

Organizations across industries face challenges with high volumes of multi-page documents that require intelligent processing to extract accurate information. Although automation has improved this process, human expertise is still needed in specific scenarios to verify data accuracy and quality.
In March 2025, AWS launched Amazon Bedrock Data Automation, which enables developers to automate the generation of valuable insights from unstructured multimodal content, including documents, images, video, and audio. Amazon Bedrock Data Automation streamlines document processing workflows by automating extraction, transformation, and generation of insights from unstructured content. It minimizes time-consuming tasks like data preparation, model management, fine-tuning, prompt engineering, and orchestration through a unified, multimodal inference API, delivering industry-leading accuracy at lower cost than alternative solutions.
Amazon Bedrock Data Automation simplifies complex document processing tasks, including document splitting, classification, extraction, normalization, and validation, while incorporating visual grounding with confidence scores for explainability and built-in hallucination mitigation, providing trustworthy insights from unstructured data sources. However, although the advanced capabilities of Amazon Bedrock Data Automation deliver exceptional automation, there remain scenarios where human judgment is invaluable. This is where the integration with Amazon SageMaker AI creates a powerful end-to-end solution. By incorporating human review loops into the document processing workflow, organizations can maintain the highest levels of accuracy while maintaining processing efficiency. With a human review loop, organizations can:
- Validate AI predictions when confidence is low
- Handle edge cases and exceptions effectively
- Maintain regulatory compliance through appropriate oversight
- Maintain high accuracy while maximizing automation
- Create feedback loops to improve model performance over time
By implementing human loops strategically, organizations can focus human attention on uncertain portions of documents while allowing automated systems to handle routine extractions, creating an optimal balance between efficiency and accuracy. In this post, we show how to process multi-page documents with a human review loop using Amazon Bedrock Data Automation and SageMaker AI.
Understanding confidence scores
Confidence scores are crucial in determining when to invoke human review. Confidence scores are the percentage of certainty that Amazon Bedrock Data Automation has that your extraction is accurate.
Our goal is to simplify intelligent document processing (IDP) by handling the heavy lifting of accuracy calculation within Amazon Bedrock Data Automation. This helps customers focus on solving their business challenges with Amazon Bedrock Data Automation rather than dealing with complex scoring mechanisms. Amazon Bedrock Data Automation optimizes its models for Expected Calibration Error (ECE), a metric that facilitates better calibration, leading to more reliable and accurate confidence scores.
In document processing workflows, confidence scores are generally interpreted as:
- High confidence (90–100%) – High certainty about its extraction
- Medium confidence (70–89%) – Reasonable certainty with some potential for error
- Low confidence (<70%) – High uncertainty, likely requiring human verification
We recommend testing Amazon Bedrock Data Automation on your own specific datasets to determine the confidence threshold that triggers a human review workflow.
Solution overview
The following architecture provides a serverless solution for processing multi-page documents with human review loops using Amazon Bedrock Data Automation and SageMaker AI.
