

Enterprise organizations are rapidly moving beyond generative AI experiments to production deployments and complex agentic AI solutions, facing new challenges in scaling, security, governance, and operational efficiency. This blog post series introduces generative AI operations (GenAIOps), the application of DevOps principles to generative AI solutions, and demonstrates how to implement it for applications powered by Amazon Bedrock, a fully managed service that offers a choice of industry leading foundation models (FMs) along with a broad set of capabilities that you need to build generative AI applications.
In this first part of our two-part series, you’ll learn how to evolve your existing DevOps architecture for generative AI workloads and implement GenAIOps practices. We’ll showcase practical implementation strategies for different generative AI adoption levels, focusing on consuming foundation models. For information on foundation model training, model fine-tuning, and model distillation, refer to our separate resources. Part two covers AgentOps and advanced patterns for scaling agentic AI applications in production.
From DevOps to GenAIOps
For years, enterprises have successfully embedded DevOps practices into their application lifecycle, streamlining the continuous integration, delivery, and deployment of traditional software solutions. As they progress through the generative AI adoption levels, they quickly discover that traditional DevOps practices aren’t sufficient for managing generative AI workloads at scale. Whereas conventional DevOps emphasizes seamless collaboration between development and operations teams and handles deterministic systems with predictable outputs, the nondeterministic, probabilistic nature of AI outputs requires a shift in how organizations approach lifecycle management of their generative AI–powered solutions. GenAIOps helps you with:
- Reliability and risk mitigation – Defend against hallucinations, handle nondeterminism, and enable safe model upgrades with guardrails, evaluation pipelines, and automated monitoring.
- Scale and performance – Scale to hundreds of applications while maintaining low response latency and efficient consumption cost.
- Ongoing improvement and operational excellence – Build consistent environments, reuse and version generative AI assets, manage context and model lifecycle management, and improve generative AI systems through automated evaluation, fine-tuning, and human-AI collaboration.
- Security and compliance – Enable robust security and compliance across different levels—models, data, components, applications, and endpoints. Common concerns include prompt injection attacks, data leakage in model responses, and unauthorized model and tool access.
- Governance controls – Establish clear policies and accountability for sensitive data and intellectual property (IP) while aligning your solutions with regulatory requirements.
- Cost optimization – Optimize resource utilization and manage overspending risk.
At a high level, the GenAIOps lifecycle is similar to that of DevOps, but there are additional considerations for each lifecycle step when it comes to generative AI applications. The following table describes the DevOps practices per stage and the GenAIOps extensions.
| Stage | DevOps practices | GenAIOps extensions |
|---|---|---|
| Plan |
|
|
| Develop |
|
|
| Build |
|
|
| Test |
|
|
| Release |
|
|
| Deploy |
|
|
| Maintain |
|
|
| Monitor |
|
|
The following graphic illustrates the GenAIOps key activities per stage.
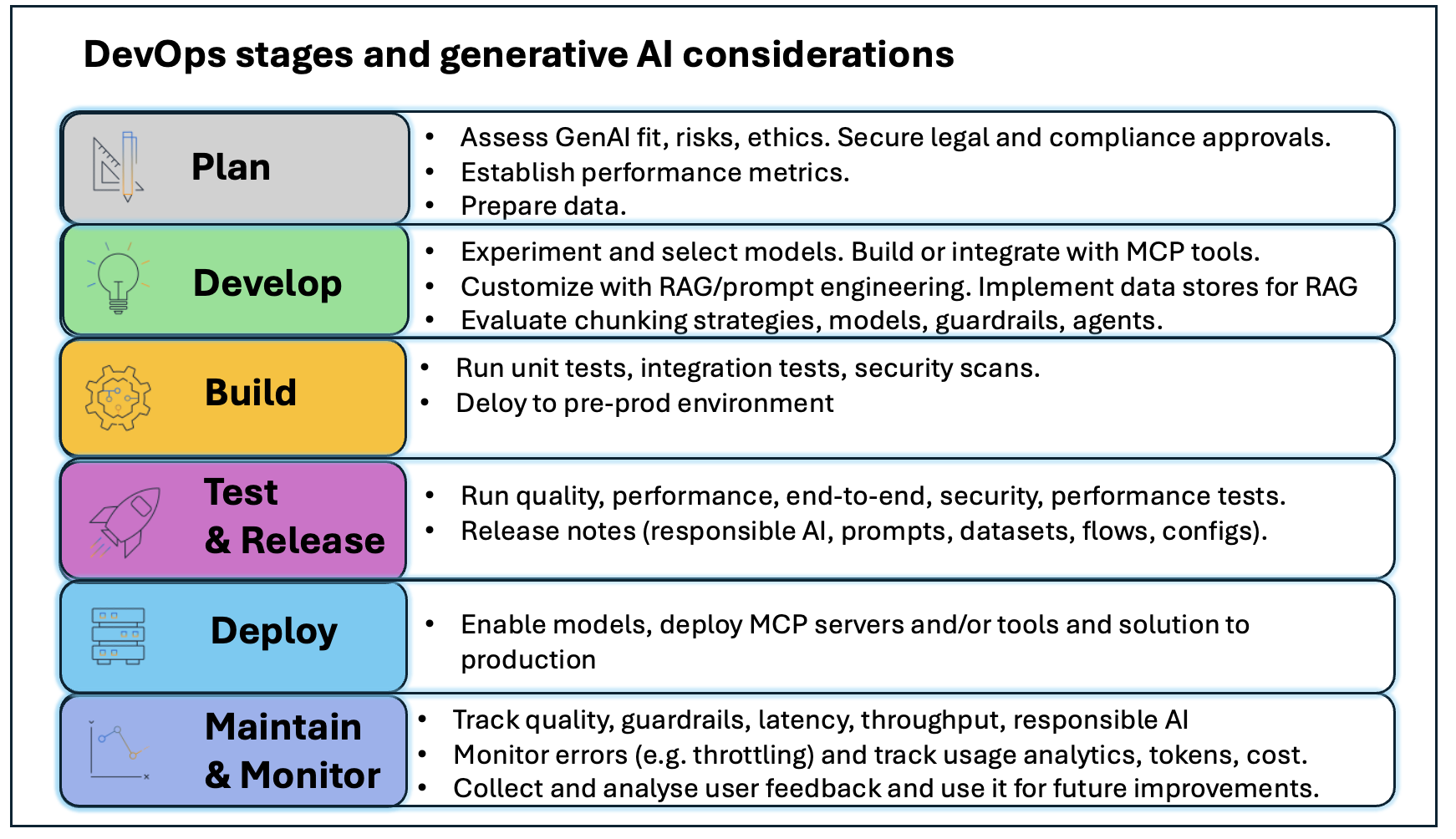
Figure 1: DevOps Stages with GenAIOps key activities
People and processes in GenAIOps
Before exploring the GenAIOps implementation patterns, we now examine how GenAIOps expands roles and processes to address unique challenges associated with generative AI. The following are the key roles and pillars of the generative AI application lifecycle:
- Product owners and domain experts define and prioritize use cases, create golden prompt datasets, establish success metrics, and validate generative AI fit through rapid prototyping.
- GenAIOps and platform teams standardize account infrastructure and provision environments for model serving, consumption and customization, embedding storage, and component orchestration. They own setting up continuous integration and continuous delivery (CI/CD) pipelines with infrastructure as code (IaC), production monitoring, and observability.
