

In December 2025, we announced the availability of Reinforcement fine-tuning (RFT) on Amazon Bedrock starting with support for Nova models. This was followed by extended support for Open weight models such as OpenAI GPT OSS 20B and Qwen 3 32B in February 2026. RFT in Amazon Bedrock automates the end-to-end customization workflow. This allows the models to learn from feedback on multiple possible responses using a small set of prompts, rather than traditional large training datasets.
In this post, we walk through the end-to-end workflow of using RFT on Amazon Bedrock with OpenAI-compatible APIs: from setting up authentication, to deploying a Lambda-based reward function, to kicking off a training job and running on-demand inference on your fine-tuned model. Here, we use the GSM8K math dataset as our working example and target OpenAI’s gpt-oss-20B model hosted on Bedrock.
How reinforcement fine-tuning works
Reinforcement Fine-Tuning (RFT) represents a shift in how we customize large language models (LLMs). Unlike traditional supervised fine-tuning (SFT), which requires models to learn from static I/O pairs, RFT enables models to learn through an iterative feedback loop where they generate responses, receive evaluations, and continuously improve their decision-making capabilities.
The core concept: learning from feedback
At its heart, reinforcement learning is about teaching an agent (in this case, an LLM) to make better decisions by providing feedback on its actions. Think of it like training a chess player. Instead of showing them every possible move in every possible situation (which is impossible), you let them play and tell them which moves led to winning positions. Over time, the player learns to recognize patterns and make strategic decisions that lead to success. For LLMs, the model generates multiple possible responses to a given prompt, receives scores (rewards) for each response based on how well they meet your criteria, and learns to favor the patterns and strategies that produce higher-scoring outputs.
Key components of RFT
Key RFT components include the agent/actor (policy) model, input states to the model, output actions from the model, and the reward function as shown in the following diagram:
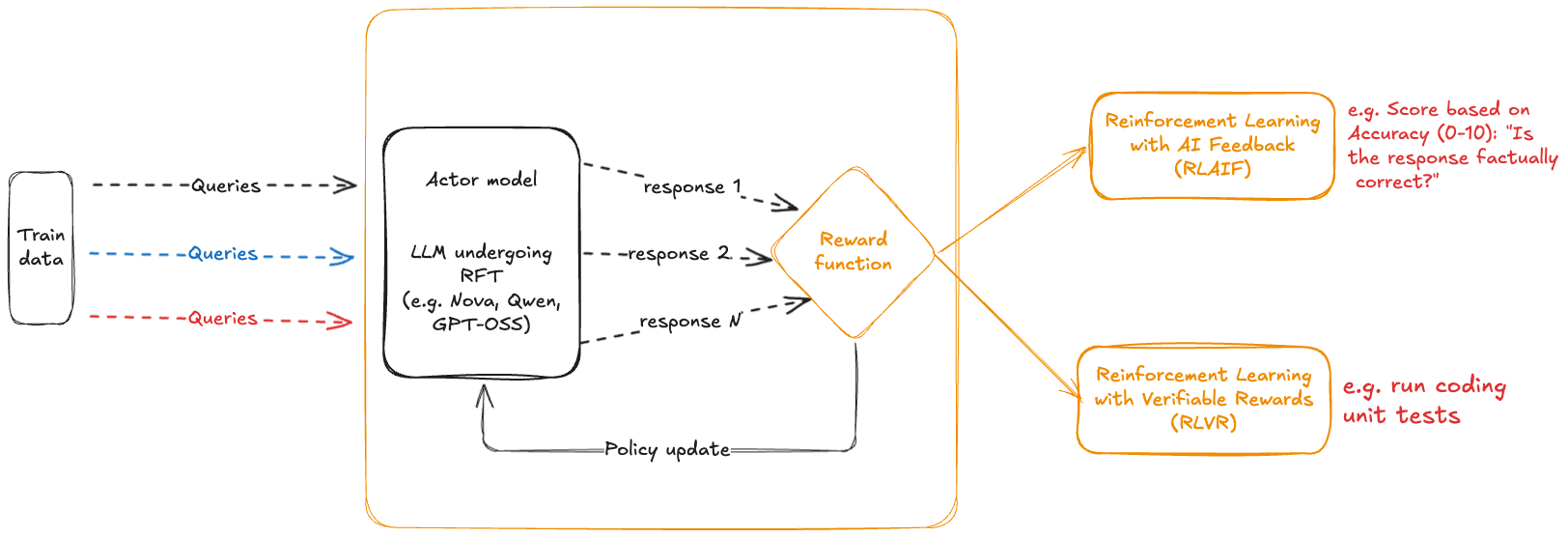
The actor model is the foundation model (FM) that you’re customizing. In Amazon Bedrock RFT, this could be Amazon Nova, Llama, Qwen, or other supported models. The state is the current context, including the prompt, conversation history (for multi-turn interactions), and the relevant metadata. The action is the model’s response to a prompt. The reward function assigns a numerical score to a (state, action) pair, evaluating the goodness of a model response for a given state. In doing so, the reward function can use additional information like ground truth responses or unit tests for code generation. This is the critical feedback signal that drives learning. Higher rewards indicate better responses.