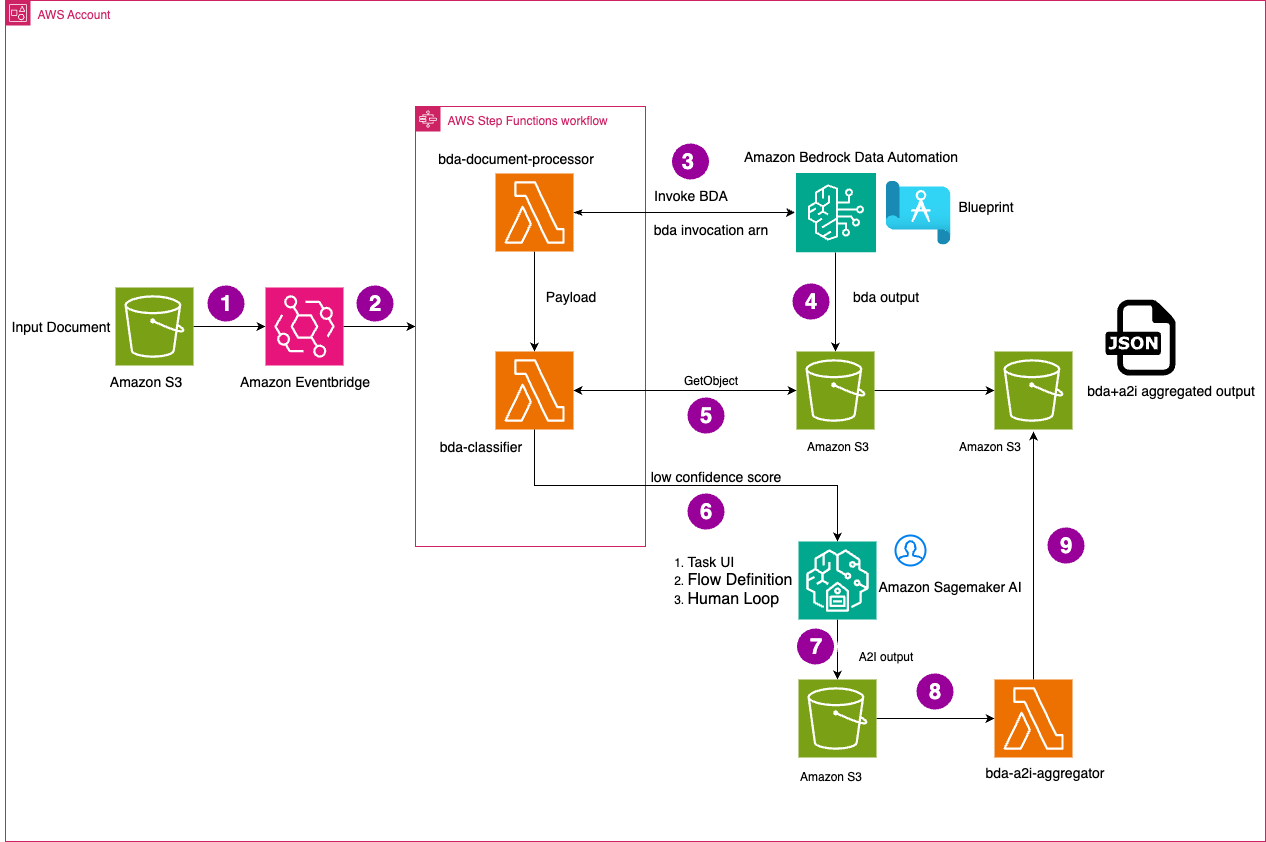
The workflow consists of the following steps:
- Documents are uploaded to an Amazon Simple Storage Service (Amazon S3) input bucket, which serves as entry point for the documents processed through Amazon Bedrock Data Automation.
- An Amazon EventBridge rule automatically detects new objects in the S3 bucket and triggers the AWS Step Functions workflow that orchestrates the document processing pipeline.
- Within the Step Functions workflow, the
bda-document-processorAWS Lambda function is executed, which invokes Amazon Bedrock Data Automation with the appropriate blueprint. Amazon Bedrock Data Automation uses these preconfigured instructions to extract and process information from the document. - Amazon Bedrock Data Automation analyzes the document, extracts key fields with associated confidence scores, and stores the processed output in another S3 bucket. This output contains the extracted information and corresponding confidence levels.
- The Step Functions workflow invokes the
bda-classifierLambda function, which retrieves the Amazon Bedrock Data Automation output from Amazon S3. This function evaluates the confidence scores against predefined thresholds for the extracted fields. - For fields with confidence scores below the threshold, the workflow routes the document to SageMaker AI for human review. Using the custom UI, humans review the tasks and validate the fields from the pages. Reviewers can correct fields that were incorrectly extracted by the automated process.
- The validated and corrected form data from human review is stored in an S3 bucket.
- Once Sagemaker AI output is written to Amazon S3, it executes the
bda-a2i-aggregatorAWS Lambda which updates the payload of Amazon Bedrock Data Automation output with the new value which was reviewed by human. This aggregated output is stored in Amazon S3. This provides the final, high-confidence output ready for downstream systems.
