

Amazon Nova Multimodal Embeddings processes text, documents, images, video, and audio through a single model architecture. Available through Amazon Bedrock, the model converts different input modalities into numerical embeddings within the same vector space, supporting direct similarity calculations regardless of content type. We developed this unified model to reduce the need for separate embedding models, which complicate architectures, are difficult to maintain and operate, and further limit use cases to a one-dimensional approach.
In this post, we explore how Amazon Nova Multimodal Embeddings addresses the challenges of crossmodal search through a practical ecommerce use case. We examine the technical limitations of traditional approaches and demonstrate how Amazon Nova Multimodal Embeddings enables retrieval across text, images, and other modalities. You learn how to implement a crossmodal search system by generating embeddings, handling queries, and measuring performance. We provide working code examples and share how to add these capabilities to your applications.
The search problem
Traditional approaches involve keyword-based search, text embeddings-based natural language search, or hybrid search and can’t process visual queries effectively, creating a gap between user intent and retrieval capabilities. Typical search architectures separate visual and textual processing, losing context in the process. Text queries execute against product descriptions using keyword matching or text embeddings. Image queries, when supported, operate through multiple computer vision pipelines with limited integration to textual content. This separation complicates system architecture and weaken the user experience. Multiple embedding models require separate maintenance and optimization cycles, while crossmodal queries cannot be processed natively within a single system. Visual and textual similarity scores operate in different mathematical spaces, making it difficult to rank results consistently across content types. This separation requires complex mapping that can’t always be done, so embedding systems are kept separately, creating data silos in the process and limiting functionality. Complex product content further complicates it, because product pages combine images, descriptions, specifications, and sometimes video demonstrations.
Crossmodal embeddings
Crossmodal embeddings map text, images, audio, and video into a shared vector space where semantically similar content clusters together. For example, when processing a text query red summer dress and an image of a red dress, both inputs generate vectors close together in the embedding space, reflecting their semantic similarity and unlocking crossmodal retrieval.
By using crossmodal embeddings, you can search across different content types without maintaining separate systems for each modality, solving the problem of segmented multimodal systems where organizations manage multiple embedding models that are nearly impossible to integrate effectively because embeddings from different modalities are incompatible. A single model architecture helps ensure that you have consistent embedding generation across all content types while related content, such as product images, videos, and their descriptions, generates similar embeddings because of joint training objectives. Applications can generate embeddings for all content types using identical API endpoints and vector dimensions, reducing system complexity.
Use case: Ecommerce search
Consider a customer who sees a shirt on TV and wants to find similar items for purchase. They can photograph the item with their phone or try to describe what they saw in text and use this to search for a product. Traditional search handles text queries that reference metadata reasonably well but cannot execute when customers want to use images for search or describe visual attributes of an item. This TV-to-cart shopping experience shows how visual and text search work together. The customer uploads a photo, and the system matches it against product catalogs with both images and descriptions. The crossmodal ecommerce workflow is shown in the following figure.