One of RFT’s key advantages is that the model learns from responses it generates during training, not only from pre-collected examples. This approach unlocks several compounding benefits. Because the model actively explores novel approaches and learns from the results, it can adapt in real time: as it improves, it naturally encounters new scenarios that push it further. This also makes the process far more efficient, alleviating the need to pre-generate and label thousands of examples upfront. The result is a system capable of continuous improvement, growing stronger as it encounters an ever-more-diverse range of situations. This online learning capability is what enables RFT to achieve superior performance on complex tasks like code generation, mathematical reasoning, and multi-turn conversations. For verifiable tasks like math, this is especially effective because correctness checking is fully automatic – avoiding the need for human labeling.
How Amazon Bedrock RFT works
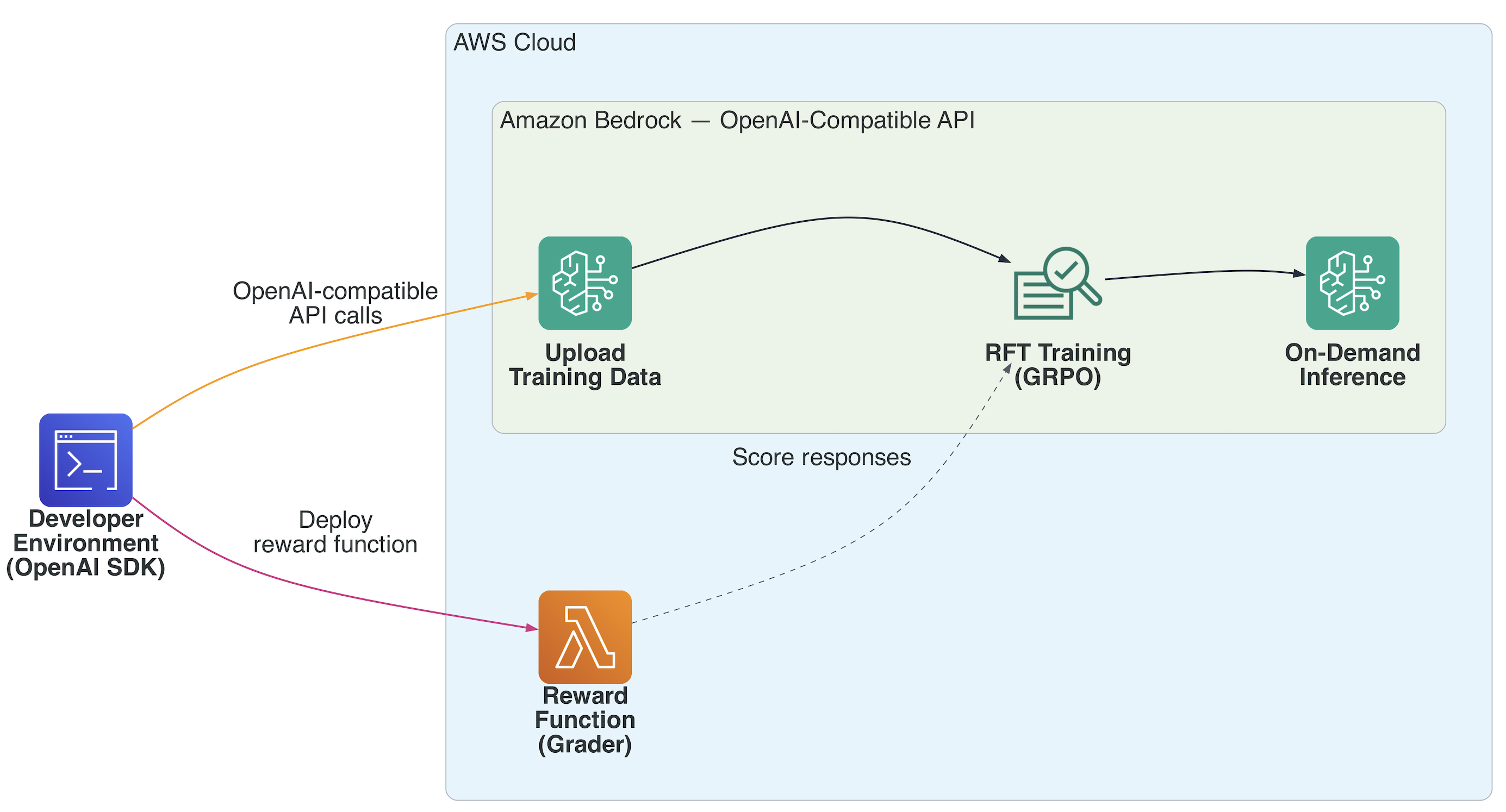
Amazon Bedrock RFT is built to make reinforcement fine-tuning practical at the enterprise level. It handles the heavy lifting, so teams can focus on the problem that they’re solving rather than the infrastructure underneath it. The entire RFT pipeline runs automatically. For each prompt in your training dataset, Amazon Bedrock generates multiple candidate responses from your actor model, managing batching, parallelization, and resource allocation behind the scenes. Reward computation scales just as seamlessly. Whether you’re using verifiable rewards or an LLM-as-Judge setup, Amazon Bedrock orchestrates evaluation across thousands of prompt-response pairs while handling concurrency and error