

Vector embeddings have become essential for modern Retrieval Augmented Generation (RAG) applications, but organizations face significant cost challenges as they scale. As knowledge bases grow and require more granular embeddings, many vector databases that rely on high-performance storage such as SSDs or in-memory solutions become prohibitively expensive. This cost barrier often forces organizations to limit the scope of their RAG applications or compromise on the granularity of their vector representations, potentially impacting the quality of results. Additionally, for use cases involving historical or archival data that still needs to remain searchable, storing vectors in specialized vector databases optimized for high throughput workloads represents an unnecessary ongoing expense.
Starting July 15, Amazon Bedrock Knowledge Bases customers can select Amazon S3 Vectors (preview), the first cloud object storage with built-in support to store and query vectors at a low cost, as a vector store. Amazon Bedrock Knowledge Bases users can now reduce vector upload, storage, and query costs by up to 90%. Designed for durable and cost-optimized storage of large vector datasets with subsecond query performance, S3 Vectors is ideal for RAG applications that require long-term storage of massive vector volumes and can tolerate the performance tradeoff compared to high queries per second (QPS), millisecond latency vector databases. The integration with Amazon Bedrock means you can build more economical RAG applications while preserving the semantic search performance needed for quality results.
In this post, we demonstrate how to integrate Amazon S3 Vectors with Amazon Bedrock Knowledge Bases for RAG applications. You’ll learn a practical approach to scale your knowledge bases to handle millions of documents while maintaining retrieval quality and using S3 Vectors cost-effective storage.
Amazon Bedrock Knowledge Bases and Amazon S3 Vectors integration overview
When creating a knowledge base in Amazon Bedrock, you can select S3 Vectors as your vector storage option. Using this approach, you can build cost-effective, scalable RAG applications without provisioning or managing complex infrastructure. The integration delivers significant cost savings while maintaining subsecond query performance, making it ideal for working with larger vector datasets generated from massive volumes of unstructured data including text, images, audio, and video. Using a pay-as-you-go pricing model at low price points, S3 Vectors offers industry-leading cost optimization that reduces the cost of uploading, storing, and querying vectors by up to 90% compared to alternative solutions. Advanced search capabilities include rich metadata filtering, so you can refine queries by document attributes such as dates, categories, and sources. The combination of S3 Vectors and Amazon Bedrock is ideal for organizations building large-scale knowledge bases that demand both cost efficiency and performant retrieval—from managing extensive document repositories to historical archives and applications requiring granular vector representations. The walkthrough follows these high-level steps:
- Create a new knowledge base
- Configure the data source
- Configure data source and processing
- Sync the data source
- Test the knowledge base
Prerequisites
Before you get started, make sure that you have the following prerequisites:
- An AWS Account with appropriate service access.
- An AWS Identity and Access Management (IAM) role with the appropriate permissions to access Amazon Bedrock and Amazon Simple Storage Service (Amazon S3).
- Enable model access for embedding and inference models such as Amazon Titan Text Embeddings V2 and Amazon Nova Pro.
Amazon Bedrock Knowledge Bases and Amazon S3 Vectors integration walkthrough
In this section, we walk through the step-by-step process of creating a knowledge base with Amazon S3 Vectors using the AWS Management Console. We cover the end-to-end process from configuring your vector store to ingesting documents and testing your retrieval capabilities.
For those who prefer to configure their knowledge base programmatically rather than using the console, the Amazon Bedrock Knowledge Bases with S3 Vectors repository in GitHub provides a guided notebook that you can follow to deploy the setup in your own account.
Create a new knowledge base
To create a new knowledge base, follow these steps:
- On the Amazon Bedrock console in the left navigation pane, choose Knowledge Bases. To initiate the creation process, in the Create dropdown list, choose Knowledge Base with vector store.
- On the Provide Knowledge Base details page, enter a descriptive name for your knowledge base and an optional description to identify its purpose. Select your IAM permissions approach—either create a new service role or use an existing one—to grant the necessary permissions for accessing AWS services, as shown in the following screenshot.