- Security teams implement defense-in-depth with access controls, encryption protocols, and guardrails while they continuously monitor for emerging threats and potential data exposure.
- Risk, legal, governance, and ethics specialists establish comprehensive responsible AI frameworks, conduct systematic risk evaluations, implement bias minimization strategies, and achieve regulatory alignment.
- Data teams source, prepare, and maintain high-quality datasets for building, updating, and evaluating generative AI applications.
- AI engineers and data scientists develop the application code, integrate generative AI capabilities, implement prompt engineering techniques, construct reusable component libraries, manage versioning systems, use customization techniques and design human-in-the-loop workflows.
- Quality assurance (QA) engineers test for AI-specific concerns, including prompt robustness, output quality, and guardrail effectiveness, and perform regression testing for new model versions.
The following graphic illustrates these roles.
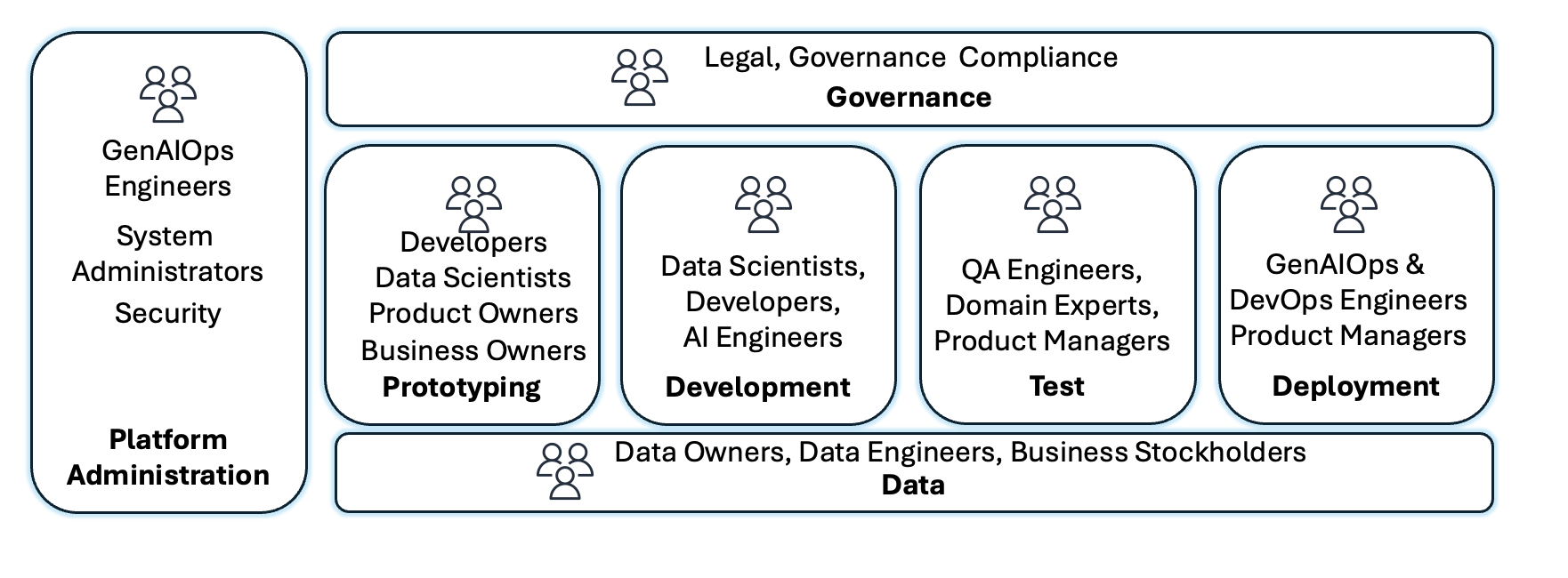
Figure 2: People and Processes in GenAIOps
GenAIOps adoption journey
GenAIOps implementations can vary depending on how generative AI has permeated a business. The following are the three main stages of generative AI adoption:
- Stage 1: Exploration – Organizations new to generative AI who start with a few proofs of concept (POCs) to prove the value for the business. They have limited generative AI resources, and typically a small set of early adopters leads the exploration.
- Stage 2: Production – Organizations have proven value created through generative AI in some production use cases and intend to scale to multiple use cases. They view it as a business differentiator. Multiple teams use generative AI and scaling challenges emerge. They use FMs, tools, and design patterns like RAG and might start experimenting with agentic workflows. Organization at this stage begins formalizing training programs for builders and establishing generative AI centers of excellence.
- Stage 3: Reinvention – Generative AI is part of enterprise strategy. Organizations want to invest in generative AI resources and make generative AI building tools available to everyone. They use complex agentic AI solutions.
As they progress in their adoption journey, enterprises expand their existing DevOps workflows for GenAIOps. The following sections describe implementation patterns for GenAIOps per stage using Amazon Bedrock capabilities. With on-demand access to models, managed infrastructure pre-trained and built-in security features, Amazon Bedrock enables rapid Generative AI deployment while helping to maintain enterprise compliance.
Exploration
In the exploration stage, organizations often rely on small, cross-functional tiger teams comprising early AI adopters who wear multiple hats. Data scientists might double as prompt engineers, developers handle their own model evaluations, and compliance reviews are conducted through extemporaneous meetings with legal teams. The governance processes remain largely manual and informal, with product owners directly collaborating with technical teams to establish success metrics while platform engineers focus on basic environment setup rather than sophisticated CI/CD automation.
DevOps foundation
Before you integrate generative AI capabilities into your applications and workflows, we need a baseline DevOps architecture to support your solution. As shown in the following diagram, you have a shared account that manages your CI/CD pipelines and controls deployments across development, pre-production, and production accounts. You also have separate AWS accounts for development, pre-production, data governance, and data producers for isolation between environments, security control, and cost tracking by environment. Every resource in this setup is defined as code, meaning you can version, test, and deploy your entire infrastructure as seamlessly as you deploy application code.