recovery without manual intervention. Policy optimization runs on GRPO, a state-of-the-art reinforcement learning algorithm, with built-in convergence detection so training stops when it should. Throughout the process, Amazon CloudWatch metrics and the Amazon Bedrock console give you real-time visibility into reward trends, policy updates, and overall model performance, so you can know where training stands. The workflow starts from your development environment (VS Code, Terminal, Jupyter, or SageMaker AI notebook) using the standard OpenAI SDK pointed at Bedrock’s Mantle endpoint. From there:
- Upload training data via the Files API (.jsonl format with messages and reference answers)
- Deploy a reward function as an AWS Lambda that scores model-generated responses
- Create the fine-tuning job — Bedrock’s GRPO engine generates responses, sends them to your Lambda grader, and updates weights based on reward scores
- Monitor training via events and checkpoints
- Invoke your fine-tuned model on-demand — no endpoint provisioning, no hosting.
Your data doesn’t leave the secure environment of AWS during the process, and isn’t used to train models provided by Amazon Bedrock. Here, we walk you through a specific use case of training a OpenAI GPT-OSS model with the GSM8K dataset. For more details, see the Bedrock RFT User Guide.
Prerequisites
Before you can get started, you need:
- An AWS account with Amazon Bedrock access in a supported AWS Region
- A Bedrock API key (short-term or long-term). You can also authenticate using AWS Sigv4 credentials but in this walkthrough we use an Amazon Bedrock API Key. For more information, see Access and security for open-weight models in the Amazon Bedrock User Guide.
