

This post is a joint collaboration between Salesforce and AWS and is being cross-published on both the Salesforce Engineering Blog and the AWS Machine Learning Blog.
The Salesforce AI Platform Model Serving team is dedicated to developing and managing services that power large language models (LLMs) and other AI workloads within Salesforce. Their main focus is on model onboarding, providing customers with a robust infrastructure to host a variety of ML models. Their mission is to streamline model deployment, enhance inference performance and optimize cost efficiency, ensuring seamless integration into Agentforce and other applications requiring inference. They’re committed to enhancing the model inferencing performance and overall efficiency by integrating state-of-the-art solutions and collaborating with leading technology providers, including open source communities and cloud services such as Amazon Web Services (AWS) and building it into a unified AI platform. This helps ensure Salesforce customers receive the most advanced AI technology available while optimizing the cost-performance of the serving infrastructure.
In this post, we share how the Salesforce AI Platform team optimized GPU utilization, improved resource efficiency and achieved cost savings using Amazon SageMaker AI, specifically inference components.
The challenge with hosting models for inference: Optimizing compute and cost-to-serve while maintaining performance
Deploying models efficiently, reliably, and cost-effectively is a critical challenge for organizations of all sizes. The Salesforce AI Platform team is responsible for deploying their proprietary LLMs such as CodeGen and XGen on SageMaker AI and optimizing them for inference. Salesforce has multiple models distributed across single model endpoints (SMEs), supporting a diverse range of model sizes from a few gigabytes (GB) to 30 GB, each with unique performance requirements and infrastructure demands.
The team faced two distinct optimization challenges. Their larger models (20–30 GB) with lower traffic patterns were running on high-performance GPUs, resulting in underutilized multi-GPU instances and inefficient resource allocation. Meanwhile, their medium-sized models (approximately 15 GB) handling high-traffic workloads demanded low-latency, high-throughput processing capabilities. These models often incurred higher costs due to over-provisioning on similar multi-GPU setups. Here’s a sample illustration of Salesforce’s large and medium SageMaker endpoints and where resources are under-utilized:
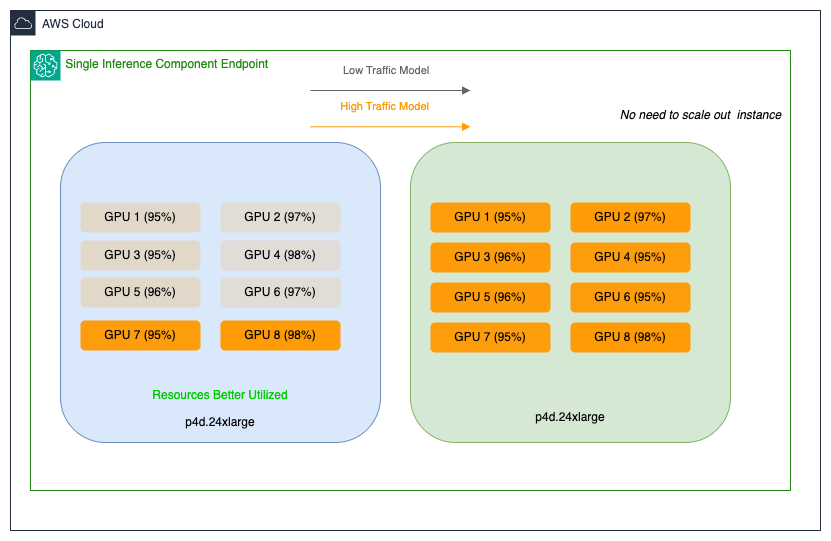
Operating on Amazon EC2 P4d instances today, with plans to use the latest generation P5en instances equipped with NVIDIA H200 Tensor Core GPUs, the team sought an efficient resource optimization strategy that would maximize GPU utilization across their SageMaker AI endpoints while enabling scalable AI operations and extracting maximum value from their high-performance instances—all without compromising performance or over-provisioning hardware.
