

This post is co-written with Bogdan Arsenie and Nick Mattei from PerformLine.
PerformLine operates within the marketing compliance industry, a specialized subset of the broader compliance software market, which includes various compliance solutions like anti-money laundering (AML), know your customer (KYC), and others. Specifically, marketing compliance refers to adhering to regulations and guidelines set by government agencies that make sure a company’s marketing, advertising, and sales content and communications are truthful, accurate, and not misleading for consumers. PerformLine is the leading service providing comprehensive compliance oversight across marketing, sales, and partner channels. As pioneers of the marketing compliance industry, PerformLine has conducted over 1.1 billion compliance observations over the past 10+ years, automating the entire compliance process—from pre-publication review of materials to continuous monitoring of consumer-facing channels such as websites, emails, and social media. Trusted by consumer finance brands and global organizations, PerformLine uses AI-driven solutions to protect brands and their consumers, transforming compliance efforts into a competitive advantage.
“Discover. Monitor. Act. This isn’t just our tagline—it’s the foundation of our innovation at PerformLine,” says PerformLine’s CTO Bogdan Arsenie. PerformLine’s engineering team brings these principles to life by developing AI-powered technology solutions. In this post, PerformLine and AWS explore how PerformLine used Amazon Bedrock to accelerate compliance processes, generate actionable insights, and provide contextual data—delivering the speed and accuracy essential for large-scale oversight.
The problem
One of PerformLine’s enterprise customers needed a more efficient process for running compliance checks on newly launched product pages, particularly those that integrate multiple products within the same visual and textual framework. These complex pages often feature overlapping content that can apply to one product, several products, or even all of them at once, necessitating a context-aware interpretation that mirrors how a typical consumer would view and interact with the content. By adopting AWS and the architecture discussed in this post, PerformLine can retrieve and analyze these intricate pages through AI-driven processing, generating detailed insights and contextual data that capture the nuanced interplay between various product elements. After the relevant information is extracted and structured, it’s fed directly into their rules engine, enabling robust compliance checks. This accomplishes a seamless flow, from data ingestion to rules-based analysis. It not only preserves the depth of each product’s presentation but also delivers the speed and accuracy critical to large-scale oversight. Monitoring millions of webpages daily for compliance demands a system that can intelligently parse, extract, and analyze content at scale—much like the approach PerformLine has developed for their enterprise customers. In this dynamic landscape, the ever-evolving nature of web content challenges traditional static parsing, requiring a context-aware and adaptive solution. This architecture not only processes bulk data offline but also delivers near real-time performance for one-time requests, dynamically scaling to manage the diverse complexity of each page. By using AI-powered inference, PerformLine provides comprehensive coverage of every product and marketing element across the web, while striking a careful balance between accuracy, performance, and cost.
Solution overview
With this flexible, adaptable solution, PerformLine can tackle even the most challenging webpages, providing comprehensive coverage when extracting and analyzing web content with multiple products. At the same time, by combining consistency with the adaptability of foundation models (FMs), PerformLine can maintain reliable performance across the diverse range of products and websites their customers monitor. This dual focus on agility and operational consistency makes sure their customers benefit from robust compliance checks and data integrity, without sacrificing the speed or scale needed to remain competitive.
PerformLine’s upstream ingestion pipeline efficiently collects millions of web pages and their associated metadata in a batch process. Downstream assets are submitted to PerformLine’s rules engine and compliance review processes. It was imperative that they not disrupt those processes or introduce cascading changes for this solution.
PerformLine decided to use generative AI and Amazon Bedrock to address their core challenges. Amazon Bedrock allows for a broad selection of models, including Amazon Nova. Amazon Bedrock is continuously expanding feature sets around using FMs at scale. This provides a reliable foundation to build a highly available and efficient content processing system.