- IAM roles for Lambda execution and Amazon Bedrock fine-tuning
- Python with openai, boto3, and
aws-bedrock-token-generatorinstalled. If you’re working on a shell inside a venv, or with a Jupter notebook, you can do:
Step 1: Configure the OpenAI client
Point the standard OpenAI SDK at your Amazon Bedrock Mantle endpoint. Authentication uses an AmazonBedrock API key generated through the aws-bedrock-token-generator library:
That’s it. Every subsequent call uses the standard OpenAI SDK interface! Note: We recommend using and refreshing short-term Amazon bedrock keys as needed rather than setting and using long term ones that don’t expire.
Step 2: Prepare and upload training data
Each record in the dataset requires a messages field and can optionally include a reference_answer field. The messages field contains the prompt presented to the model, formatted using the OpenAI message standard where each message specifies a role (such as “user”) and corresponding content. The optional reference_answer field provides supplementary context for reward computation, such as a ground-truth answer, evaluation rule, or scoring dimensions used by the reward function.
For GSM8K examples, each training sample contains a mathematical word problem in the user message and a reference answer containing the correct numerical solution. The prompt instructs the model to provide its reasoning within structured tags and present the final answer in a boxed{} format that the reward function can reliably extract, as in the following example:
We provide a helper function to convert the raw GSM8K records to JSONL format compatible with Amazon Bedrock RFT in this GitHub repository.
Note that the data_source field makes sure that the appropriate reward function is applied during training while the structured prompt formats align the outputs with the reward function’s extraction logic.
As previously mentioned, the training data is a JSONL file where each line contains a conversation with messages and a reference answer. For GSM8K, this looks like:
You can use additional fields here that might be useful for your grader Lambda function in the step we see later, but note that the messages structure and reference_answer are mandatory.
We can then upload our prepared dataset via the Files API:
Step 3: Deploy a Lambda reward function
The reward function is the core of RFT. It receives model-generated responses and returns a score. For math problems, this is straightforward: extract the answer and compare it to ground truth.
Here is the reward function used in this walkthrough (from the sample repository):