This challenge reflects a critical balance that enterprises must strike when scaling their AI operations: maximizing the performance of sophisticated AI workloads while optimizing infrastructure costs and resource efficiency. Salesforce needed a solution that would not only resolve their immediate deployment challenges but also create a flexible foundation capable of supporting their evolving AI initiatives.
To address these challenges, the Salesforce AI Platform team used SageMaker AI inference components that enabled deployment of multiple foundation models (FMs) on a single SageMaker AI endpoint with granular control over the number of accelerators and memory allocation per model. This helps improve resource utilization, reduces model deployment costs, and lets you scale endpoints together with your use cases.
Solution: Optimizing model deployment with Amazon SageMaker AI inference components
With Amazon SageMaker AI inference components, you can deploy one or more FMs on the same SageMaker AI endpoint and control how many accelerators and how much memory is reserved for each FM. This helps to improve resource utilization, reduces model deployment costs, and lets you scale endpoints together with your use cases. For each FM, you can define separate scaling policies to adapt to model usage patterns while further optimizing infrastructure costs. Here’s the illustration of Salesforce’s large and medium SageMaker endpoints after utilization has been improved with Inference Components:
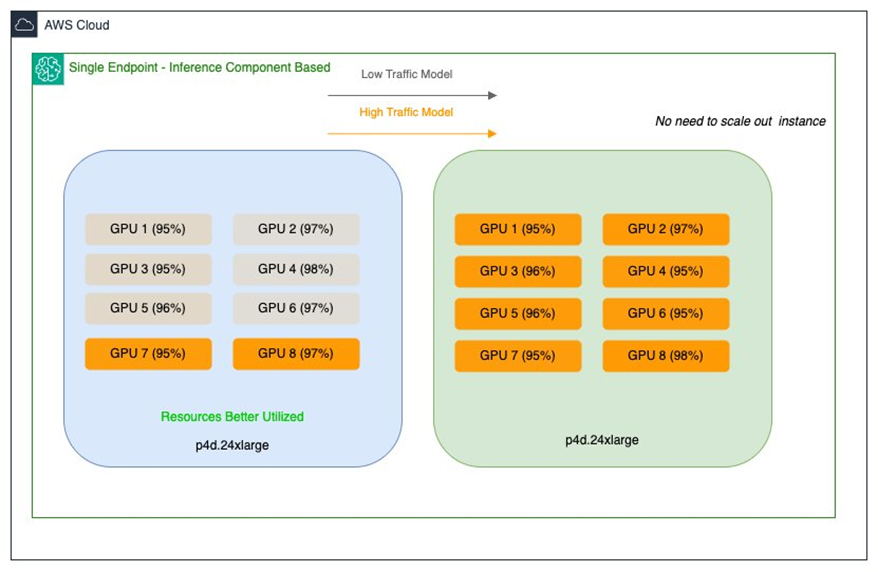
An inference component abstracts ML models and enables assigning CPUs, GPU, and scaling policies per model. Inference components offer the following benefits:
- SageMaker AI will optimally place and pack models onto ML instances to maximize utilization, leading to cost savings.
- Each model scales independently based on custom configurations, providing optimal resource allocation to meet specific application requirements.
- SageMaker AI will scale to add and remove instances dynamically to maintain availability while keeping idle compute to a minimum.
- Organizations can scale down to zero copies of a model to free up resources for other models or specify to keep important models always loaded and ready to serve traffic for critical workloads.
Configuring and managing inference component endpoints
You create the SageMaker AI endpoint with an endpoint configuration that defines the instance type and initial instance count for the endpoint. The model is configured in a new construct, an inference component. Here, you specify the number of accelerators and amount of memory you want to allocate to each copy of a model, together with the model artifacts, container image, and number of model copies to deploy.
As inference requests increase or decrease, the number of copies of your inference components can also scale up or down based on your auto scaling policies. SageMaker AI will handle the placement to optimize the packing of your models for availability and cost.