- Choose Amazon S3. Optionally, add tags to help organize and categorize your resources and configure log delivery destinations such as an S3 bucket or Amazon CloudWatch for monitoring and troubleshooting.
- Choose Next to proceed to the data source configuration.
Configure the data source
To configure the data source, follow these steps:
- Assign a descriptive name to your knowledge base data.
- In Data source location, select whether the S3 bucket exists in your current AWS account or another account, then specify the location where your documents are stored, as shown in the following screenshot.
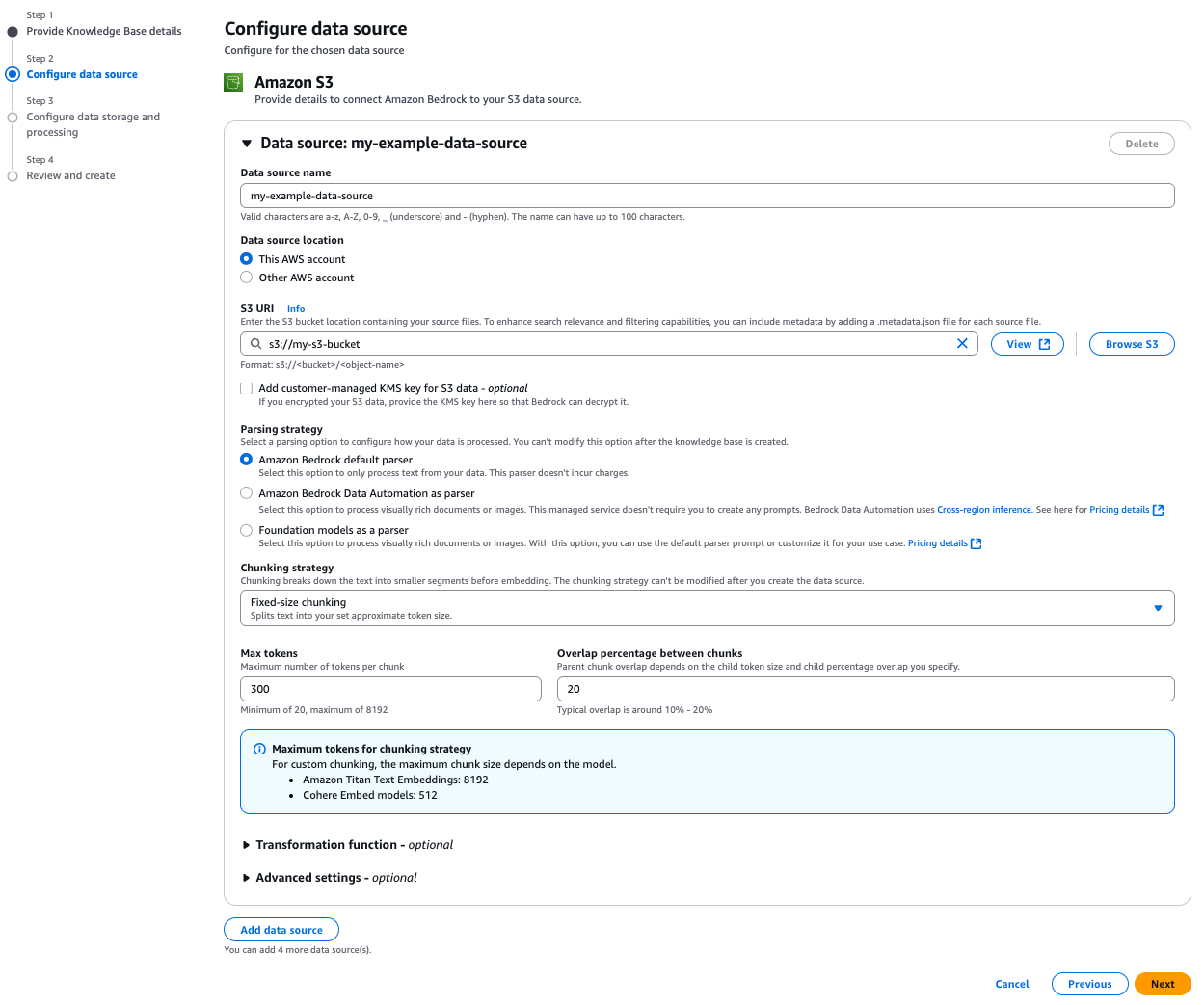
In this step, configure your parsing strategy to determine how Amazon Bedrock processes your documents. Select Amazon Bedrock default parser for text-only documents at no additional cost. Select Amazon Bedrock Data Automation as parser or Foundation models as a parser for processing complex documents with visual elements.