Prerequisites
To deploy this solution, you need the AWS Cloud Development Kit (AWS CDK), Node.js, and Docker installed on your deployment machine. A build script performs the packaging and deployment of the solution.
Deploy the solution
Complete the following steps to deploy the solution:
- Clone the solution repository to your deployment machine.
- Navigate to the project directory and run the build script:
./build.sh
The deployment creates the following resources in your AWS account:
- Two new S3 buckets: one for the initial upload of documents and one for the output of documents
- An Amazon Bedrock Data Automation project and five blueprints used to process the test document
- An Amazon Cognito user pool for the private workforce that Amazon SageMaker Ground Truth provides to SageMaker AI for data that is below a confidence score
- Two Lambda functions and a Step Function workflow used to process the test documents
- Two Amazon Elastic Container Registry (Amazon ECR) container images used for the Lambda functions to process the test documents
Add a new worker to the private workforce
After the build is complete, you must add a worker to the private workforce in SageMaker Ground Truth. Complete the following steps:
- On the SageMaker AI console, under Ground Truth in the navigation pane, choose Labeling workforces, then choose the Private tab.
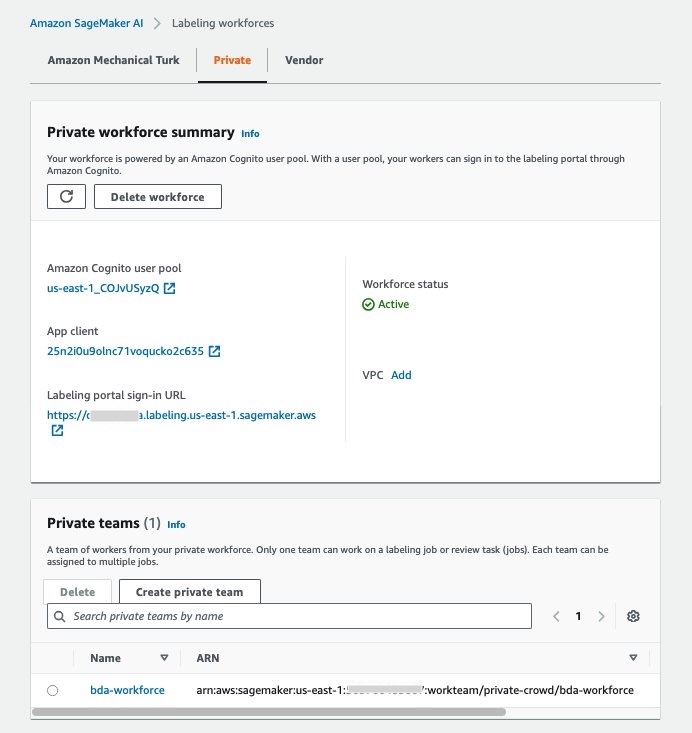
- In the Workers section, choose Invite new workers.
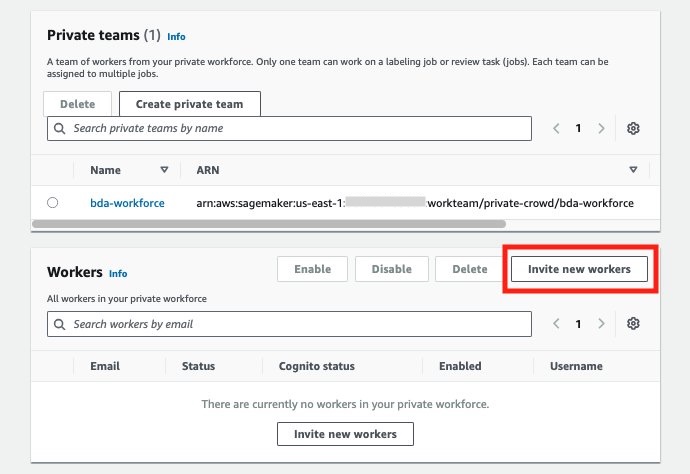
- For Email addresses, enter the email addresses of the workers you want to invite. For this example, use an email you have access to.
- Choose Invite new workers.
After the worker has been added, they will receive an email with a temporary password. This process might take up to 5 minutes before the email is received.