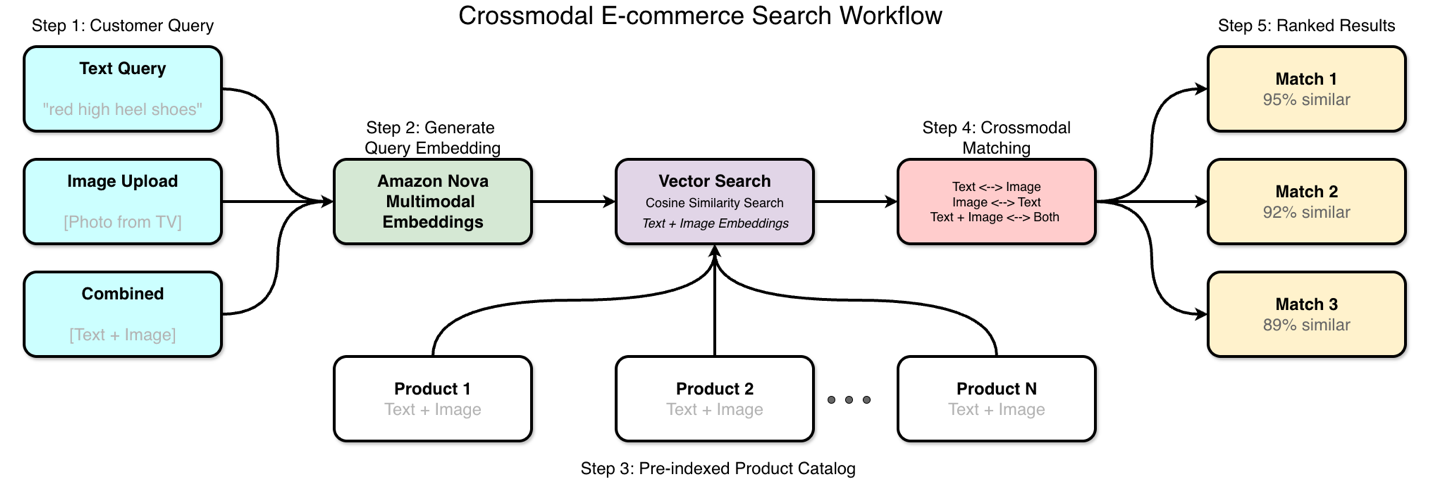
How Amazon Nova Multimodal Embeddings helps
Amazon Nova handles different types of search queries through the same model, which creates both new search capabilities and technical advantages. Whether you upload images, enter descriptions using text, or combine both, the process works the same way.
Crossmodal search capabilities
As previously stated, Amazon Nova Multimodal Embeddings processes all supported modalities through a unified model architecture. Input content can be text, images, documents, video, or audio and then it generates embeddings in the same vector space. This supports direct similarity calculations between different content types without additional transformation layers. When customers upload images, the system converts them into embeddings and searches against the product catalog using cosine similarity. You get products with similar visual characteristics, regardless of how they’re described in text. Text queries work the same way—customers can describe what they want and find visually similar products, even when the product descriptions use different words. If the customer uploads an image with a text description, the system processes both inputs through the same embedding model for unified similarity scoring. The system also extracts product attributes from images automatically through automated product tagging, supporting semantic tag generation that goes beyond manual categorization.
Technical advantages
The unified architecture has several benefits over separate text and image embeddings. The single-model design and shared semantic space unlocks new use cases that aren’t attainable by managing multiple embedding systems. Applications generate embeddings for all content types using the same API endpoints and vector dimensions. A single model handles all five modalities, so related content, such as product images and their descriptions, produce similar embeddings. You can calculate distances between any combination of text, images, audio, and video to measure how similar they are.
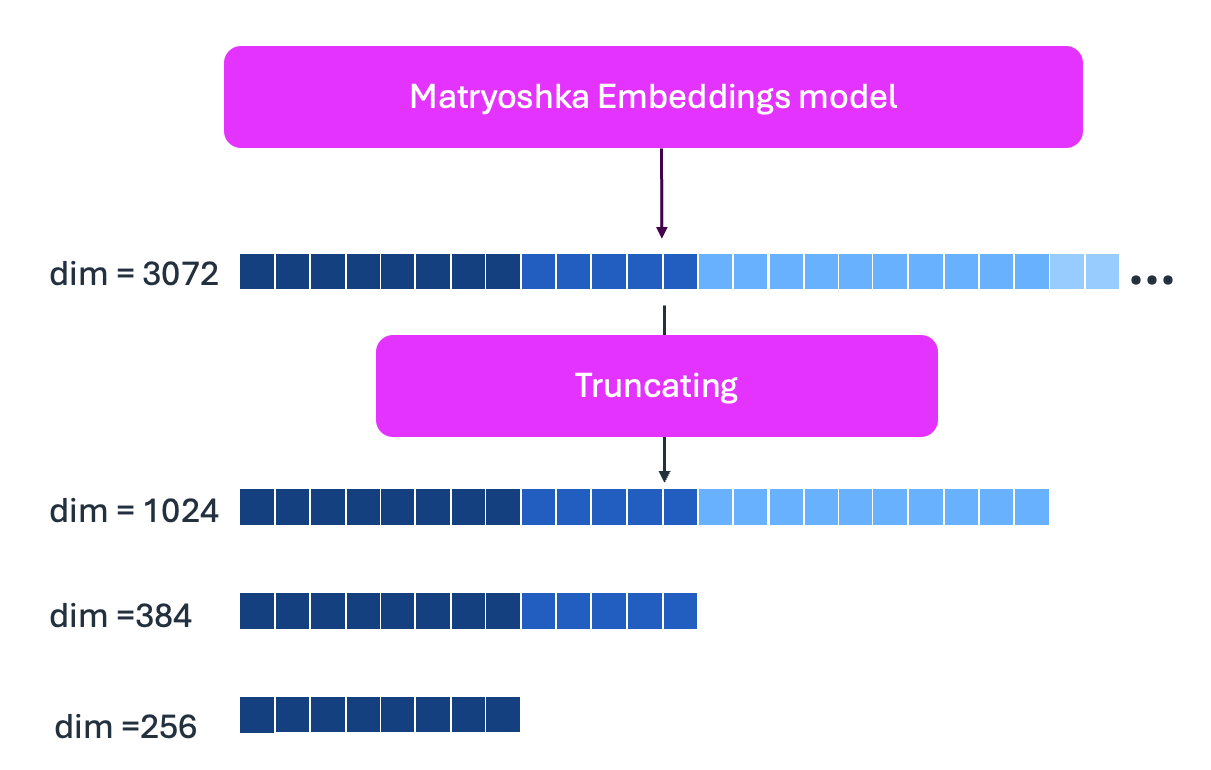