The chunking strategy configuration is equally critical because it defines how your content is segmented into meaningful units for vector embedding, directly impacting retrieval quality and context preservation. We have selected Fixed-size chunking for this example due to its predictable token sizing and simplicity. Because both parsing and chunking decisions can’t be modified after creation, select options that best match your content structure and retrieval needs. For sensitive data, you can use advanced settings to implement AWS Key Management Service (AWS KMS) encryption or apply custom transformation functions to optimize your documents before ingestion. By default, S3 Vectors will use server-side encryption (SSE-S3).
Configure data storage and processing
To configure data storage and processing, first select the embeddings model, as shown in the following screenshot. The embeddings model will transform your text chunks into numerical vector representations for semantic search capabilities. If connecting to an existing S3 Vector as a vector store, make sure the embedding model dimensions match those used when creating your vector store because dimensional mismatches will cause ingestion failures. Amazon Bedrock offers several embeddings models to choose from, each with different vector dimensions and performance characteristics optimized for various use cases. Consider both the semantic richness of the model and its cost implications when making your selection.
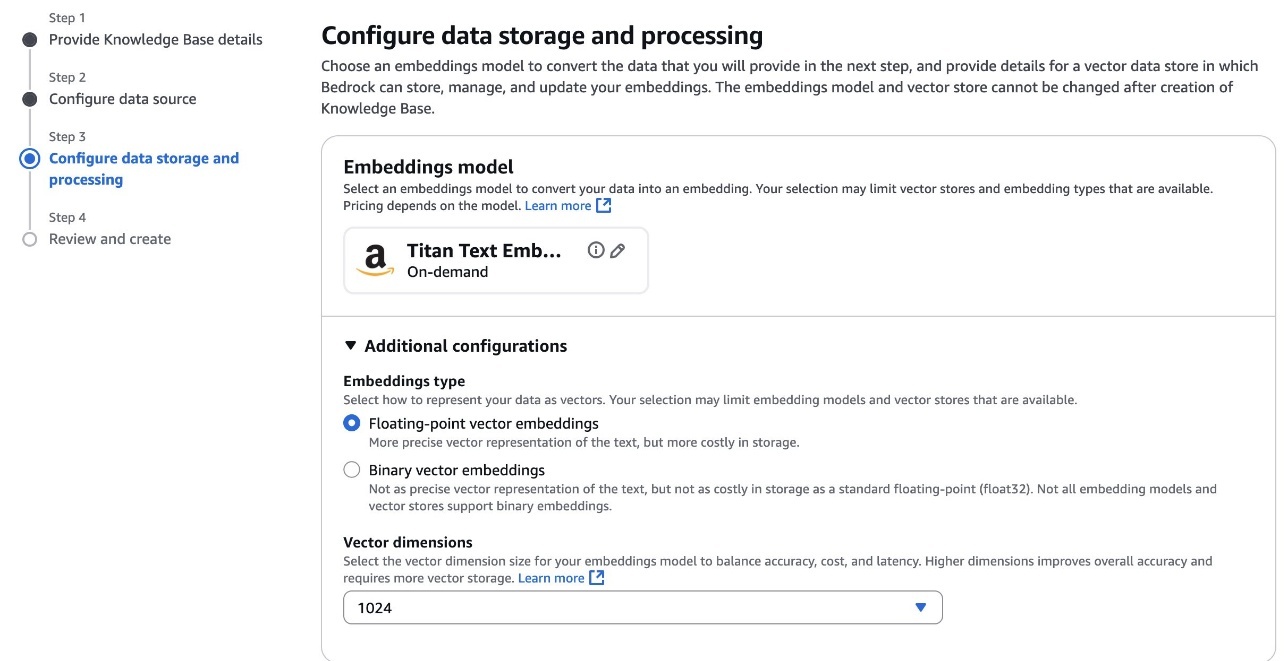
Next, configure the vector store. For vector storage selection, choose how Amazon Bedrock Knowledge Bases will store and manage the vector embeddings generated from your documents in Amazon S3 Vectors, using one of the following two options:
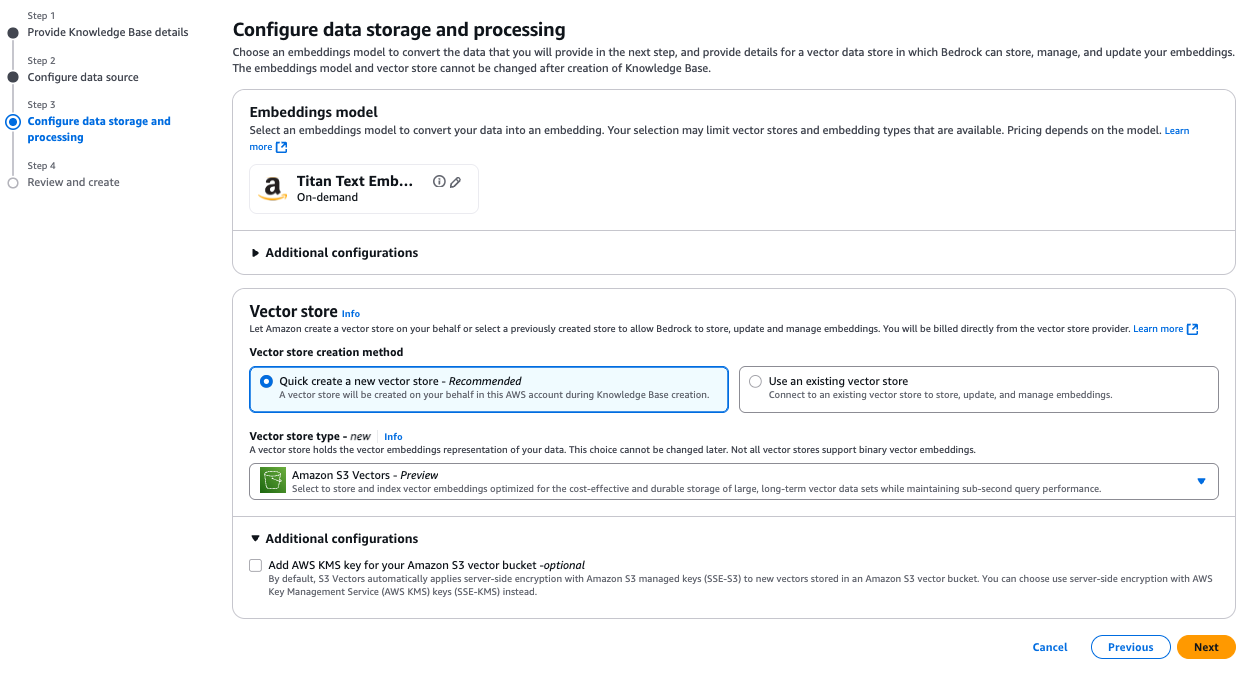
Option 1. Quick create a new vector store
This recommended option, shown in the following screenshot, automatically creates an S3 vector bucket in your account during knowledge base creation. The system optimizes your vector storage for cost-effective, durable storage of large-scale vector datasets, creating an S3 vector bucket and vector index for you.