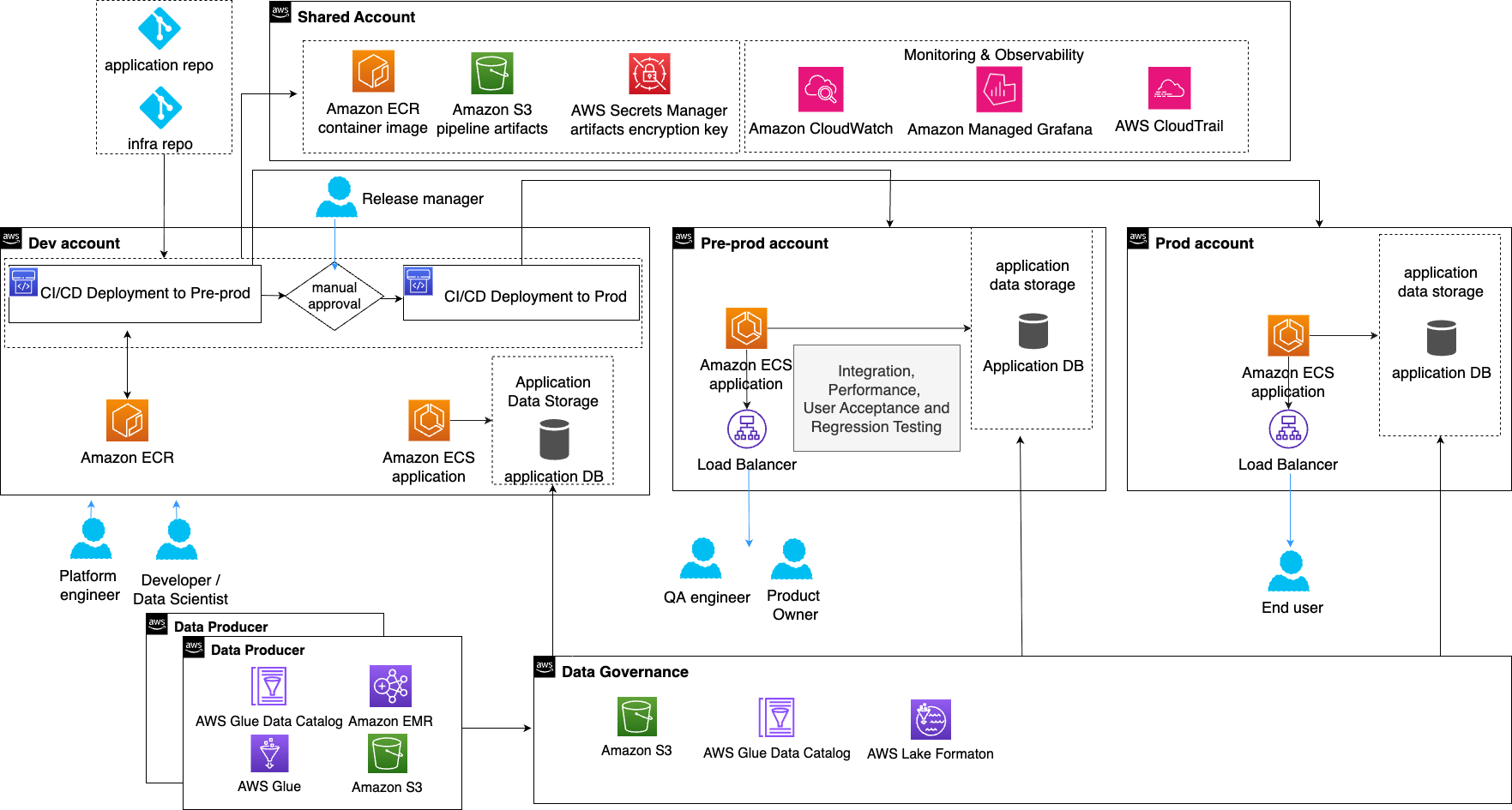
Figure 3: DevOps baseline architecture
Now that you understand the DevOps foundation, we’ll show how you can enhance it with Amazon Bedrock capabilities and start building your GenAIOps foundation in four key steps.
Step 1: Manage data for your generative AI applications
Data serves three critical functions in generative AI: powering RAG systems for enhanced contextual responses, providing ground truth for model evaluation and validation, and enabling both initial training and subsequent fine-tuning of AI models for specific use cases by providing training data. In most cases, access controls are required to help prevent unauthorized access. In RAG, data is used to improve LLM responses and ground them in truth by providing relevant contextual information from data sources. In the standard RAG workflow, you:
- Retrieve relevant content from a knowledge base through queries.
- Augment the prompt by enriching it with retrieved contextual information.
- Pass the augmented prompt containing both original input and context to an LLM to generate the final response.
When using Amazon Bedrock, you can query a vector database such as Amazon OpenSearch Service or get data from a data store using an API query to augment the user’s query before it’s sent to an FM. If you have live data sources, it’s necessary to implement connectors to enable data synchronization and integration with various data sources to help maintain data integrity and freshness. You also need to configure guardrails so that data that shouldn’t be sent to the model or be part of the output, such as personally identifiable information (PII), is correctly blocked or blanked.
You can also use Amazon Bedrock Knowledge Bases, a fully managed capability that helps you implement the entire RAG workflow without having to build custom integrations to data sources and manage data flows.
Your data provides a source of truth in evaluation. Before application development begins, generative AI developers should establish a comprehensive golden dataset derived from real-world interactions or domain expert input. A robust evaluation dataset should be composed of, depending on your evaluation strategy, prompt or prompt-response pairs that accurately reflect real-world usage scenarios and provide comprehensive coverage of expected production queries. Data engineers make this dataset available in the development environment, applying necessary modifications for sensitive data. Prompt outputs, or prompt outputs together with the expected answers, can then be used by human evaluators or LLM-as-a-judge evaluators (for instance, LLM-as-a-judge on Amazon Bedrock Model Evaluation) to assess the quality of the application responses.
Model providers use extensive datasets to develop foundation AI models, whereas end users use domain-specific data to fine-tune these models for specialized applications and targeted use cases.
In most cases, you need to implement data governance policies so that users only access authorized data throughout the entire system pipeline. You also need to control versions of evaluation datasets, as well as track changes to documents and generated embeddings in RAG knowledge bases for evaluation and auditing purposes.
Overall having a strong data foundation is important for generative AI applications.
Step 2: Establish the development environment
Start by integrating FMs and other generative AI capabilities into your application during prototyping in the development environment. In Amazon Bedrock, you can access the models directly using the Amazon Bedrock virtual private cloud (VPC) endpoint powered by AWS PrivateLink and establish a private connection between the VPC in your account and the Amazon Bedrock service account.
You can use Amazon Bedrock Prompt Management to create, test, manage, and optimize prompts for FMs and use Amazon Bedrock Flows for multistep workflows such as document analysis pipelines that require sequential LLM calls. You can also configure and apply guardrails and incorporate safety controls for the FM interactions with Amazon Bedrock Guardrails. In many use cases, you want to give these models contextual information from your company’s data sources using RAG. You can implement a self-managed approach or use Amazon Bedrock Knowledge Bases, a fully managed capability with built-in session context management and source attribution.
The following image shows the key Amazon Bedrock capabilities for model consumers starting with FMs, Knowledge Bases, Agents, and Intelligent Prompt Routing. Following these are Guardrails, Flows, Prompt Engineering, and finally, Prompt Caching.
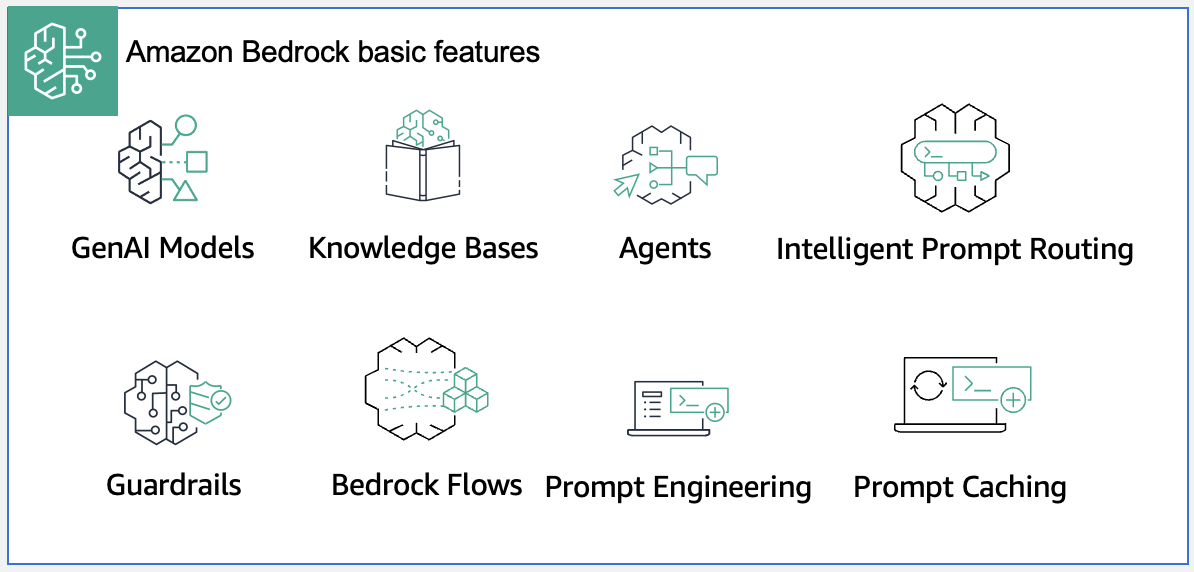
Figure 4: Amazon Bedrock key components for model consumers
Evaluate performance
After you’ve integrated the FMs and generative AI components into your application, you need to evaluate their performance. At this point, you create test cases, write test configurations to test different prompts, models, vector stores, and chunking strategies, which they save in their application code or other tool of choice, and calculate evaluation metrics. Amazon Bedrock provides evaluation tools for you to accelerate adoption of generative AI applications. With Amazon Bedrock Evaluations, you can evaluate, compare, and select the best FM for your use case using automatic evaluations (programmatic or with LLM-as-a-Judge) and set up human-in-the-loop evaluation workflows. You can also bring your own (BYO) inference responses and evaluate models, RAG implementations, and fully built applications.