The Amazon Nova Multimodal Embeddings model uses Matryoshka representation learning, supporting multiple embedding dimensions: 3072, 1024, 384, and 256. Matryoshka embedding learning stores the most important information in the first dimensions and less critical details in later dimensions. You can truncate from the end (shown in the following figure) to reduce storage space while maintaining accuracy for your specific use case.
Architecture
Three main components are required to build this approach: embedding generation, vector storage, and similarity search. Product catalogs undergo preprocessing to generate embeddings for all content types. Query processing converts user inputs into embeddings using the same model. Similarity search compares query embeddings against stored product embeddings, as shown in the following figure.
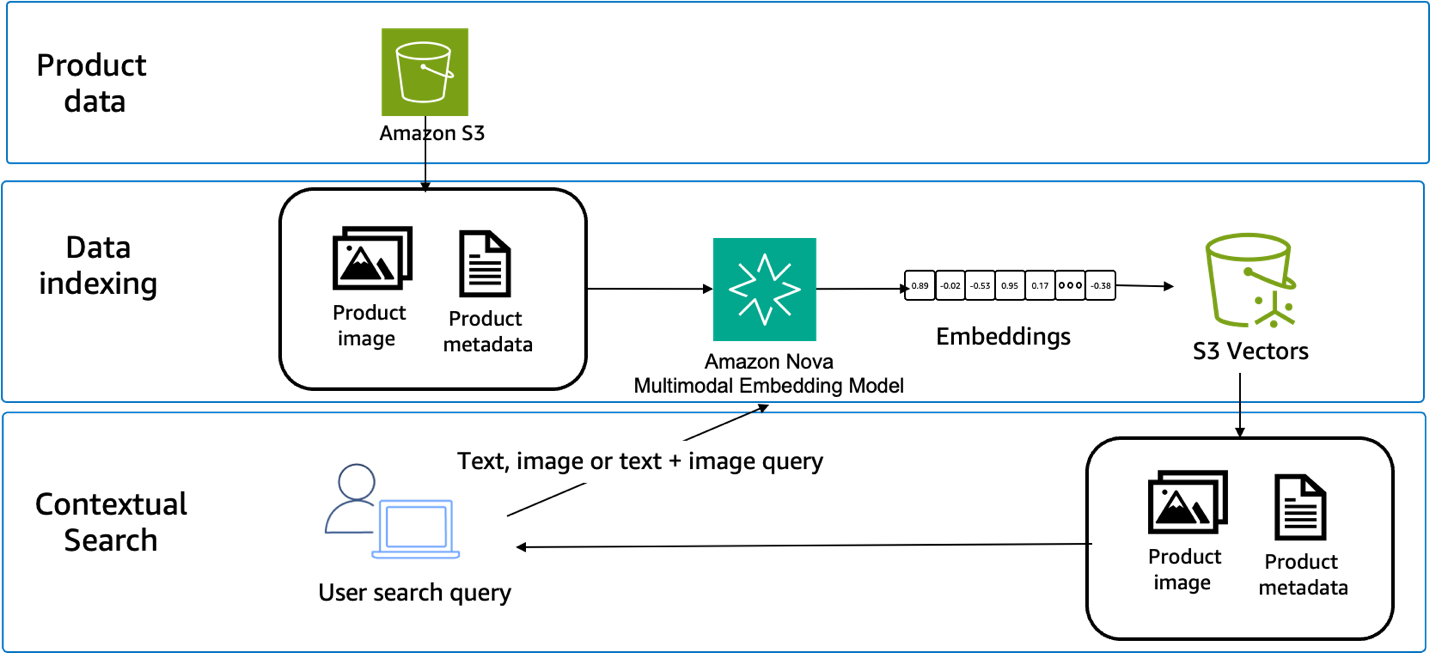
Vector storage systems must support the chosen embedding dimensions and provide efficient similarity search operations. Options include purpose-built vector databases, traditional databases with vector extensions, or cloud-centered vector services such as Amazon S3 Vectors, a feature of Amazon S3 that provides native support for storing and querying vector embeddings directly within S3.
Prerequisites
To use the feature effectively, there are some key aspects required for this implementation. An AWS account with Amazon Bedrock access permissions for the Amazon Nova Multimodal Embeddings model. Additional services required include S3 Vectors. You can follow along in the notebook available in our Amazon Nova samples repository.
Implementation
In the following sections, we skip the initial data download and extraction steps, but the end-to-end approach is available for you to follow along in this notebook. The omitted steps include downloading the Amazon Berkeley Objects (ABO) dataset archives, which include product metadata, catalog images, and 3D models. These archives require extraction and preprocessing to parse approximately 398,212 images and 9,232 product listings from compressed JSON and tar files. After being extracted, the data requires metadata alignment between product descriptions and their corresponding visual assets. We begin this walk through after these preliminary steps are complete, focusing on the core workflow: setting up S3 Vectors, generating embeddings with Amazon Nova Multimodal Embeddings, storing vectors at scale, and implementing crossmodal retrieval. Let’s get started.