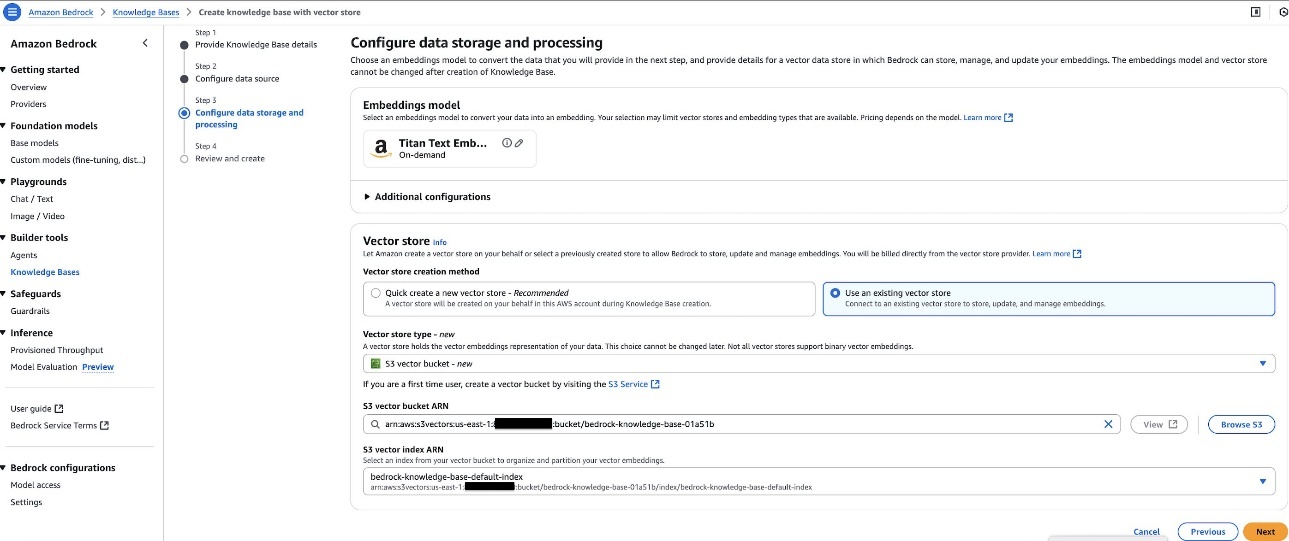
Option 2. Use an existing vector store
When creating your Amazon S3 Vector as a vector store index for use with Amazon Bedrock Knowledge Bases, you can attach metadata (such as, year, author, genre, and location) as key-value pairs to each vector. By default, metadata fields can be used as filters in similarity queries unless specified as nonfilterable metadata at the time of vector index creation. S3 Vector indexes support string, number, and Boolean types up to 40 KB per vector, with filterable metadata capped at 2 KB per vector.
To accommodate larger text chunks and richer metadata while still allowing filtering on other important attributes, add "AMAZON_BEDROCK_TEXT" to the nonFilterableMetadataKeys list in your index configuration. This approach optimizes your storage allocation for document content while preserving filtering capabilities for meaningful attributes like categories or dates. Keep in mind that fields added to the nonFilterableMetadataKeys array can’t be used with metadata filtering in queries and can’t be modified after the index is created.
Here’s an example for creating an Amazon S3 Vector index with proper metadata configuration:
For details on how to create a vector store, refer to Introducing Amazon S3 Vectors in the AWS News Blog.
After you have an S3 Vector bucket and index, you can connect it to your knowledge base. You’ll need to provide both the S3 Vector bucket Amazon Resource Name (ARN) and vector index ARN, as shown in the following screenshot, to correctly link your knowledge base to your existing S3 Vector index.
