

The Cat 306 CR mini-excavator weighs just under eight tons and fits inside a standard shipping container. It’s the machine a contractor rents when the job site is tight: a utility trench near a foundation, a basement dig in a dense neighborhood.
The cab is roughly the size of a phone booth. The operator sits close to the controls, two joysticks, multiple functions per hand. It takes time to learn. It takes longer to speed up.
At CES earlier this year, that machine answered questions.
In the demo, the Cat AI Assistant ran on NVIDIA Jetson Thor, an edge AI platform built for real‑time inference in industrial and robotic systems, NVIDIA Nemotron speech models are used for fast and accurate natural voice interactions. Qwen3 4B, served locally via vLLM, interprets requests and generates responses with low latency, no cloud link required.
Beyond enterprise innovation, open models unlock new possibilities for developers to build and experiment freely. Running OpenClaw on NVIDIA Jetson enables developers to create private, always-on AI assistants at the edge — with zero application programming interface cost and full data privacy.
All Jetson developer kits support OpenClaw, offering the flexibility to switch across open models from 2B to 30B. With a frontier-class AI assistant running locally, users can power morning briefings, automate daily tasks, perform code reviews and control smart home systems — all in real time.
From the Cloud to the Edge
For most of their recent history, open models lived where it was easiest to support them.
They ran in data centers, backed by elastic compute and persistent networks. Cloud deployments carry costs in latency and ongoing compute spend that scale with every query.
Physical systems optimize for something else. Low latency because machines interact with people and environments. Limited power because devices have hard limits. And consistent behavior because variability introduces risk.
There’s also a supply question. Memory shortages have driven up costs across the industry. Jetson brings compute and memory together in a system-on-module, accelerating customer hardware design and making sourcing and validation easier than with discrete component approaches.
And as models have grown more efficient, developers have also started asking a different question. Not which model performs best in isolation, but where it makes sense to run.
More often, the answer is on the device, starting from Jetson Orin Nano 8GB for entry-level generative AI models.
Building Autonomous Physical AI Systems at Scale
For physical AI systems, generative AI models are expanding what’s possible.
Caterpillar’s in-cab Cat AI Assistant, which is in development, runs speech and language models locally alongside trusted machine context, supporting operator guidance and safety features.
At CES, Franka Robotics showed what that looks like in robotics. The company’s FR3 Duo dual-arm system ran the NVIDIA GR00T N1.6 model end-to-end onboard, perception to motion, no task scripting. The policy executes locally.
In robotics research, the SONIC project from NVIDIA’s GEAR Lab trains a humanoid controller on over 100 million frames of motion-capture data, then deploys the resulting policy on a physical robot where the kinematic planner runs on Jetson Orin at around 12 milliseconds per pass. The policy loop runs at 50 Hz. Everything executes onboard.
The pattern reaches into the developer community. A team from UIUC’s SIGRobotics club built a dual-arm matcha-making robot on Jetson Thor running the GR00T N1.5 model. It took first place at an NVIDIA embodied AI hackathon.
This research momentum continues at the NYU Center for Robotics and Embodied Intelligence. The group recently ran its YOR robot on Jetson Thor, using NVIDIA Blackwell compute to handle the heavy processing required for AI-driven movement. Early results show YOR performing intricate pick-and-place tasks with better generalization to new objects and robustness to scene variation, accelerating readiness for a wide range of household tasks like cooking and laundry.
Independent researchers are finding the same. Andrés Marafioti, a multimodal research lead at Hugging Face, built an agentic AI system on Jetson AGX Orin that routes tasks across models and schedules its own work. Late one night, the agent sent him a message: Go to sleep. Everything will be ready by morning.
Developer Ajeet Singh Raina from the Collabnix community has shown how to run OpenClaw on NVIDIA Jetson Thor for a personal AI assistant that runs 24/7. This setup allows for private large language model inference for the user’s own data while the system manages emails and calendars through a local gateway.
Jetson Is the New Standard
NVIDIA Jetson has become a common platform for running open models at the edge.
It supports a wide range of open models and AI frameworks, giving developers flexibility for almost any generative AI workload at the edge.