In addition, if you enable managed instance auto scaling, SageMaker AI will scale compute instances according to the number of inference components that need to be loaded at a given time to serve traffic. SageMaker AI will scale up the instances and pack your instances and inference components to optimize for cost while preserving model performance.
Refer to Reduce model deployment costs by 50% on average using the latest features of Amazon SageMaker for more details on how to use inference components.
How Salesforce used Amazon SageMaker AI inference components
Salesforce has several different proprietary models such as CodeGen originally spread across multiple SMEs. CodeGen is Salesforce’s in-house open source LLM for code understanding and code generation. Developers can use the CodeGen model to translate natural language, such as English, into programming languages, such as Python. Salesforce developed an ensemble of CodeGen models (Inline for automatic code completion, BlockGen for code block generation, and FlowGPT for process flow generation) specifically tuned for the Apex programming language. The models are being used in ApexGuru, a solution within the Salesforce platform that helps Salesforce developers tackle critical anti-patterns and hotspots in their Apex code.
Inference components enable multiple models to share GPU resources efficiently on the same endpoint. This consolidation not only delivers reduction in infrastructure costs through intelligent resource sharing and dynamic scaling, it also reduces operational overhead with lesser endpoints to manage. For their CodeGen ensemble models, the solution enabled model-specific resource allocation and independent scaling based on traffic patterns, providing optimal performance while maximizing infrastructure utilization.
To expand hosting options on SageMaker AI without affecting stability, performance, or usability, Salesforce introduced inference component endpoints alongside the existing SME.
This hybrid approach uses the strengths of each. SMEs provide dedicated hosting for each model and predictable performance for critical workloads with consistent traffic patterns, and inference components optimize resource utilization for variable workloads through dynamic scaling and efficient GPU sharing.
The Salesforce AI Platform team created a SageMaker AI endpoint with the desired instance type and initial instance count for the endpoint to handle their baseline inference requirements. Model packages are then attached dynamically, spinning up individual containers as needed. They configured each model, for example, BlockGen and TextEval models as individual inference components specifying precise resource allocations, including accelerator count, memory requirements, model artifacts, container image, and number of model copies to deploy. With this approach, Salesforce could efficiently host multiple model variants on the same endpoint while maintaining granular control over resource allocation and scaling behaviors.