PerformLine’s solution incorporates the following key components:
- AI inference with Amazon Bedrock – Provides seamless access to FMs for content extraction and analysis
- Application inference profiles – Enables precise tracking and optimization of inference costs
- Event-driven serverless processing pipeline –Provides a lightweight, scalable approach to handling dynamic workloads using Amazon EventBridge, Amazon Simple Queue Service (Amazon SQS), AWS Lambda, Amazon Simple Storage Service (Amazon S3), and Amazon DynamoDB.
- Prompt management in Bedrock – Supports versioning, testing, and deployment of prompts for improved AI consistency and control
- Task orchestration – Uses Amazon SQS to manage work queues efficiently, facilitating smooth and scalable task execution
PerformLine implemented a scalable, serverless event-driven architecture (shown in the following diagram) that seamlessly integrates with their existing system, requiring less than a day to develop and deploy. This made it possible to focus on prompt optimization, evaluation, and cost management rather than infrastructure overhead. This architecture allows PerformLine to dynamically parse, extract, and analyze web content with high reliability, flexibility, and cost-efficiency.
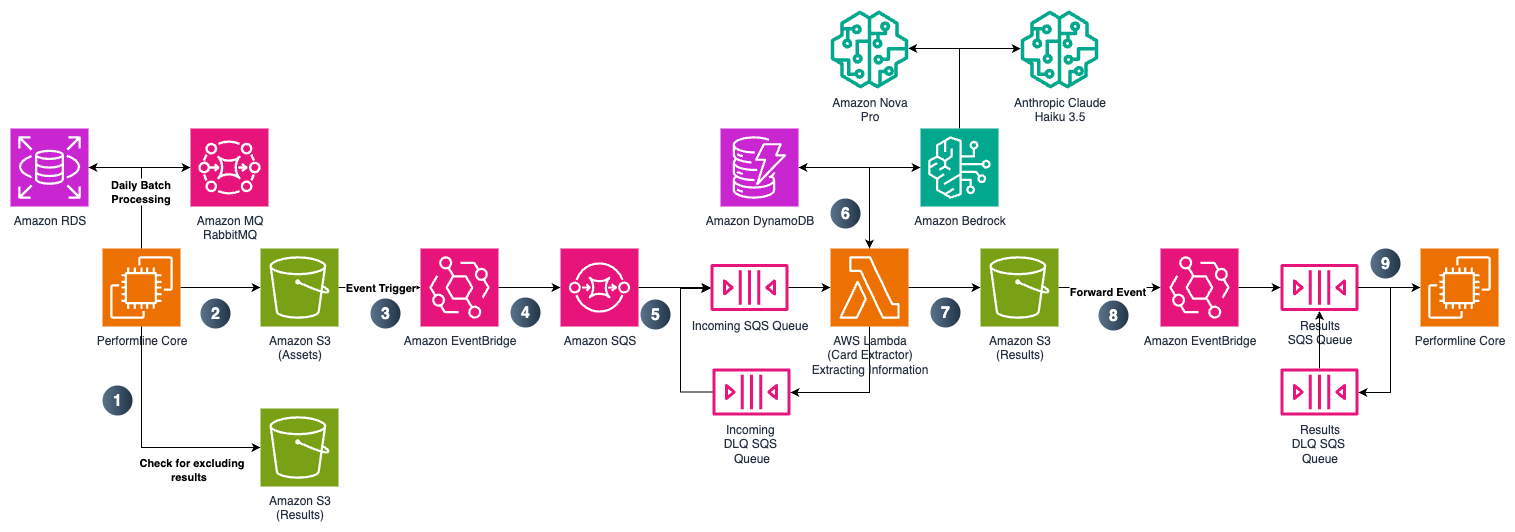
The system implements multiple queue types (Incoming, DLQ, Results) and includes error handling mechanisms. Data flows through various AWS services including: Amazon RDS for initial data storage Amazon MQ RabbitMQ for message handling Amazon S3 for asset storage Amazon EventBridge for event management Amazon SQS for queue management AWS Lambda for serverless processing Amazon DynamoDB for NoSQL data storage
PerformLine’s process consists of several steps, including processing (Step 1), event trigger and storage (Steps 2–6), structured output and storage (Step 7), and downstream processing and compliance checks (Steps 8–9):
- Millions of pages are processed by an upstream extract, transform, and load (ETL) process from PerformLine’s core systems running on the AWS Cloud.