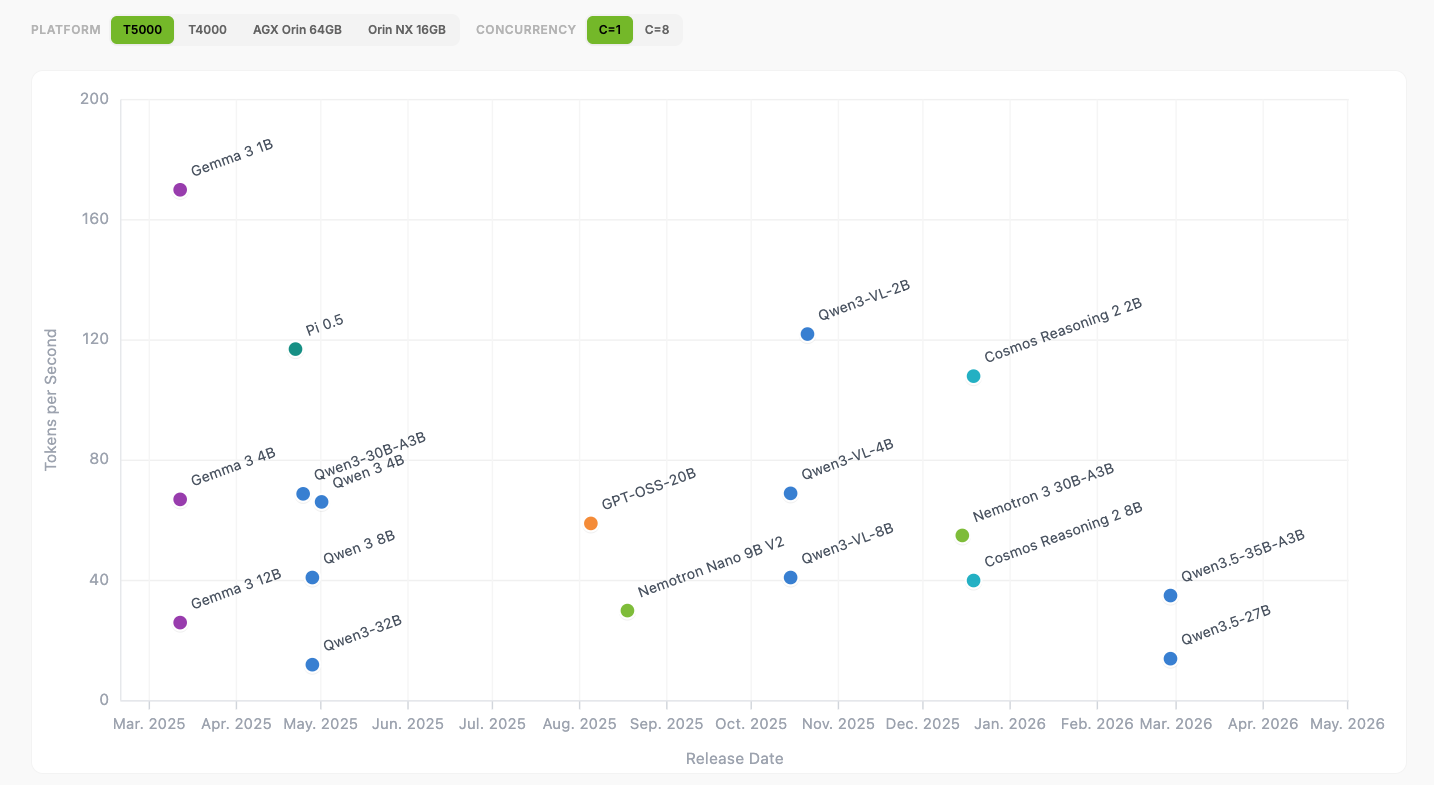
Model benchmarks are available at Jetson AI Lab, along with tutorials from the open model community. Jetson Thor delivers leadership inference performance across all major generative AI models.
Gemma: Built on Google’s Gemini research, Gemma 3 is a versatile workhorse for Jetson. It is multimodal out of the box, which means it can see and talk in over 140 languages. On Jetson Thor, it handles a massive 128K context window. This makes it perfect for robots that need to remember a long list of complex or multistep instructions.
gpt-oss-20B: This model from OpenAI lowers the barrier to deploying advanced AI by delivering near state-of-the-art reasoning performance in a model that can run locally on Jetson Thor and Orin for cost-efficient inference.
Mistral AI: The new Mistral 3 open model family delivers industry-leading accuracy, efficiency and customization capabilities for developers and enterprises. This family includes small, dense models ranging from 3B to 14B, fast and remarkably smart for their size. Jetson developers can use the vLLM container on NVIDIA Jetson Thor to achieve 52 tokens per second for single concurrency, with scaling up to 273 tokens per second with concurrency of eight.
NVIDIA Cosmos This leading, open, reasoning vision language model enables robots and AI agents to see, understand and act in the physical world like humans. Both the 8B and 2B models run on Jetson to deliver advanced spatial-temporal perception and reasoning capabilities.
NVIDIA Isaac GR00T N1.6 is an open vision language action model (VLA) for generalist robot skills. Developers can use it to build robots that perceive their environment, reason about instructions and act across a wide range of tasks, environments and embodiments. On Jetson Thor, the full GR00T N1.6 pipeline executes onboard, delivering real-time perception, spatial awareness and responsive action.
NVIDIA Nemotron: A family of open models, datasets and technologies that empower users to build efficient, accurate and specialized agentic AI systems. It’s designed for advanced reasoning, coding, visual understanding, agentic tasks, safety, speech and information. The Nemotron 3 Nano 9B model effectively runs on Jetson Orin Nano Super with llama.cpp with 9 tokens per second performance.
PI 0.5: A VLA model from Physical Intelligence that enables robots to understand instructions and autonomously execute complex real-world tasks with strong generalization and real-time adaptability, while NVIDIA Jetson Thor delivers 120 action tokens per second to power responsive, low-latency physical AI deployment.
Qwen 3.5: This family of models from Alibaba, including the latest Qwen 3.5 releases, offers a mix of dense and mixture‑of‑experts models that deliver strong reasoning, coding multimodal understanding and long‑context performance. Jetson Thor delivers optimized performance across Qwen models like the Qwen 3.5-35B-A3B model, which reasons at 35 tokens per second, making real-time interactivity possible.
Any developer can fine-tune these models to create specialized physical AI agents and seamlessly deploy them into physical AI systems. The NVIDIA Jetson platform supports popular AI frameworks from NVIDIA TRT, Llama.cpp, Ollama, vLLM, SGLang and more.

Take On Open Models on Jetson
Developers can dive into Hugging Face tutorials — including Deploying Open Source Vision Language Models on Jetson — and catch the latest livestream. Learn from this tutorial and run OpenClaw on NVIDIA Jetson.
Join GTC 2026 next month to see it all in action. NVIDIA will show how open models are moving from data centers into machines operating in the physical world, including in a panel on the Future of Industrial Autonomy.
Watch the GTC keynote from NVIDIA founder and CEO Jensen Huang and explore physical AI, robotics and vision AI sessions.