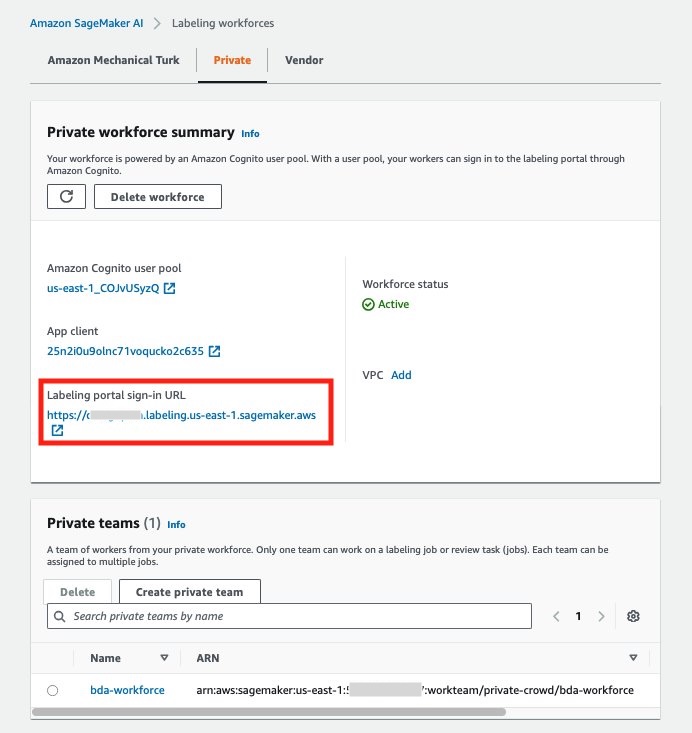
- On the Labeling workforces page, in the Private workforce summary section, choose the link for Labeling portal sign-in URL.
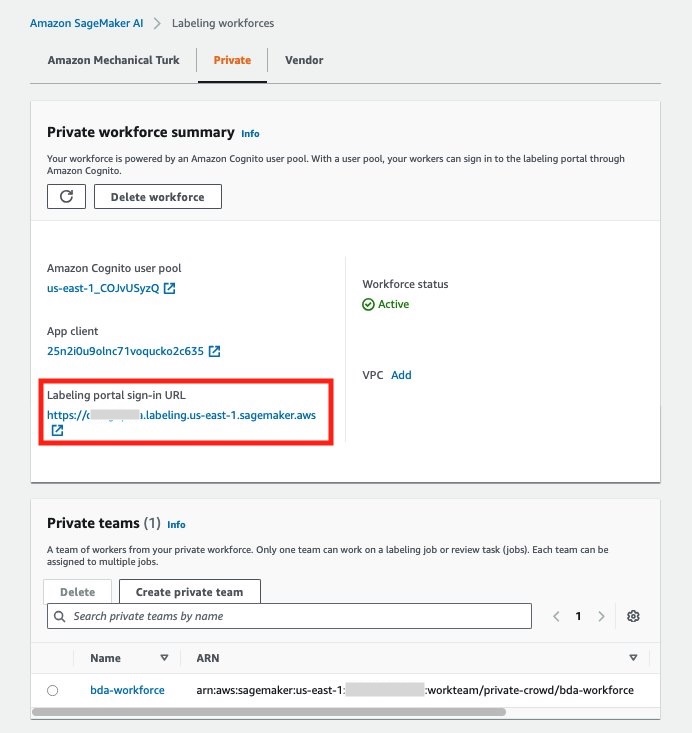
- In the prompt, enter the email address you used earlier to set up a worker and provide the temporary password from the email, then choose Sign In.
- Provide a new password when prompted.