The following diagram summarizes the approach where you’d use an AWS Lambda function to read the inference prompt-response pairs, route them to Amazon Bedrock Evaluations, and store the results in an Amazon Simple Storage Service (Amazon S3) bucket.
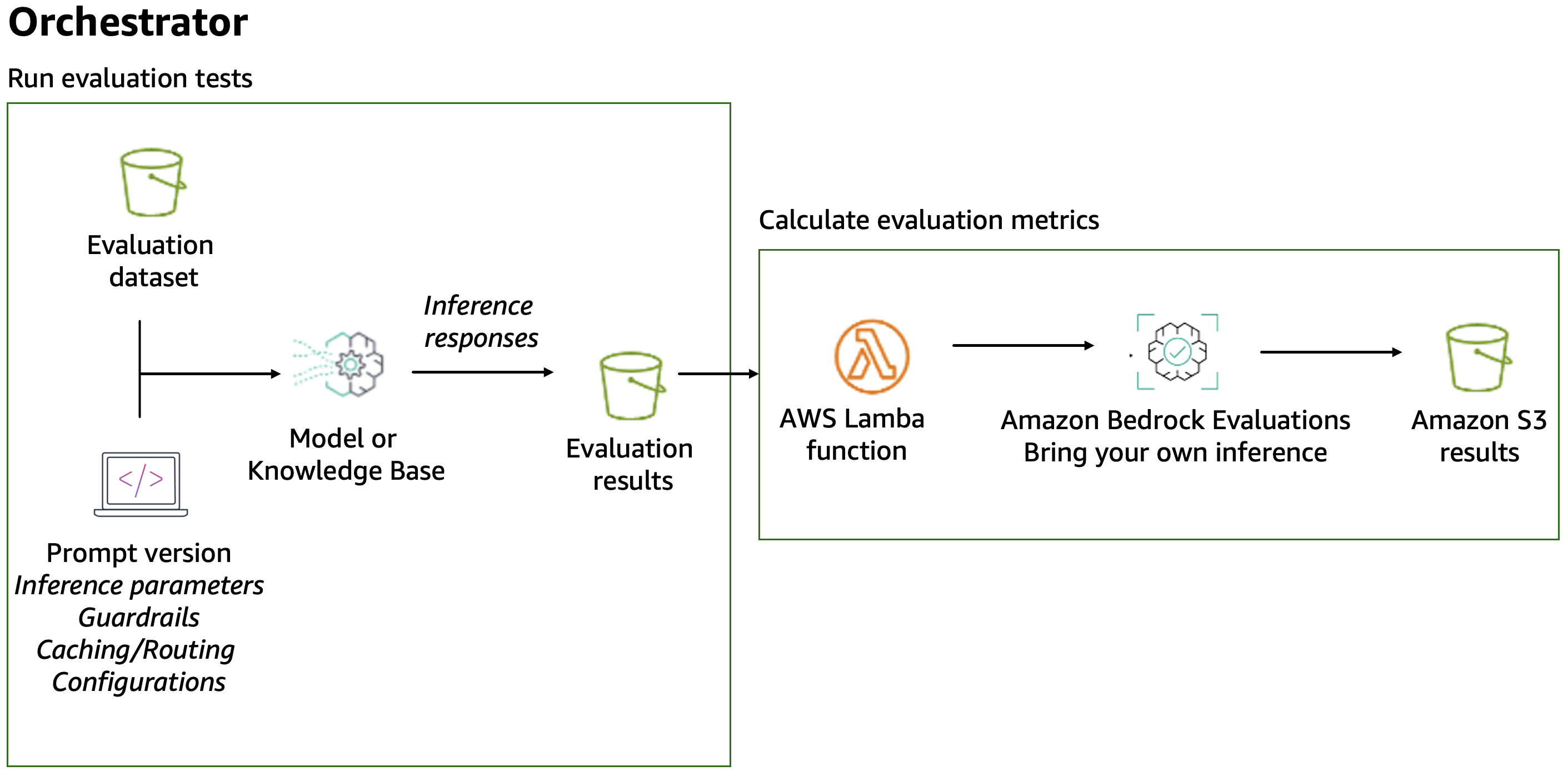
Figure 5: Evaluation during development
In case of issues, due to the probabilistic nature of the generative AI components, you need to categorize errors systematically to identify patterns before you act, rather than fixing problems in an isolated way. We recommend the following tests in addition to your standard application testing:
- Quality testing – Generative AI outputs can vary, producing great responses one moment and hallucinating the next. Your GenAIOps solution should enable fast testing of output in quality metrics such as correctness and completeness and can include automatic testing as well as human-in-the-loop.
- Safety testing – Check for unwanted behavior.
- Component-level testing – This is important to evaluate each element and assess both the outputs and reasoning logic in addition to testing the end-to-end solution.
- Automated evaluation – Automation makes it possible to run hundreds of tests in seconds using programmatic verification for factual accuracy and the model evaluation capabilities of Amazon Bedrock as an LLM-as-judge.
- Human review – Human oversight is important for mission-critical scenarios.
- Statistical validation – Run statistically significant sample sizes, typically over hundreds of test cases, to achieve high confidence intervals.
- Price-performance testing – You might want to optimize your generative AI applications for cost, latency, and throughput. Amazon Bedrock provides capabilities and consumption options to help you achieve your goals. For example, you can use Amazon Bedrock Prompt Caching or Amazon Bedrock Intelligent Prompt Routing to reduce latency and cost, Amazon Bedrock Batch Inference for use cases not performed in real time, and Provisioned Throughput for higher levels of throughput per model at a fixed cost. This open source benchmarking solution helps benchmark performance. Refer to the Amazon Bedrock pricing page for pricing information.
- Latency – Depending on the use case, keeping low latency might be necessary. There are unique latency dimensions to consider
- in generative AI applications, such as tokens per second (TPS), time to first token (TTFT), and time to last token (TTLT).
When optimizing an application, builders must keep in mind that optimizing on one dimension can force trade-offs in other dimensions. Quality, cost, and latency are closely related, and optimizing for one can effect the other.