- When a page is retrieved, it triggers an event in the compliance check system.
- Amazon S3 allows for storage of the data from a page according to metadata.
- EventBridge uses event-driven processing to route Amazon S3 events to Amazon SQS.
- Amazon SQS queues messages for processing and enables messages to be retried on failure.
- A Lambda Function consumes SQS messages and also scales dynamically to handle even unpredictable workloads:
- This function uses Amazon Bedrock to perform extraction and generative AI analysis of the content from Amazon SQS. Amazon Bedrock offers the greatest flexibility to choose the right model for the job. For PerformLine’s use case, Amazon’s Nova Pro was best suited for complex requests that require a powerful model but still allows for a high performance to cost ratio. Anthropic’s Claude Haiku model allows for optimized quick calls, where a fast response is paramount for additional processing if needed. Amazon Bedrock features, including Amazon Bedrock Prompt Management and inference profiles are used to increase input code variability without affecting output and reduce complexity in usage of FMs through Amazon Bedrock.
- The function stores customer-defined product schemas in Amazon DynamoDB, enabling dynamic large language model (LLM) targeting and schema-driven output generation.
- Amazon S3 stores the extracted data, which is formatted as structured JSON adhering to the target schema.
- EventBridge forwards Amazon S3 events to Amazon SQS, making extracted data available for downstream processing.
- Compliance checks and business rules, running on other PerformLine’s systems, are applied to validate and enforce regulatory requirements.
Cost optimizations
The solution offers several cost optimizations, including change data capture (CDC) on the web and strategic multi-pass inference. After a page’s content has been analyzed and formatted, it’s written back to a partition that includes a metadata hash of the asset. This enables upstream processes to determine whether a page has already been processed and if its content has changed. The key benefits of this approach include:
- Alleviating redundant processing of the same pages, contributing to PerformLine experiencing a 15% workload reduction in human evaluation tasks. This frees time for human evaluators and allows them focus on critical pages rather than all the pages.
- Avoiding reprocessing unchanged pages, dynamically reducing PerformLine’s analysts’ workload by over 50% in addition to deduplication gains.
LLM inference costs can escalate at scale, but context and carefully structured prompts are critical for accuracy. To optimize costs while maintaining precision, PerformLine implemented a multi-pass approach using Amazon Bedrock:
- Initial filtering with Amazon Nova Micro – This lightweight model efficiently identifies relevant products with minimal cost.
- Targeted extraction with Amazon Nova Lite – Identified products are batched into smaller groups and passed to Amazon Nova Lite for deeper analysis. This keeps PerformLine within token limits while improving extraction accuracy.
- Increased accuracy through context-aware processing – By first identifying the target content and then processing it in smaller batches, PerformLine significantly improved accuracy while minimizing token consumption.
Use of Amazon Bedrock
During initial testing, PerformLine quickly realized the need for a more scalable approach to prompt management. Manually tracking multiple prompt versions and templates became inefficient as PerformLine iterated and collaborated.
Amazon Bedrock’s Prompt Management service provided a centralized solution, enabling them to version, manage, and seamlessly deploy prompts to production. After the prompts are deployed, they can be dynamically referenced in AWS Lambda, allowing for flexible configuration. Additionally, by using Amazon Bedrock application profile inference endpoints, PerformLine can dynamically adjust the models the Lambda function invokes, track cost per invocation, and attribute costs to specific application instances through setting up cost tags.
To streamline model interactions, PerformLine chose the Amazon Bedrock Converse API which provides a developer-friendly, standardized interface for model invocation. When combined with inference endpoints and prompt management, a Lambda function using the Amazon Bedrock Converse API becomes highly configurable—PerformLine developers can rapidly test new models and prompts, evaluate results, and iterate without needing to rebuild or redeploy. The simplification of prompt management and ability to deploy various models through Amazon Bedrock is shown in the following diagram.