By using the auto scaling capabilities, inference components can set up endpoints with multiple copies of models and automatically adjust GPU resources as traffic fluctuates. This allows each model to dynamically scale up or down within an endpoint based on configured GPU limits. By hosting multiple models on the same endpoint and automatically adjusting capacity in response to traffic fluctuations, Salesforce was able to significantly reduce the costs associated with traffic spikes. This means that Salesforce AI models can handle varying workloads efficiently without compromising performance. The graphic below shows Salesforce’s endpoints before and after the models were deployed with inference components:
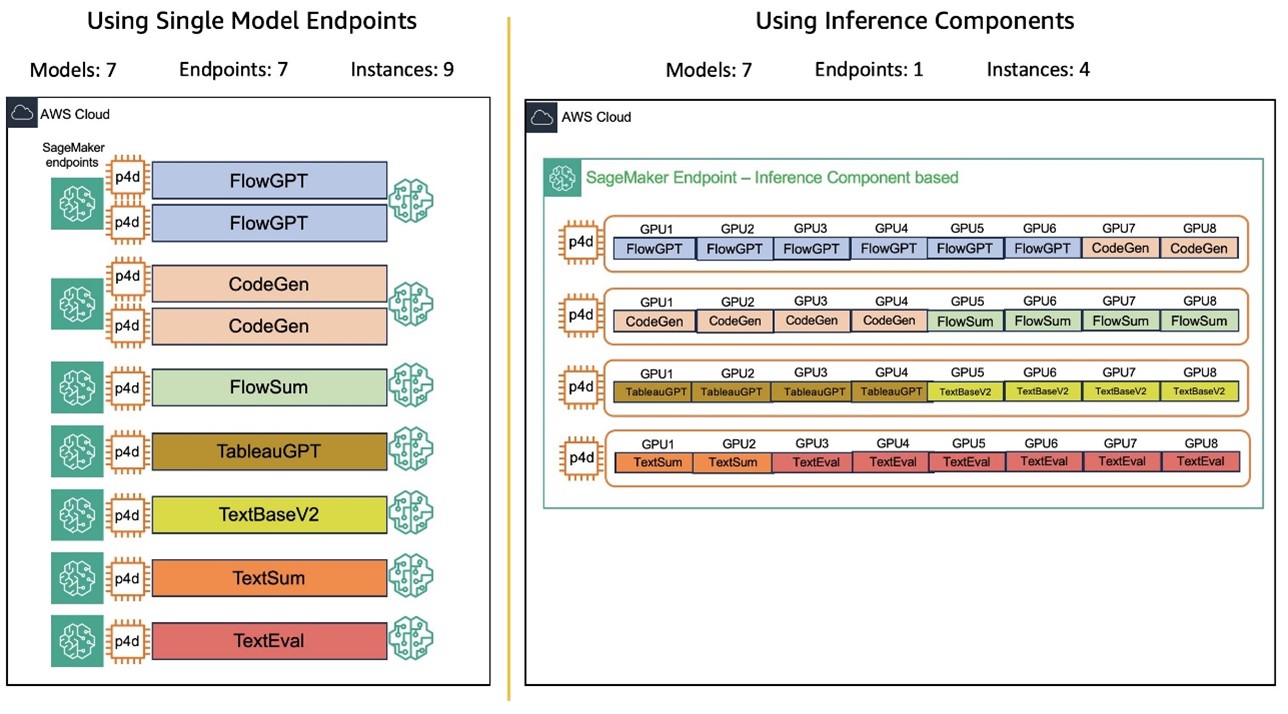
This solution has brought several key benefits:
- Optimized resource allocation – Multiple models now efficiently share GPU resources, eliminating unnecessary provisioning while maintaining optimal performance.
- Cost savings – Through intelligent GPU resource management and dynamic scaling, Salesforce achieved significant reduction in infrastructure costs while eliminating idle compute resources.
- Enhanced performance for smaller models – Smaller models now use high-performance GPUs to meet their latency and throughput needs without incurring excessive costs.
By refining GPU allocation at the model level through inference components, Salesforce improved resource efficiency and achieved a substantial reduction in operational cost while maintaining the high-performance standards their customers expect across a wide range of AI workloads. The cost savings are substantial and open up new opportunities for using high-end, expensive GPUs in a cost-effective manner.
Conclusion
Through their implementation of Amazon SageMaker AI inference components, Salesforce has transformed their AI infrastructure management, achieving up to an eight-fold reduction in deployment and infrastructure costs while maintaining high performance standards. The team learned that intelligent model packing and dynamic resource allocation were keys to solving their GPU utilization challenges across their diverse model portfolio. This implementation has transformed performance economics, allowing smaller models to use high performance GPUs, providing high throughput and low latency without the traditional cost overhead.
Today, their AI platform efficiently serves both large proprietary models such as CodeGen and smaller workloads on the same infrastructure, with optimized resource allocation ensuring high-performance delivery. With this approach, Salesforce can maximize the utilization of compute instances, scale to hundreds of models, and optimize costs while providing predictable performance. This solution has not only solved their immediate challenges of optimizing GPU utilization and cost management but has also positioned them for future growth. By establishing a more efficient and scalable infrastructure foundation, Salesforce can now confidently expand their AI offerings and explore more advanced use cases with expensive, high-performance GPUs such as P4d, P5, and P5en, knowing they can maximize the value of every computing resource. This transformation represents a significant step forward in their mission to deliver enterprise-grade AI solutions while maintaining operational efficiency and cost-effectiveness.