When running tests at scale, you need a way to track your experiments. A way to do that is to use Amazon SageMaker AI with MLflow, a fully managed capability of Amazon SageMaker AI that lets you create, manage, analyze, and compare your machine learning (ML) experiments.
Step 3: Add generative AI tests to your CI/CD pipeline
After you’ve identified the optimal model, prompts, inference parameters, and other configurations for your use case, commit these artifacts to your application repository to trigger your CI/CD pipeline. This pipeline should execute your predefined evaluation tests, creating an essential quality gate for your generative AI applications. When tests pass the accuracy, safety, and performance thresholds, your pipeline deploys to the pre-production environment for final validation. If the tests fail, the system adds detailed comments to the pull request with specific test failures. You should also pair your evaluation pipeline with comprehensive experiment tracking to capture every test variable, from model configurations to performance metrics.
Step 4: Monitor your generative AI solution
With generative AI observability, you can understand, optimize, and evolve your applications throughout their lifecycle and deliver capabilities across the following dimensions:
- Decision-making – Gain visibility into system components to balance cost, performance, and latency based on actual usage patterns.
- Performance – Pinpoint bottlenecks across retrieval operations, model inference, and application components.
- Ongoing improvements – Capture explicit ratings and implicit signals to systematically refine your generative AI solutions.
- Responsible AI – Deploy automated detection systems for hallucinations, harmful content, and bias with human review triggers.
- Auditing – Maintain audit trails documenting inputs, outputs, reasoning chains, and parameters.
Your observability implementation needs to monitor:
- Operational metrics – Monitor system health and application latency, with breakdowns for retrieval operations, model inference, tool use, and token consumption.
- Runtime exceptions – Capture rate limiting issues, token quota exceedances, and retrieval failures with contextual details for troubleshooting.
- Quality metrics – Track metrics such as LLM response relevance, correctness, helpfulness, and coherence. For RAG, you can also monitor retrieval accuracy and source attribution accuracy.
- Auditability – Maintain comprehensive logs of user interactions for compliance, debugging, and analysis purposes.
- Guardrails – Detect prompt injection attempts, PII and sensitive information leakage, adversarial attack patterns, and jailbreak attempts. Guardrail performance should also be monitored, tracking guardrail invocations and latency.
- Tool use – For LLMs with function calling capabilities (like Claude by Anthropic, Amazon Nova, or Meta’s Llama model families), robust observability lets you inspect function selections and parameters in real time, providing critical insights that help debug and optimize your agent-based application.
In Amazon Bedrock, you can enable and capture model invocation logs in Amazon S3, Amazon CloudWatch, or both. In CloudWatch, you can create purpose-built dashboards that visualize key metrics including timestamp, input and output token counts, and invoked model ID. The following screenshot shows an example of Amazon Bedrock invocation metrics in CloudWatch.
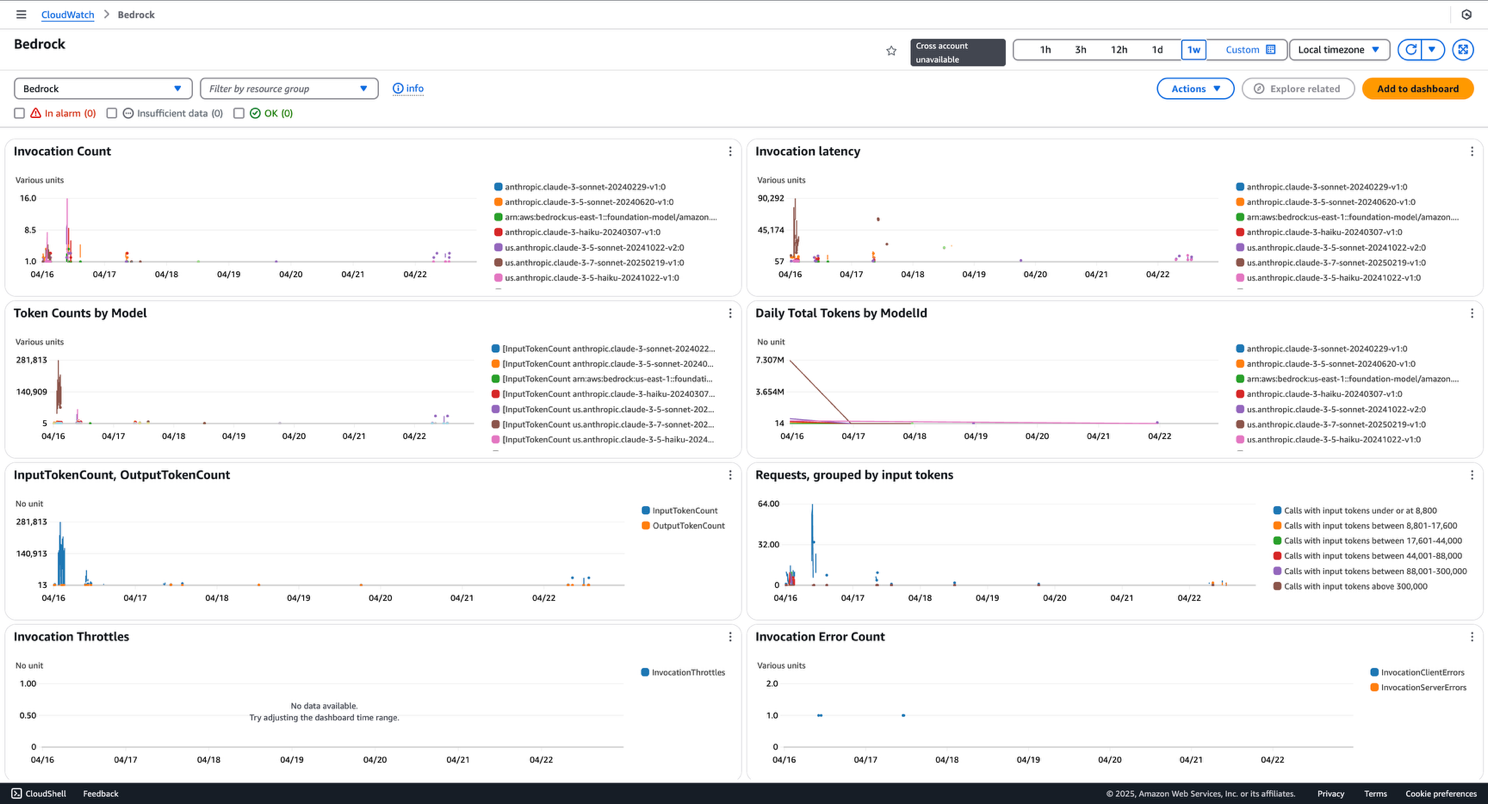
Figure 6: Example of Amazon Bedrock invocation metrics in Amazon CloudWatch
Amazon Bedrock is integrated with AWS CloudTrail, a service that provides a record of actions taken by a user, role, or an AWS service in Amazon Bedrock. AWS CloudTrail captures the API calls for Amazon Bedrock as events. Amazon Bedrock also publishes guardrail metrics to CloudWatch such as guardrail invocations, latency, and guardrail interventions.
You can also refer to the Bedrock-ICYM (I See You Monitoring) repository for an open source observability solution for Amazon Bedrock or use open source solutions such as Arize AI and Langfuse.