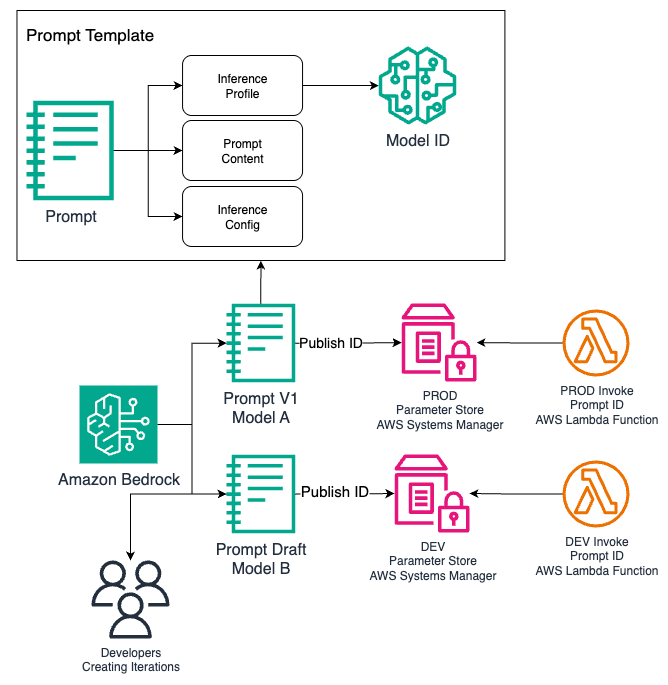
Comprehensive AWS ML model configuration architecture highlighting three main components: Inference System: Model ID integration Profile configuration Content management Inference settings Prompt Management: Version control (V1 and Draft versions) Publish ID tracking Model A specifications Store configurations Environment Control: Separate PROD and DEV paths Environment-specific parameter stores Invoke ID management Engineering iteration tracking
Future plans and enhancements
PerformLine is excited to dive into additional Amazon Bedrock features, including prompt caching and Amazon Bedrock Flows.
With prompt caching, users can checkpoint prompt tokens, effectively caching context for reuse in subsequent API calls. Prompt caching on Amazon Bedrock offers up to 85% latency improvements and 90% cost reduction in comparison to calls without prompt caching. PerformLine sees prompt caching as a feature that will become the standard moving forward. They have a number of use cases for their data, and having the ability to apply further analysis on the same content at a lower cost creates new opportunities for feature expansion and development.
Amazon Bedrock Flows is a visual workflow builder that enables users to orchestrate multi-step generative AI tasks by connecting FMs and APIs without extensive coding. Amazon Bedrock Flows is a next step in simplifying PerformLine’s orchestration of knowledge bases, prompt caching, and even Amazon Bedrock agents in the future. Creating flows can help reduce time to feature deployment and maintenance.
Summary
PerformLine has implemented a highly scalable, serverless, AI-driven architecture that enhances efficiency, cost-effectiveness, and compliance in the web content processing pipeline. By using Amazon Bedrock, EventBridge, Amazon SQS, Lambda, and DynamoDB, they have built a solution that can dynamically scale, optimize AI inference costs, and reduce redundant processing—all while maintaining operational flexibility and compliance integrity. Based on their current volume and workflow, PerformLine is projected to process between 1.5 to 2 million pages daily, from which they expect to extract approximately 400,000 to 500,000 products. Additionally, PerformLine anticipates applying rules to each asset, resulting in about 500,000 rule observations that will require review each day.Throughout the design process PerformLine made sure their solution remains as simple as possible while still delivering operational flexibility and integrity. This approach minimizes complexity, enhances maintainability, and accelerates deployment, empowering them to adapt quickly to evolving business needs without unnecessary overhead.