S3 Vector bucket and index creation:
Create the vector storage infrastructure for embeddings. S3 Vectors is a managed service for storing and querying high-dimensional vectors at scale. The bucket acts as a container for your vector data, while the index defines the structure and search characteristics. We configure the index with cosine distance metric, which measures similarity based on vector direction rather than magnitude, making it ideal for normalized embeddings from models provided by services such as Amazon Nova Multimodal Embeddings.
Product catalog preprocessing:
Here we generate embeddings. Both product images and textual descriptions require embedding generation and storage with appropriate metadata for retrieval. The Amazon Nova Embeddings API processes each modality independently, converting text descriptions and product images into 1024-dimensional vectors. These vectors live in a unified semantic space, which means a text embedding and an image embedding of the same product will be geometrically close to each other.
We use the following code to generate the embeddings and upload the data to our vector store.
Query processing:
This code handles customer input through the API. Text queries, image uploads, or combinations convert into the same vector format used for your product catalog. For multimodal queries that combine text and image, we apply mean fusion to create a single query vector that captures information from both modalities. The query processing logic handles three distinct input types and prepares the appropriate embedding representation for similarity search against the S3 Vectors index.
Vector similarity search:
Next, we add crossmodal retrieval using the S3 Vectors query API. The system finds the closest embedding match to the query, regardless of whether it was text or an image. We use cosine similarity as the distance metric, which measures the angle between vectors rather than their absolute distance. This approach works well for normalized embeddings and is resource efficient, making it suitable for large catalogs when paired with approximate nearest neighbor algorithms. S3 Vectors handles the indexing and search infrastructure, so you can focus on the application logic while the service manages scalability and performance optimization.