The function returns a list of RewardOutput objects, each containing an aggregate_reward_score between 0 and 1. Deploy this as an AWS Lambda function with a 5-minute timeout and 512 MB memory. Note that you can completely customize what happens inside this reward Lambda function to suit your use case. Amazon Bedrock also supports model-as-a-judge graders for subjective tasks where automated verification isn’t possible. For more information about setting up reward functions, see Setting up reward functions for open-weight models.
Step 4: Create the fine-tuning job
Now we use the following single API call to start the job:
Notice that the create call for the previous fine-tuning job uses the following hyperparameters:
| Parameter | Description |
n_epochs |
Number of full passes through the training data. Start with 1. |
batch_size |
Prompts per training step. Larger = more stable updates. |
learning_rate_multiplier |
We recommend using a value <1.0 for stability. |
Step 5: Monitor training
To track progress of the job, we use the list events API as follows:
For a GPT-OSS example job that uses the GSM8K data subset, the training runs for a total of 67 steps with various events being emitted as the training job progresses. Here’s a timeline of these steps:
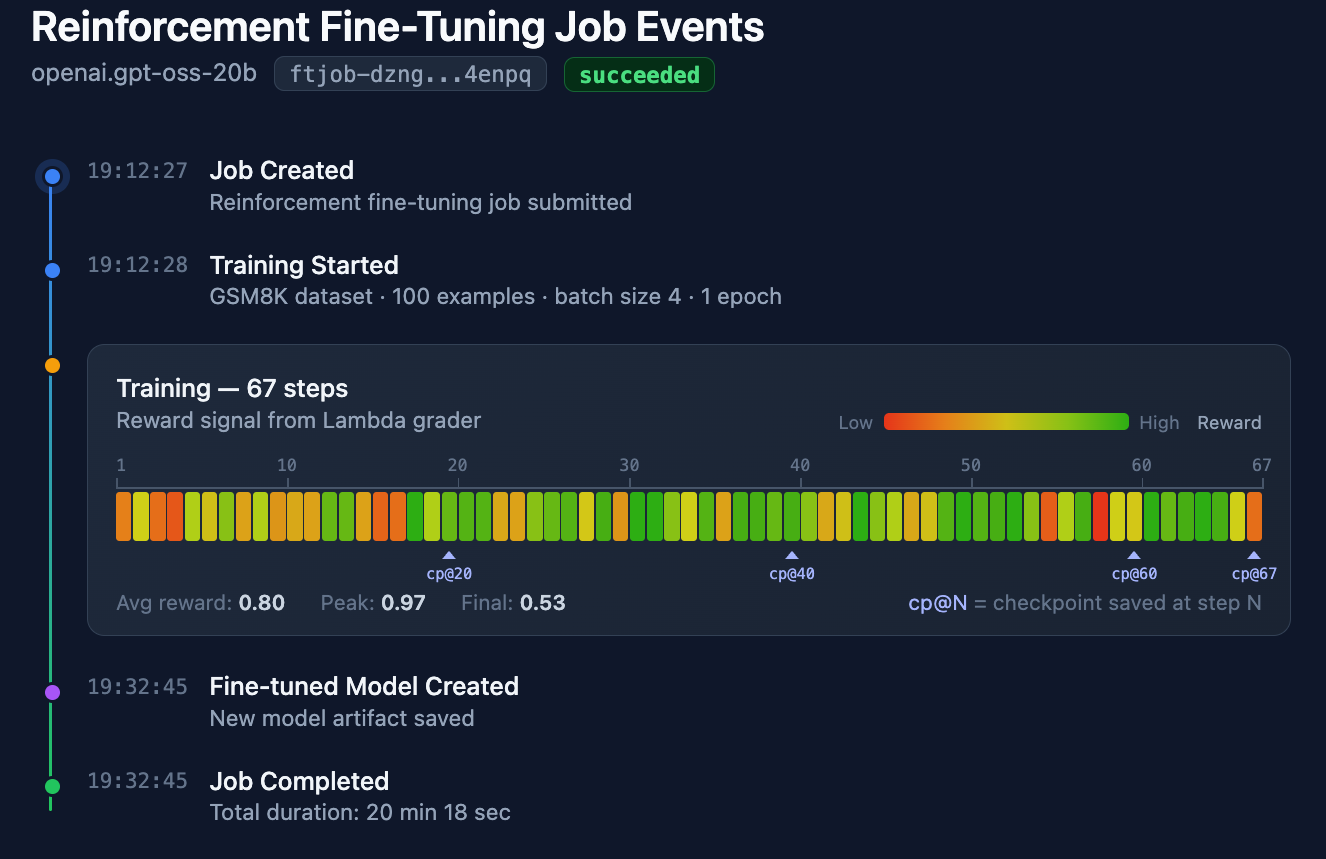
Now let’s dissect one of these events during training progress:
Let’s discuss what these mean:
| Metric | Meaning |
| step / total_steps | Current training step / out of total |
| critic_rewards_mean | Average reward score across the batch (0.4375 means ~44% of responses got correct answers from your grader). This is the primary metric to watch — you want it trending up. |
| actor_pg_loss | Policy gradient loss. This is the objective being optimized — how much the model’s policy is being pushed toward higher-reward responses. Fluctuates naturally; no single “good” value. |
| actor_entropy | How spread out the model’s token probability distribution is. Higher = more exploratory/diverse outputs. If it collapses toward 0, the model is becoming too deterministic (mode collapse). You want it to decrease gradually, not crash. |
| actor_grad_norm | Magnitude of the gradient update to the actor (the model). Large spikes can indicate training instability. Yours is very small (0.0009), which suggests stable, conservative updates. |
| critic_advantages_mean | Average advantage estimate—how much better/worse a response was compared to the critic’s baseline prediction. Near-zero (0.014) means that the critic is well-calibrated. Large positive values mean that the model is doing much better than expected; large negative means worse. |
| response_length_mean | Average token length of generated responses (519). Worth monitoring—if it grows unboundedly, the model may be gaming length for reward. |
What to watch for during training:
critic_rewards_meantrending upward = model is learningactor_entropycollapsing to 0 = mode collapse (bad)actor_grad_normspiking = instabilityresponse_length_meanexploding = reward hacking?
The sample code also provides an example of how to plot these metrics.