Implementing the four steps outlined in this post can transform your baseline DevOps solution into a robust GenAIOps solution that follows best practices. This architecture maintains isolation between environments while integrating key generative AI components, including Amazon Bedrock capabilities, development-time evaluation tools, automated evaluation pipelines, and comprehensive monitoring. The recommended application lifecycle is as follows:
- Product owner registers the use case in a centralized catalog while legal and compliance teams assess risks and provide guidance. Some organizations choose to also provide a generative AI playground for initial experimentation before registering the use case to the registry.
- As soon as the use case is reviewed by the legal and risk teams, the product owner works with domain experts and technical teams to establish scope, success metrics, and create golden test prompts for evaluation.
- Platform engineers deploy environments using IaC with appropriate access controls as agreed with security and tagging for governance and cost tracking.
- Data engineers create datasets and evaluation sets for development and testing.
- Developers and data scientists integrate generative AI capabilities into their application using techniques such as prompt engineering and RAG or agents.
- Developers use manual and automated evaluation tools to evaluate their implementation. Domain experts review the initial results.
- Developers merge their changes to the main branch in the shared services account.
- Upon code merge to main, the CI/CD pipeline runs and creates a release branch.
- When the release build is successful, it’s deployed to pre-production and the evaluation pipeline is triggered. For RAG implementations, this involves deploying the ingestion pipeline into the data governance account and configuring the automatic syncing.
- In the pre-production account, integration, performance, user acceptance, regression, and generative AI evaluation are tested.
- QA engineers and domain experts validate the solution against established metrics and approve promotion to production from the same release branch.
- If the tests pass, the solution is deployed to production where end users can use it.
- In steps 13 and 14, in production, end users use the application and can provide feedback or override the responses.
The following diagram shows the complete architecture with numbers that correspond to these steps.
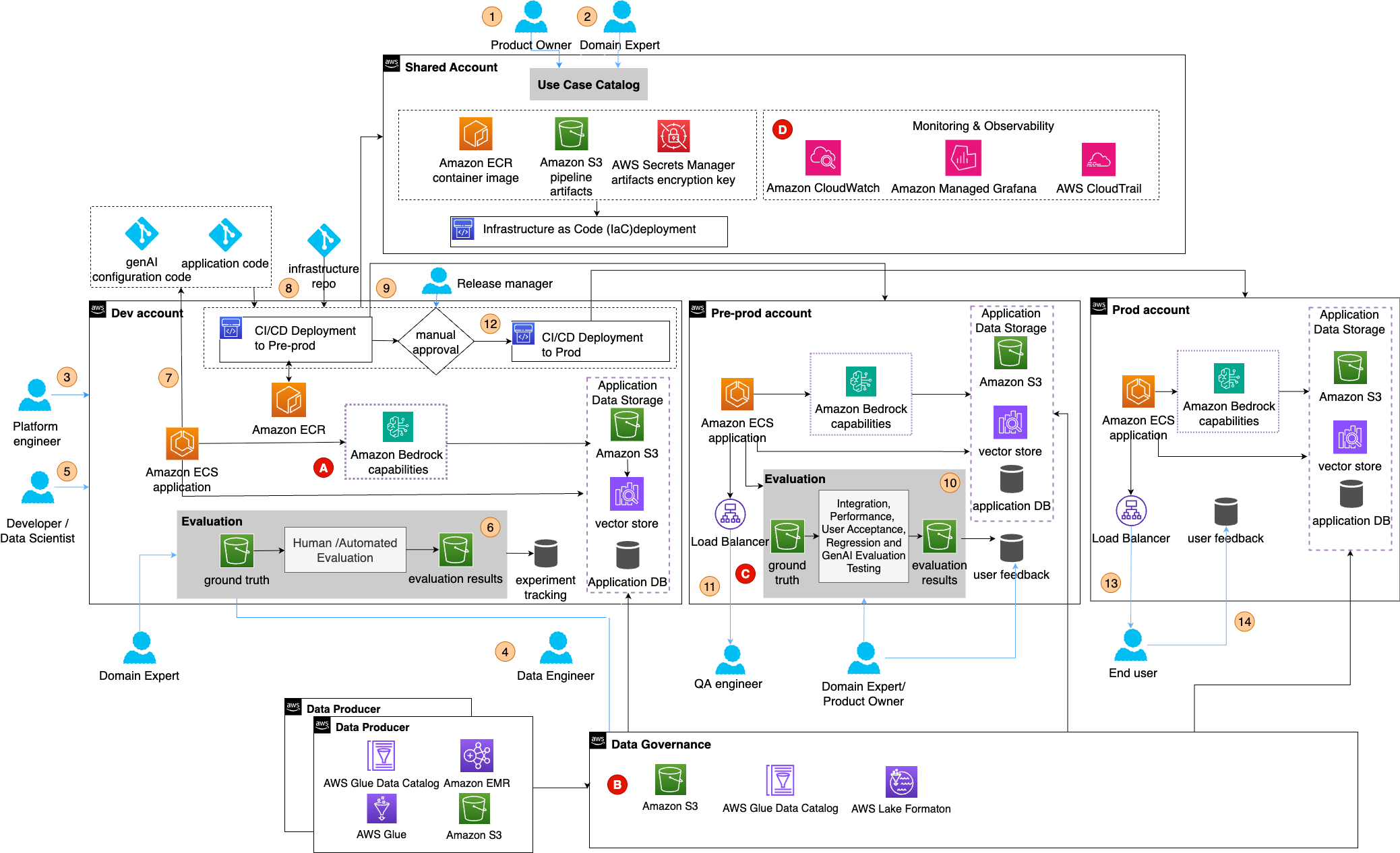
Figure 7: GenAIOps architecture – Exploration
With these essential GenAIOps components in place, organizations can progress to the next stage.
Production
As organizations enter the production stage, they formalize dedicated roles within newly established generative AI centers of excellence, where specialized prompt engineers, AI evaluation specialists, and GenAIOps platform engineers emerge as distinct functions with clear responsibilities and standardized processes. Training programs become systematic across the organization, compliance checks transition from manual reviews to automated policy enforcement, and cross-functional collaboration shifts from informal coordination to structured workflows with defined handoffs between development, evaluation, and deployment teams.
Organizations in the production stage aim at standardizing code repositories, developing reusable components, and implementing automated evaluation and feedback loops within their established GenAIOps pipeline to help continuously enhance application quality and operational efficiency. In some cases, they can also benefit from a centralized generative AI gateway to help streamline LLM interactions, help with load balancing and error handling, and fall back to other models when required. You can further enhance your GenAIOps foundation in three additional key steps.
Step 5: Standardize code repositories and develop reusable components
In addition to having version control through repository solutions such as GitHub or GitLab to maintain, track, and version your application code for the application, you should strive to create reusable, versioned blueprints for your prompts, model configuration, and guardrails.
A prompt template is a prompt that includes replaceable variables or parameters. You can adjust these to customize and tailor the prompt template to a particular use case. The purpose is to accelerate prompt engineering processes and facilitate quick sharing of prompts across generative AI applications. Examples of prompt templates for Amazon Bedrock can be found at Prompt templates and examples for Amazon Bedrock text models.
You should centrally store, track, and version both prompt templates and application-specific prompts in a prompt catalog. You can use Git, but as you scale, we recommend using dedicated tools instead, for example, Amazon Bedrock Prompt Management. Use prompt management to store your prompts alongside models, inference parameter values, guardrails, and variables when creating prompts. Additionally, you can use automated prompt optimization tools that can help refine prompts such as Prompt optimization in Amazon Bedrock.