Result ranking:
The similarity scores computed by S3 Vectors provide the ranking mechanism. Cosine similarity between query and catalog embeddings determines result order, with higher scores indicating better matches. In production systems, you would typically collect click-through data and relevance judgments to validate that the ranking correlates with actual user behavior. S3 Vectors returns distance values which we convert to similarity scores (1 – distance) for intuitive interpretation where higher values indicate closer matches.
Conclusion
Amazon Nova Multimodal Embeddings solves the core problem of crossmodal search by using one model instead of managing separate systems. You can use Amazon Nova Multimodal Embeddings to build search that works whether customers upload images, enter descriptions as text, or combine both approaches.
The implementation is straightforward using Amazon Bedrock APIs, and the Matryoshka embedding dimensions let you optimize for your specific accuracy and cost requirements. If you’re building ecommerce search, content discovery, or an application where users interact with multiple content types, this unified approach reduces both development complexity and operational overhead.
Matryoshka representation learning maintains embedding quality across different dimensions [2]. Performance degradation follows predictable patterns, allowing applications to optimize for specific use cases.
Next steps
Amazon Nova Multimodal Embeddings is available in Amazon Bedrock. See Using Nova Embeddings for API references, code examples, and integration patterns for common architectures.
The AWS samples repository contains implementation examples for multimodal embeddings.
Walk through this specific ecommerce example notebook here
About the authors
 Tony Santiago is a Worldwide Partner Solutions Architect at AWS, dedicated to scaling generative AI adoption across Global Systems Integrators. He specializes in solution building, technical go-to-market alignment, and capability development—enabling tens of thousands of builders at GSI partners to deliver AI-powered solutions for their customers. Drawing on more than 20 years of global technology experience and a decade with AWS, Tony champions practical technologies that drive measurable business outcomes. Outside of work, he’s passionate about learning new things and spending time with family.
Tony Santiago is a Worldwide Partner Solutions Architect at AWS, dedicated to scaling generative AI adoption across Global Systems Integrators. He specializes in solution building, technical go-to-market alignment, and capability development—enabling tens of thousands of builders at GSI partners to deliver AI-powered solutions for their customers. Drawing on more than 20 years of global technology experience and a decade with AWS, Tony champions practical technologies that drive measurable business outcomes. Outside of work, he’s passionate about learning new things and spending time with family.
 Adewale Akinfaderin is a Sr. Data Scientist–Generative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in physics and a doctorate in engineering.
Adewale Akinfaderin is a Sr. Data Scientist–Generative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in physics and a doctorate in engineering.
 Sharon Li is a solutions architect at AWS, based in the Boston, MA area. She works with enterprise customers, helping them solve difficult problems and build on AWS. Outside of work, she likes to spend time with her family and explore local restaurants.
Sharon Li is a solutions architect at AWS, based in the Boston, MA area. She works with enterprise customers, helping them solve difficult problems and build on AWS. Outside of work, she likes to spend time with her family and explore local restaurants.
 Sundaresh R. Iyer is a Partner Solutions Architect at Amazon Web Services (AWS), where he works closely with channel partners and system integrators to design, scale, and operationalize generative AI and agentic architectures. With over 15 years of experience spanning product management, developer platforms, and cloud infrastructure, he specializes in machine learning and AI-powered developer tooling. Sundaresh is passionate about helping partners move from experimentation to production by building secure, governed, and scalable AI systems that deliver measurable business outcomes.
Sundaresh R. Iyer is a Partner Solutions Architect at Amazon Web Services (AWS), where he works closely with channel partners and system integrators to design, scale, and operationalize generative AI and agentic architectures. With over 15 years of experience spanning product management, developer platforms, and cloud infrastructure, he specializes in machine learning and AI-powered developer tooling. Sundaresh is passionate about helping partners move from experimentation to production by building secure, governed, and scalable AI systems that deliver measurable business outcomes.

")




")