Sync data source
After you’ve configured your knowledge base with S3 Vectors, you need to synchronize your data source to generate and store vector embeddings. From the Amazon Bedrock Knowledge Bases console, open your created knowledge base and locate your configured data source and choose Sync to initiate the process, as shown in the following screenshot. During synchronization, the system processes your documents according to your parsing and chunking configurations, generates embeddings using your selected model, and stores them in your S3 vector index. You can monitor the synchronization progress in real time if you’ve configured Amazon CloudWatch Logs and verify completion status before testing your knowledge base’s retrieval capabilities.

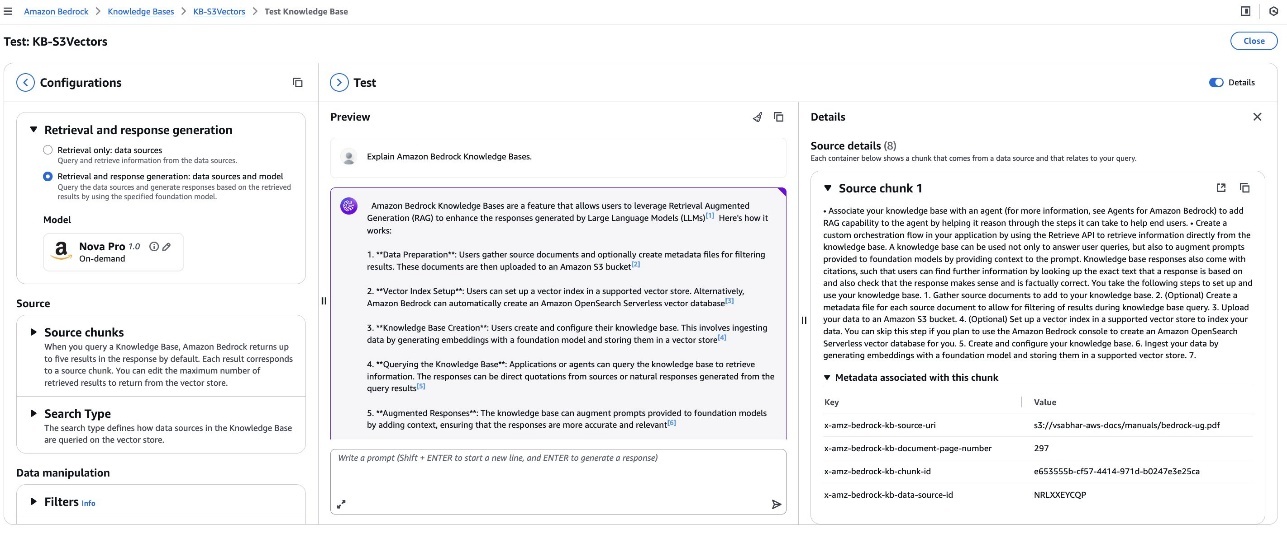
Test the knowledge base
After successfully configuring your knowledge base with S3 Vectors, you can validate its functionality using the built-in testing interface. You can use this interactive console to experiment with different query types and view both retrieval results and generated responses. Select between Retrieval only (Retrieve API) mode to examine raw source chunks or Retrieval and Response generation (RetrieveandGenerate API) to learn how foundation models (FMs) such as Amazon Nova use your retrieved content. The testing interface provides valuable insights into how your knowledge base processes queries, displaying source chunks, their relevance scores, and associated metadata.
You can also configure query settings for your knowledge base just as you would with other vector storage options, including filters for metadata-based selection, guardrails for appropriate responses, reranking capabilities, and query modification options. These tools help optimize retrieval quality and make sure the most relevant information is presented to your FMs. S3 Vectors currently supports semantic search functionality. Using this hands-on validation, you can refine your configuration before integrating the knowledge base with production applications.
Creating your Amazon Bedrock knowledge base programmatically
In the previous sections, we walked through creating a knowledge base with Amazon S3 Vectors using the AWS Management Console. For those who prefer to automate this process or integrate it into existing workflows, you can also create your knowledge base programmatically using the AWS SDK.