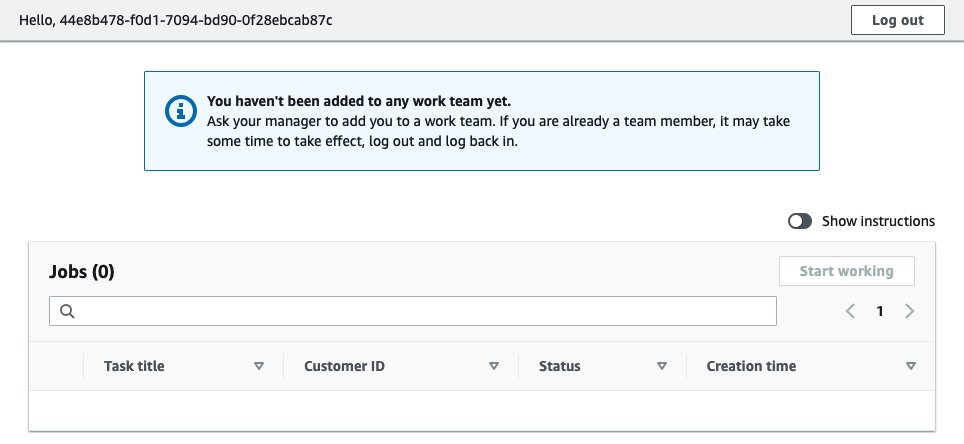
You will be redirected to a job queue page for the private labeling workforce. At the top of the page, a notice states that you are not a member of a work team yet. You must complete that process in the next step in order to make sure that jobs are properly assigned.
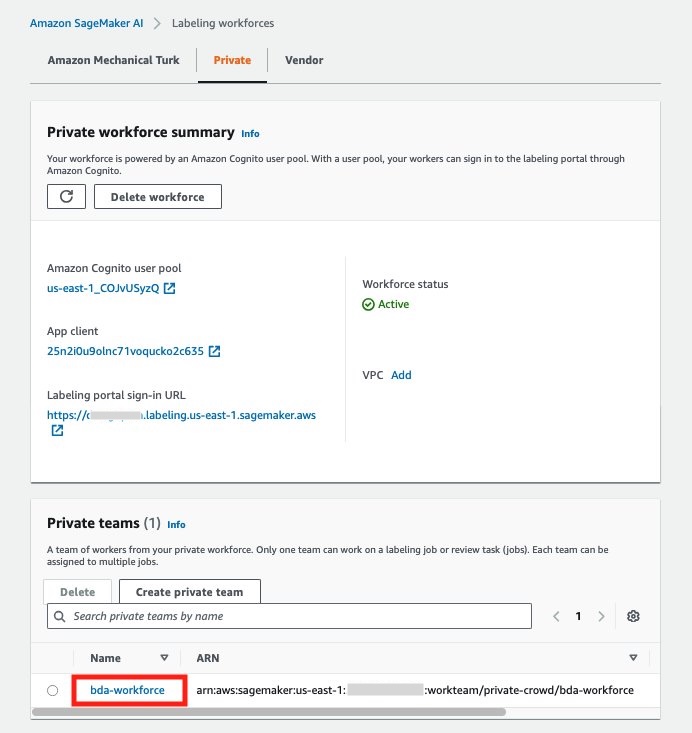
- On the Labeling workforces page, open the private team (for this post,
bda-workforce).
- On the Workers tab, choose Add workers to team.
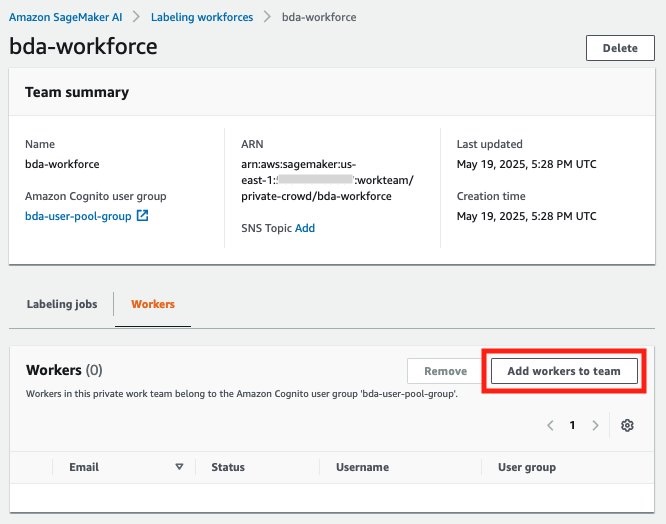
- Add the recently verified worker to the team.