Looking ahead, Salesforce is poised to use the new Amazon SageMaker AI rolling updates capability for inference component endpoints, a feature designed to streamline updates for models of different sizes while minimizing operational overhead. This advancement will enable them to update their models batch by batch, rather than using the traditional blue/green deployment method, providing greater flexibility and control over model updates while using minimal extra instances, rather than requiring doubled instances as in the past. By implementing these rolling updates alongside their existing dynamic scaling infrastructure and incorporating real-time safety checks, Salesforce is building a more resilient and adaptable AI platform. This strategic approach not only provides cost-effective and reliable deployments for their GPU-intensive workloads but also sets the stage for seamless integration of future AI innovations and model improvements.
Check out How Salesforce achieves high-performance model deployment with Amazon SageMaker AI to learn more. For more information on how to get started with SageMaker AI, refer to Guide to getting set up with Amazon SageMaker AI. To learn more about Inference Components, refer to Amazon SageMaker adds new inference capabilities to help reduce foundation model deployment costs and latency.
About the Authors
 Rishu Aggarwal is a Director of Engineering at Salesforce based in Bangalore, India. Rishu leads the Salesforce AI Platform Model Serving Engineering team in solving the complex problems of inference optimizations and deployment of LLMs at scale within the Salesforce ecosystem. Rishu is a staunch Tech Evangelist for AI and has deep interests in Artificial Intelligence, Generative AI, Neural Networks and Big Data.
Rishu Aggarwal is a Director of Engineering at Salesforce based in Bangalore, India. Rishu leads the Salesforce AI Platform Model Serving Engineering team in solving the complex problems of inference optimizations and deployment of LLMs at scale within the Salesforce ecosystem. Rishu is a staunch Tech Evangelist for AI and has deep interests in Artificial Intelligence, Generative AI, Neural Networks and Big Data.
 Rielah De Jesus is a Principal Solutions Architect at AWS who has successfully helped various enterprise customers in the DC, Maryland, and Virginia area move to the cloud. In her current role, she acts as a customer advocate and technical advisor focused on helping organizations like Salesforce achieve success on the AWS platform. She is also a staunch supporter of women in IT and is very passionate about finding ways to creatively use technology and data to solve everyday challenges.
Rielah De Jesus is a Principal Solutions Architect at AWS who has successfully helped various enterprise customers in the DC, Maryland, and Virginia area move to the cloud. In her current role, she acts as a customer advocate and technical advisor focused on helping organizations like Salesforce achieve success on the AWS platform. She is also a staunch supporter of women in IT and is very passionate about finding ways to creatively use technology and data to solve everyday challenges.
 Pavithra Hariharasudhan is a Senior Technical Account Manager and Enterprise Support Lead at AWS, supporting leading AWS Strategic customers with their global cloud operations. She assists organizations in resolving operational challenges and maintaining efficient AWS environments, empowering them to achieve operational excellence while accelerating business outcomes.
Pavithra Hariharasudhan is a Senior Technical Account Manager and Enterprise Support Lead at AWS, supporting leading AWS Strategic customers with their global cloud operations. She assists organizations in resolving operational challenges and maintaining efficient AWS environments, empowering them to achieve operational excellence while accelerating business outcomes.
 Ruchita Jadav is a Senior Member of Technical Staff at Salesforce, with over 10 years of experience in software and machine learning engineering. Her expertise lies in building scalable platform solutions across the retail and CRM domains. At Salesforce, she leads initiatives focused on model hosting, inference optimization, and LLMOps, enabling efficient and scalable deployment of AI and large language models. She holds a Bachelor of Technology in Electronics & Communication from Gujarat Technological University (GTU).
Ruchita Jadav is a Senior Member of Technical Staff at Salesforce, with over 10 years of experience in software and machine learning engineering. Her expertise lies in building scalable platform solutions across the retail and CRM domains. At Salesforce, she leads initiatives focused on model hosting, inference optimization, and LLMOps, enabling efficient and scalable deployment of AI and large language models. She holds a Bachelor of Technology in Electronics & Communication from Gujarat Technological University (GTU).
 Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.