Many use cases require the creation of workflows that are end-to-end solutions linking FMs, prompts, and components such as knowledge bases. Store workflows as code in your repository, enabling version control, tracking, and seamless deployment across test and production environments. Amazon Bedrock Flows provides a visual builder interface for creating and deploying generative AI workflows.
Although guardrails might already be part of your prompt and model configuration, it’s also possible to have guardrails defined for your workloads and to store the configuration of these guardrails in a common store or repository in the shared account.
Step 6: Automated evaluation and feedback loops for continuous improvement
To further scale, store the evaluation pipelines as shared and deployable assets that can be maintained, tracked, and versioned in a repository environment. This allows the integration of automatic testing into the CI/CD pipeline.
For evaluation pipelines that include human evaluation to assess and evaluate the outputs of AI models through human feedback and review, you can use tools to automate this process. For instance, you can use human-based model evaluation in Amazon Bedrock and to automate the creation of the evaluation job. Use this tool to seamlessly orchestrate human evaluation flows, including pre-implemented workflows, UI components, and the management of labeling workforce.
Step 7: Centralized generative AI gateway to help streamline LLM interactions
Organizations at this stage can benefit from implementing a centralized multi-provider generative AI gateway on AWS to optimize their LLM operations. Using a generative AI gateway can help customers that want to implement one or more of the following:
- Standardized access – A unified API interface that seamlessly integrates with multiple LLM providers. It helps application developers have only one location to connect to LLMs in their organization.
- Centralized unified management – Unified API management, including centralized key administration, quota tracking, and monitoring. This centralizes security and cost tracking and helps to reduce risk.
- Centralized security – Standardized security measures applied to LLM access help prevent unauthorized access and tracking and include implementing common guardrails.
- Load balancing – Enables seamless model interchange and provider transitions and facilitates streamlined administration of multiple LLMs across your applications.
- Fault recovery – Failover capabilities with redirection to alternate models or deployments to help with continuous service availability and operational resilience.
- Cost optimization – Intelligent request routing, optimizing traffic distribution based on customizable cost parameters and performance metrics.
An example of a mature generative AI gateway is the Guidance for Multi-Provider Generative AI Gateway on AWS, which provides standardized access through a single API interface that supports multiple AI providers, such as Amazon Bedrock, and streamlines LLM interactions. The solution features comprehensive enterprise controls, including usage tracking, robust access control, cost management capabilities, and security monitoring. It also enables deployment efficiency through automated deployment using HashiCorp Terraform, with support for Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS) implementations in a production-ready infrastructure.
The updated diagram reflects these steps. It introduces experiment tracking in the shared account and a generative AI gateway for each one of your Dev, Pre-Prod and Prod environments to provide standardized access to FMs from multiple providers through unified API management and security controls. Changes to the generative AI gateway configuration should trigger the CI/CD pipeline for deployment and evaluation.
Your application repository contains your application specific code and tests. In addition, we have added the following shared modules to the repository:
- Guardrail catalog (8b in the diagram) – For shared guardrail configurations (alternatively, this can be a separate repository, database, or dedicated tool).
- Tools catalog (8c) – For shared tools that can be used by LLMs (alternatively, this can be a separate repository).
- Prompt and flow catalogs (8d) – For repeatable, versioned blueprints for prompt and flows (alternatively, this can be a separate repository, database, or dedicated tool).
- Evaluation pipelines (8e)– With reusable testing frameworks for consistent AI quality assessment.
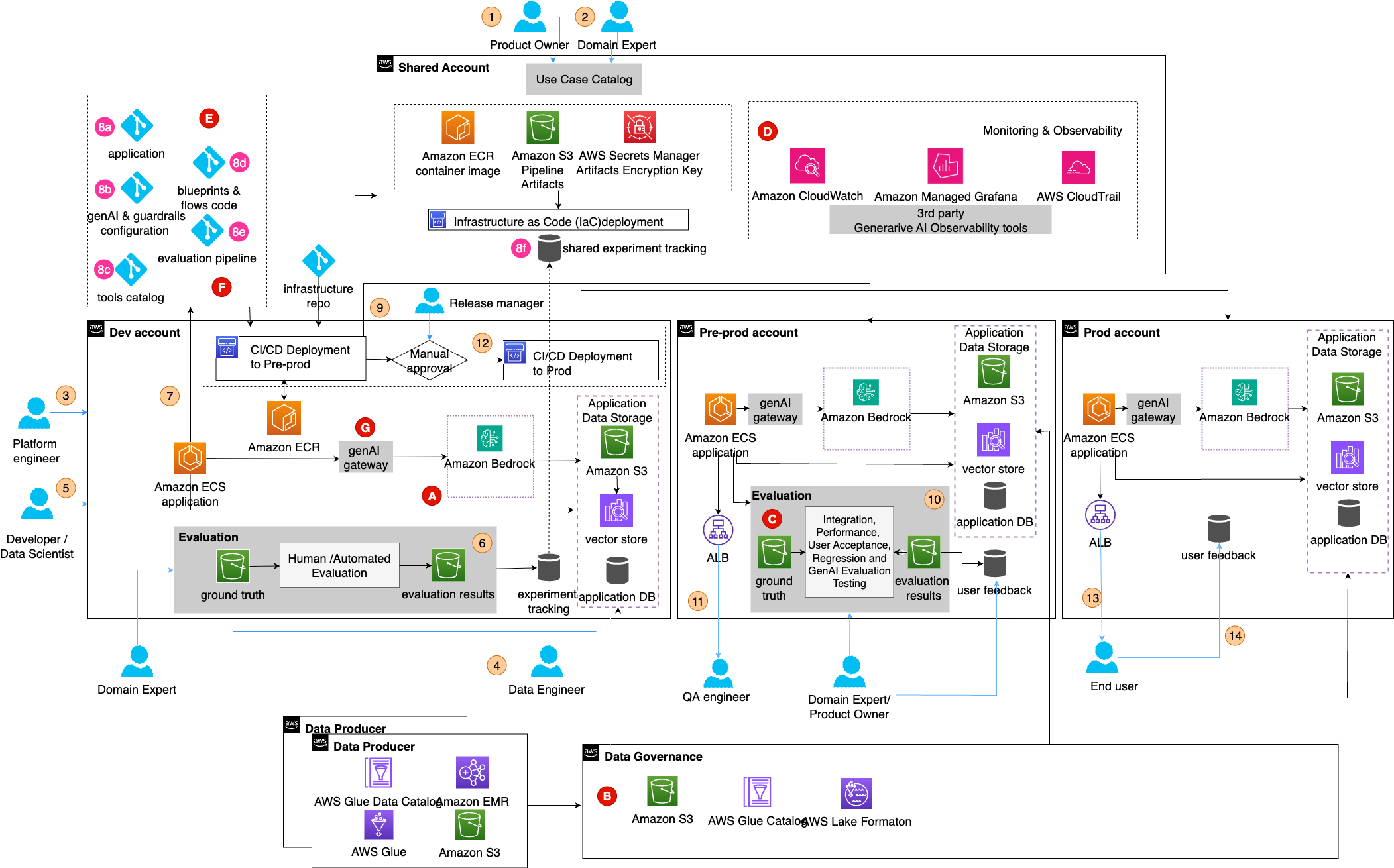
Figure 8: GenAIOps with reusable components
Reinvention and considerations for agentic workloads
Many organizations progress from initial LLM applications and RAG implementations to sophisticated agent-based architectures. This evolution marks a fundamental shift from using AI to augment human decisions to deploying autonomous agentic AI solutions.