Test the solution
To test the solution, upload the test document located in the assets folder of the project to the S3 bucket used for incoming documents. You can monitor the progress of the system on the Step Functions console or by reviewing the logs through Amazon CloudWatch. After the document is processed, you can see a new job queued up for the user in SageMaker AI. To view this job, navigate back to the Labeling workforces page and choose the link for Labeling portal sign-in URL.
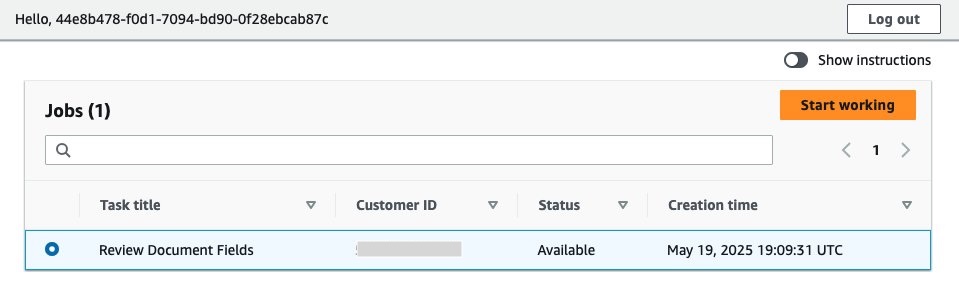
Log in using the email address and updated password from earlier. You will see a page that displays the jobs to be reviewed. Select the job and choose Start working.
In the UI, you can review each item that was below a confidence score (defaulted to 70%) for the processed document.
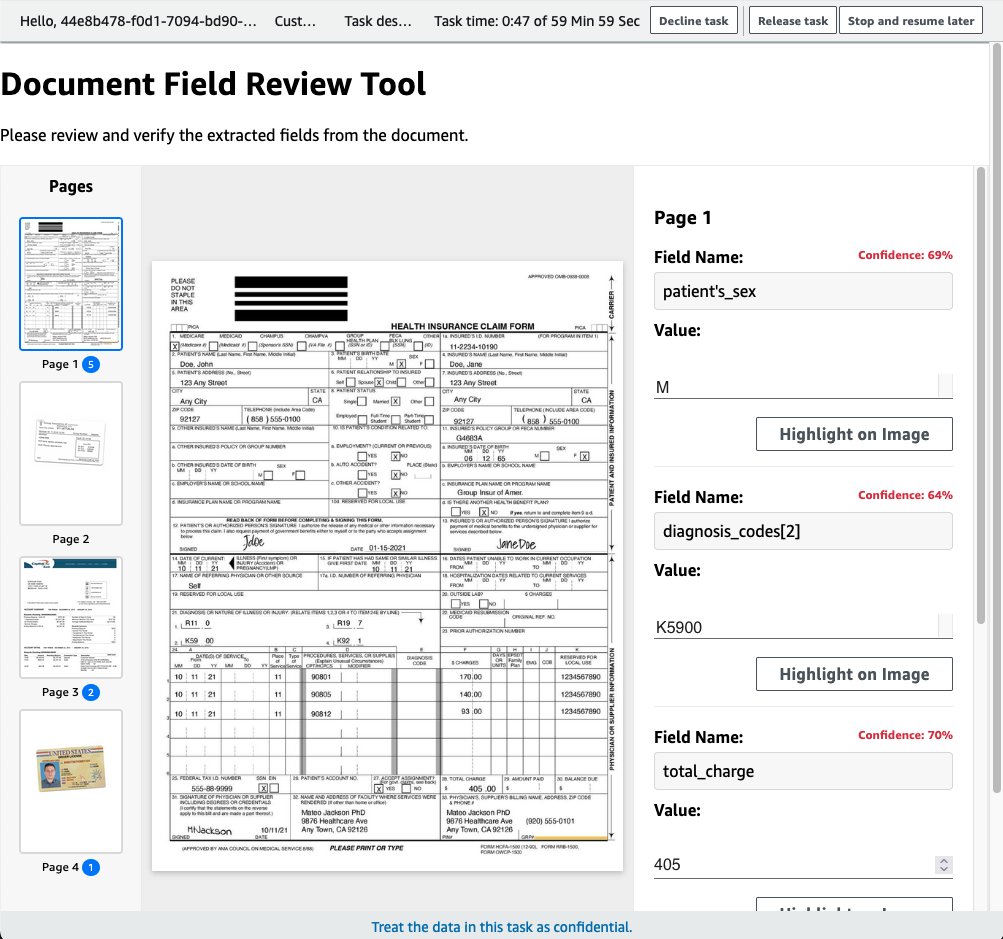
On this page, you can modify the data to the corrected values. The updated data will be saved in the S3 output bucket in the a2i-output/bda-review-flow-definition/<date>/review-loop-<date time stamp>/output.json file. This data can then be processed and used to provide the corrected values for information retrieved from the document.
