conclusion
Optimizing data ingestion is crucial for fully unlocking the performance of modern ML training pipelines in the cloud. In this post, we showed how random read patterns and small file sizes can severely limit throughput due to latency overheads, while consolidated datasets with sequential access patterns can maximize bandwidth and keep GPUs fully utilized.
We explored how using high-performance Amazon S3 clients, such as Mountpoint for Amazon S3 and the S3 Connector for PyTorch, can make a significant difference in training performance. We also demonstrated the benefits of sharding datasets into larger files, tuning parallelization settings, and applying caching to minimize redundant S3 requests. Our benchmarks, focused on workloads accessing data from Amazon S3 Standard, confirm that these best practices can substantially reduce idle GPU time and help you get the most value from your compute resources.
As your training workloads grow, keep revisiting your data pipeline design. Thoughtful decisions about data loading can deliver outsized gains in cost efficiency and time to results.
About the authors
 Dr. Alexander Arzhanov is a Senior AI/ML Specialist Solutions Architect based in Frankfurt, Germany. He helps AWS customers design and deploy their ML solutions across the EMEA region. Prior to joining AWS, Alexander was researching origins of heavy elements in our universe and grew passionate about ML after using it in his large-scale scientific calculations.
Dr. Alexander Arzhanov is a Senior AI/ML Specialist Solutions Architect based in Frankfurt, Germany. He helps AWS customers design and deploy their ML solutions across the EMEA region. Prior to joining AWS, Alexander was researching origins of heavy elements in our universe and grew passionate about ML after using it in his large-scale scientific calculations.
 Ilya Isaev is a Software Engineer in Amazon S3 based in Cambridge, UK. He works on helping customers efficiently store and manage training data and model checkpoints in Amazon S3, focusing on improving real-time data access performance for large clusters of high-performance GPU instances.
Ilya Isaev is a Software Engineer in Amazon S3 based in Cambridge, UK. He works on helping customers efficiently store and manage training data and model checkpoints in Amazon S3, focusing on improving real-time data access performance for large clusters of high-performance GPU instances.
 Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS. He helps AWS customers—from small startups to large enterprises—train and deploy foundation models efficiently on AWS. He is passionate about computational optimization problems and improving the performance of AI workloads.
Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS. He helps AWS customers—from small startups to large enterprises—train and deploy foundation models efficiently on AWS. He is passionate about computational optimization problems and improving the performance of AI workloads.