An AI agent is an autonomous system that combines LLMs with external tools and data sources to perceive its environment, reason and plan, execute complex multistep tasks, and achieve specific objectives with minimal human intervention. It usually consists of the the following components: models, data sources, models, deterministic components, agentic/probabilistic components, and protocols.
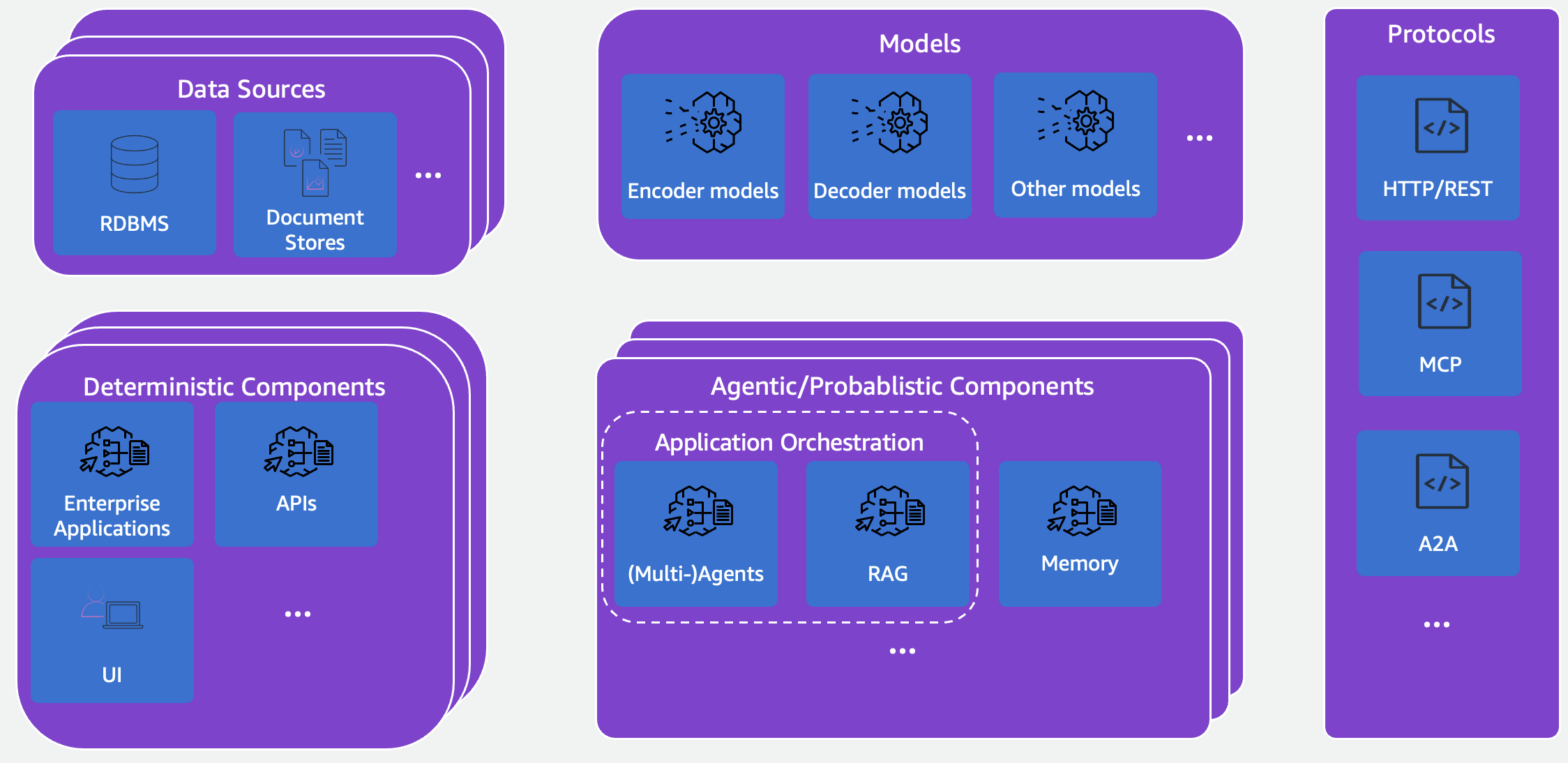
Figure 9: Components of Agentic AI solutions
The probabilistic nature of some of these components brings new challenges when managing the end-to-end lifecycle of agentic AI solutions. AgentOps is a set of practices that extend GenAIOps to address these challenges and risks. In the second part of this blog post series, we revise our generative AI solution for AgentOps.
Conclusion
In this post, you’ve learned how to implement GenAIOps practices that align with your organization’s generative AI adoption level, accelerate development through systematic evaluation and reusable assets, and establish robust monitoring for your generative AI solutions. Throughout, we’ve shown how to effectively mitigate risks and maximize business value using the managed capabilities of Amazon Bedrock.
We encourage you to start applying these practices in your projects and share your experiences. Ready to take your GenAIOps to the next level? Stay tuned for part 2, where we’ll dive deeper into AgentOps and explore solution designs for multi-agent systems with Amazon Bedrock AgentCore.
About the Authors
 Anastasia Tzeveleka is a Senior Generative AI/ML Specialist Solutions Architect at AWS. Her experience spans the entire AI lifecycle, from collaborating with organizations training cutting-edge Large Language Models (LLMs) to guiding enterprises in deploying and scaling these models for real-world applications. In her spare time, she explores new worlds through fiction.
Anastasia Tzeveleka is a Senior Generative AI/ML Specialist Solutions Architect at AWS. Her experience spans the entire AI lifecycle, from collaborating with organizations training cutting-edge Large Language Models (LLMs) to guiding enterprises in deploying and scaling these models for real-world applications. In her spare time, she explores new worlds through fiction.
 Anna Grüebler Clark is a Specialist Solutions Architect at AWS focusing on in Artificial Intelligence. She has more than 16 years experience helping customers develop and deploy machine learning applications. Her passion is taking new technologies and putting them in the hands of everyone, and solving difficult problems leveraging the advantages of using traditional and generative AI in the cloud.
Anna Grüebler Clark is a Specialist Solutions Architect at AWS focusing on in Artificial Intelligence. She has more than 16 years experience helping customers develop and deploy machine learning applications. Her passion is taking new technologies and putting them in the hands of everyone, and solving difficult problems leveraging the advantages of using traditional and generative AI in the cloud.
 Antonio Rodriguez is a Principal Generative AI Specialist Solutions Architect at Amazon Web Services. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock. Apart from work, he loves to spend time with his family and play sports with his friends.
Antonio Rodriguez is a Principal Generative AI Specialist Solutions Architect at Amazon Web Services. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock. Apart from work, he loves to spend time with his family and play sports with his friends.
 Aris Tsakpinis is a Specialist Solutions Architect for Generative AI focusing on open source models on Amazon Bedrock and the broader generative AI open source ecosystem. Alongside his professional role, he is pursuing a PhD in Machine Learning Engineering at the University of Regensburg, where his research focuses on applied natural language processing in scientific domains.
Aris Tsakpinis is a Specialist Solutions Architect for Generative AI focusing on open source models on Amazon Bedrock and the broader generative AI open source ecosystem. Alongside his professional role, he is pursuing a PhD in Machine Learning Engineering at the University of Regensburg, where his research focuses on applied natural language processing in scientific domains.