By using a serverless AI-driven architecture built on Amazon Bedrock, PerformLine helps their customers tackle even the most complex, multi-product webpages with unparalleled accuracy and efficiency. This holistic approach interprets visual and textual elements as a typical consumer would, verifying that every product variant is accurately assessed for compliance. The resulting insights are then fed directly into a rules engine, enabling rapid, data-driven decisions. For PerformLine’s customers, this means less redundant processing, lower operational costs, and a dramatically simplified compliance workflow, all without compromising on speed or accuracy. By reducing the overhead of large-scale data analysis and streamlining compliance checks, PerformLine’s solution ultimately frees teams to focus on driving innovation and delivering value.
About the authors
 Bogdan Arsenie is the Chief Technology Officer at PerformLine, with over two decades of experience leading technological innovation across digital advertising, big data, mobile gaming, and social engagement. Bogdan began programming at age 13, customizing bulletin board software to fund his passion for Star Trek memorabilia. He served as PerformLine’s founding CTO from 2007–2009, pioneering their initial compliance platform. Later, as CTO at the Rumie Initiative, he helped scale a global education initiative recognized by Google’s Impact Challenge.
Bogdan Arsenie is the Chief Technology Officer at PerformLine, with over two decades of experience leading technological innovation across digital advertising, big data, mobile gaming, and social engagement. Bogdan began programming at age 13, customizing bulletin board software to fund his passion for Star Trek memorabilia. He served as PerformLine’s founding CTO from 2007–2009, pioneering their initial compliance platform. Later, as CTO at the Rumie Initiative, he helped scale a global education initiative recognized by Google’s Impact Challenge.
 Nick Mattei is a Senior Software Engineer at PerformLine. He is focused on solutions architecture and distributed application development in AWS. Outside of work, Nick is an avid cyclist and skier, always looking for the next great climb or powder day.
Nick Mattei is a Senior Software Engineer at PerformLine. He is focused on solutions architecture and distributed application development in AWS. Outside of work, Nick is an avid cyclist and skier, always looking for the next great climb or powder day.
 Shervin Suresh is a Generative AI Solutions Architect at AWS. He supports generative AI adoption both internally at AWS and externally with fast-growing startup customers. He is passionate about using technology to help improve the lives of people in all aspects. Outside of work, Shervin loves to cook, build LEGO, and collaborate with people on things they are passionate about.
Shervin Suresh is a Generative AI Solutions Architect at AWS. He supports generative AI adoption both internally at AWS and externally with fast-growing startup customers. He is passionate about using technology to help improve the lives of people in all aspects. Outside of work, Shervin loves to cook, build LEGO, and collaborate with people on things they are passionate about.
 Medha Aiyah is a Solutions Architect at AWS. She graduated from the University of Texas at Dallas with an MS in Computer Science, with a focus on AI/ML. She supports ISV customers in a wide variety of industries, by empowering customers to use AWS optimally to achieve their business goals. She is especially interested in guiding customers on ways to implement AI/ML solutions and use generative AI. Outside of work, Medha enjoys hiking, traveling, and dancing.
Medha Aiyah is a Solutions Architect at AWS. She graduated from the University of Texas at Dallas with an MS in Computer Science, with a focus on AI/ML. She supports ISV customers in a wide variety of industries, by empowering customers to use AWS optimally to achieve their business goals. She is especially interested in guiding customers on ways to implement AI/ML solutions and use generative AI. Outside of work, Medha enjoys hiking, traveling, and dancing.
 Michael Zhang is a generalist Solutions Architect at AWS working with small to medium businesses. He has been with Amazon for over 3 years and uses his background in computer science and machine learning to support customers on AWS. In his free time, Michael loves to hike and explore other cultures.
Michael Zhang is a generalist Solutions Architect at AWS working with small to medium businesses. He has been with Amazon for over 3 years and uses his background in computer science and machine learning to support customers on AWS. In his free time, Michael loves to hike and explore other cultures.