Clean up
To terminate all resources created in this solution, run the flowing command from the project root directory
Conclusion
In this post, we demonstrated how the combination of Amazon Bedrock Data Automation and SageMaker AI delivers automation efficiency and human-level accuracy for both single-page and multi-page document processing.
We encourage you to explore this pattern with your own document processing challenges. The solution is designed to be adaptable across various document types and can be customized to meet specific business requirements. Try out the complete implementation available in our GitHub repository , where you’ll find all the code and configuration needed to get started.
To learn more about document intelligence solutions on AWS, visit the Amazon Bedrock Data Automation documentation and SageMaker AI documentation .
Please share your experiences in the comments or reach out to the authors with questions. Happy building!
About the authors
 Joe Morotti is a Solutions Architect at Amazon Web Services (AWS), working with Financial Services customers across the US. He has held a wide range of technical roles and enjoy showing customer’s art of the possible. He is an active member of the AWS Technical Field Communities for Generative AI and Amazon Connect. In his free time, he enjoys spending quality time with his family exploring new places and over analyzing his sports team’s performance.
Joe Morotti is a Solutions Architect at Amazon Web Services (AWS), working with Financial Services customers across the US. He has held a wide range of technical roles and enjoy showing customer’s art of the possible. He is an active member of the AWS Technical Field Communities for Generative AI and Amazon Connect. In his free time, he enjoys spending quality time with his family exploring new places and over analyzing his sports team’s performance.
 Prashanth Ramanathan is a Senior Solutions Architect at AWS, passionate about Generative AI, Serverless and Database technologies. He is a former Senior Principal Engineer at a major financial services firm and has led large-scale cloud migrations and modernization efforts.
Prashanth Ramanathan is a Senior Solutions Architect at AWS, passionate about Generative AI, Serverless and Database technologies. He is a former Senior Principal Engineer at a major financial services firm and has led large-scale cloud migrations and modernization efforts.
 Andy Hall is a Senior Solutions Architect with AWS and is focused on helping Financial Services customers with their digital transformation to AWS. Andy has helped companies to architect, migrate, and modernize large-scale applications to AWS. Over the past 30 years, Andy has led efforts around Software Development, System Architecture, Data Processing, and Development Workflows for large enterprises.
Andy Hall is a Senior Solutions Architect with AWS and is focused on helping Financial Services customers with their digital transformation to AWS. Andy has helped companies to architect, migrate, and modernize large-scale applications to AWS. Over the past 30 years, Andy has led efforts around Software Development, System Architecture, Data Processing, and Development Workflows for large enterprises.
 Vikas Shah is a Solutions Architect at Amazon Web Services who specializes in document intelligence and AI-powered solutions. A technology enthusiast, he combines his expertise in document processing, intelligent search, and generative AI to help enterprises modernize their operations. His innovative approach to solving complex business challenges spans across document management, robotics, and emerging technologies.
Vikas Shah is a Solutions Architect at Amazon Web Services who specializes in document intelligence and AI-powered solutions. A technology enthusiast, he combines his expertise in document processing, intelligent search, and generative AI to help enterprises modernize their operations. His innovative approach to solving complex business challenges spans across document management, robotics, and emerging technologies.