The following is a sample code showing how the API call looks when programmatically creating an Amazon Bedrock knowledge base with an existing Amazon S3 Vector index:
The role attached to the knowledge base should have several policies attached to it, including access to the S3 Vectors API, the models used for embedding, generation, and reranking (if used), and the S3 bucket used as data source. If you’re using a customer managed key for your S3 Vector as a vector store, you’ll need to provide an additional policy to allow the decryption of the data. The following is the policy needed to access the Amazon S3 Vector as a vector store:
Cleanup
To clean up your resources, complete the following steps. To delete the knowledge base:
- On the Amazon Bedrock console, choose Knowledge Bases
- Select your Knowledge Base and note both the IAM service role name and S3 Vector index ARN
- Choose Delete and confirm
To delete the S3 Vector as a vector store, use the following AWS Command Line Interface (AWS CLI) commands:
- On the IAM console, find the role noted earlier
- Select and delete the role
To delete the sample dataset:
- On the Amazon S3 console, find your S3 bucket
- Select and delete the files you uploaded for this tutorial
Conclusion
The integration between Amazon Bedrock Knowledge Bases and Amazon S3 Vectors represents a significant advancement in making RAG applications more accessible and economically viable at scale. By using the cost-optimized storage of Amazon S3 Vectors, organizations can now build knowledge bases at scale with improved cost efficiency. This means customers can strike an optimal balance between performance and economics, and you can focus on creating value through AI-powered applications rather than managing complex vector storage infrastructure.
To get started on Amazon Bedrock Knowledge Bases and Amazon S3 Vectors integration, refer to Using S3 Vectors with Amazon Bedrock Knowledge Bases in the Amazon S3 User Guide.
About the authors
 Vaibhav Sabharwal is a Senior Solutions Architect with Amazon Web Services (AWS) based out of New York. He is passionate about learning new cloud technologies and assisting customers in building cloud adoption strategies, designing innovative solutions, and driving operational excellence. As a member of the Financial Services Technical Field Community at AWS, he actively contributes to the collaborative efforts within the industry.
Vaibhav Sabharwal is a Senior Solutions Architect with Amazon Web Services (AWS) based out of New York. He is passionate about learning new cloud technologies and assisting customers in building cloud adoption strategies, designing innovative solutions, and driving operational excellence. As a member of the Financial Services Technical Field Community at AWS, he actively contributes to the collaborative efforts within the industry.
 Dani Mitchell is a Generative AI Specialist Solutions Architect at Amazon Web Services (AWS). He is focused on helping accelerate enterprises across the world on their generative AI journeys with Amazon Bedrock.
Dani Mitchell is a Generative AI Specialist Solutions Architect at Amazon Web Services (AWS). He is focused on helping accelerate enterprises across the world on their generative AI journeys with Amazon Bedrock.
 Irene Marban is a Generative AI Specialist Solutions Architect at Amazon Web Services (AWS), working with customers across EMEA to design and implement generative AI solutions to accelerate their businesses. With a background in biomedical engineering and AI, her work focuses on helping organizations leverage the latest AI technologies to drive innovation and growth. In her spare time, she loves reading and cooking for her friends.
Irene Marban is a Generative AI Specialist Solutions Architect at Amazon Web Services (AWS), working with customers across EMEA to design and implement generative AI solutions to accelerate their businesses. With a background in biomedical engineering and AI, her work focuses on helping organizations leverage the latest AI technologies to drive innovation and growth. In her spare time, she loves reading and cooking for her friends.
 Ashish Lal is an AI/ML Senior Product Marketing Manager for Amazon Bedrock. He has over 11 years of experience in product marketing and enjoys helping customers accelerate time to value and reduce their AI lifecycle cost.
Ashish Lal is an AI/ML Senior Product Marketing Manager for Amazon Bedrock. He has over 11 years of experience in product marketing and enjoys helping customers accelerate time to value and reduce their AI lifecycle cost.
")




")