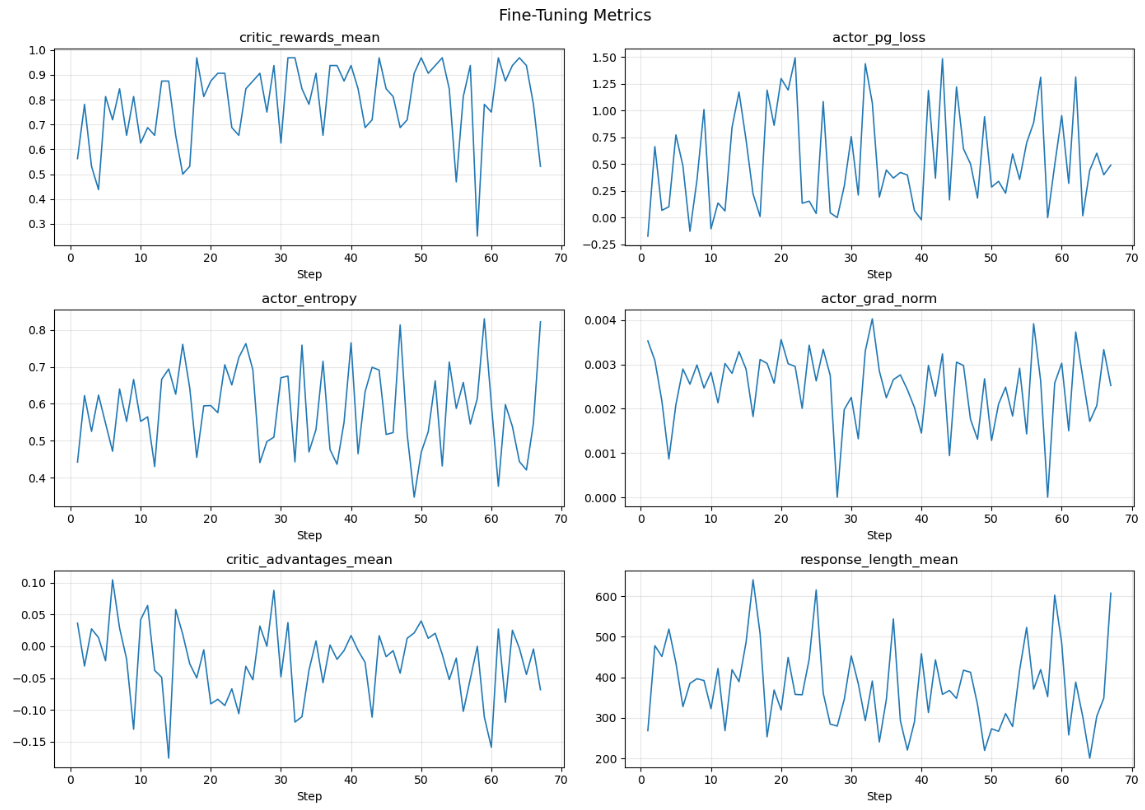
The reward curve shows the model improving from ~0.56 to consistently 0.85–0.97 by mid training. Response lengths also trend shorter over time, suggesting the model learned to be more concise while solving GSM8K problems correctly. Here’s List checkpoints as they are saved:
Step 6: Run on-demand inference
After the job succeeds, invoke your fine-tuned model directly. No endpoint provisioning, no hosting:
You can also use the responses API to stream responses from the fine-tuned model:
Conclusion
Reinforcement fine-tuning on Amazon Bedrock brings together three things that make the end-to-end workflow practical:
- OpenAI SDK compatibility — no new SDK to learn. Point
OPENAI_BASE_URLandOPENAI_API_KEYat Bedrock and use the sameclient.fine_tuning.jobs.create()calls. - Lambda-based reward functions — write your scoring logic in Python, deploy as Lambda, and Amazon Bedrock handles the training loop (GRPO) for you.
- On-demand inference — no endpoint management. Call
client.chat.completions.create()with your fine-tuned model ID and pay per token.
The full notebook with end-to-end code for both GPT-OSS 20B and Qwen3 32B is available on GitHub:
For more details, see the Amazon Bedrock Reinforcement Fine-Tuning documentation.







