

Building custom foundation models requires coordinating multiple assets across the development lifecycle such as data assets, compute infrastructure, model architecture and frameworks, lineage, and production deployments. Data scientists create and refine training datasets, develop custom evaluators to assess model quality and safety, and iterate through fine-tuning configurations to optimize performance. As these workflows scale across teams and environments, tracking which specific dataset versions, evaluator configurations, and hyperparameters produced each model becomes challenging. Teams often rely on manual documentation in notebooks or spreadsheets, making it difficult to reproduce successful experiments or understand the lineage of production models.
This challenge intensifies in enterprise environments with multiple AWS accounts for development, staging, and production. As models move through deployment pipelines, maintaining visibility into their training data, evaluation criteria, and configurations requires significant coordination. Without automated tracking, teams lose the ability to trace deployed models back to their origins or share assets consistently across experiments. Amazon SageMaker AI supports tracking and managing assets used in generative AI development. With Amazon SageMaker AI you can register and version models, datasets, and custom evaluators, then automatically capturing relationships and lineage as you fine-tune, evaluate, and deploy generative AI models. This reduces manual tracking overhead and provides complete visibility into how models were created, from base foundation model through production deployment.
In this post, we’ll explore the new capabilities and core concepts that help organizations track and manage models development and deployment lifecycles. We will show you how the features are configured to train models with automatic end-to-end lineage, from dataset upload and versioning to model fine-tuning, evaluation, and seamless endpoint deployment.
Managing dataset versions across experiments
As you refine training data for model customization, you typically create multiple versions of datasets. You can register datasets and create new versions as your data evolves, with each version tracked independently. When you register a dataset in SageMaker AI, you provide the S3 location and metadata describing the dataset. As you refine your data—whether adding more examples, improving quality, or adjusting for specific use cases—you can create new versions of the same dataset. Each version, as shown in the following image, maintains its own metadata and S3 location so you can track the evolution of your training data over time.
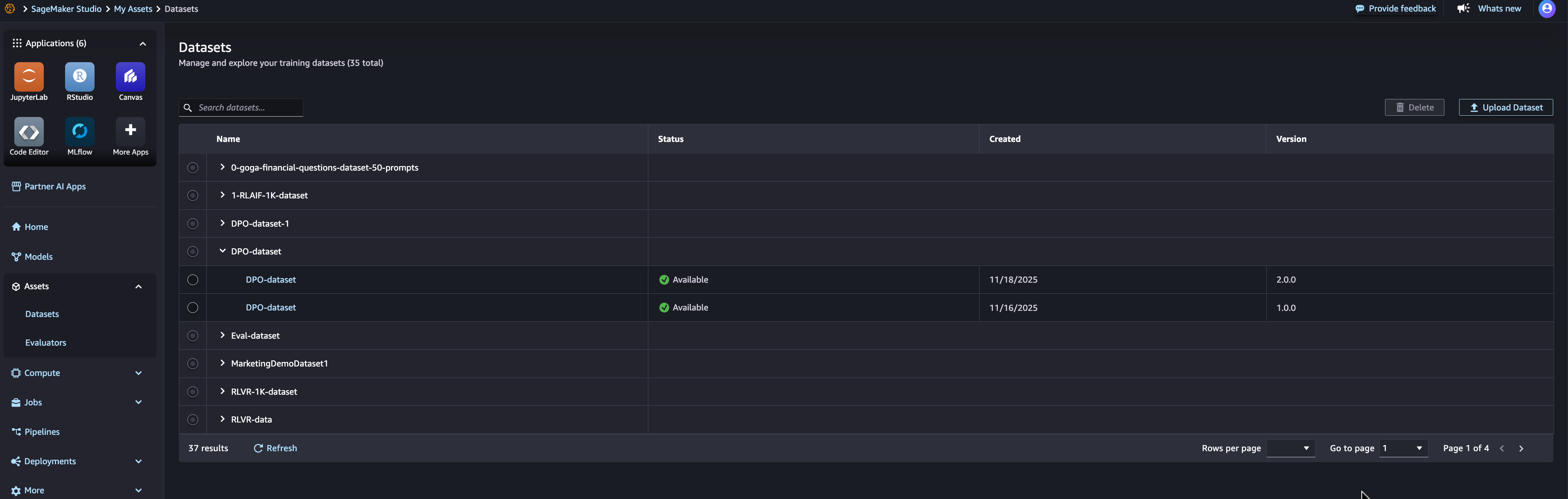
When you use a dataset for fine-tuning, Amazon SageMaker AI automatically links the specific dataset version to the resulting model. This supports the comparison between models trained with different dataset versions and helps you understand which data refinements led to better performance. You can also reuse the same dataset version across multiple experiments for consistency when testing different hyperparameters or fine-tuning techniques.
Creating reusable custom evaluators
Evaluating custom models often requires domain-specific quality, safety, or performance criteria. A custom evaluator consists of Lambda function code that receives input data and returns evaluation results including scores and validation status. You can define evaluators for various purposes—checking response quality, assessing safety and toxicity, validating output format, or measuring task-specific accuracy. You can track custom evaluators using AWS Lambda functions that implement your evaluation logic, then version and reuse these evaluators across models and datasets, as shown in the following image.
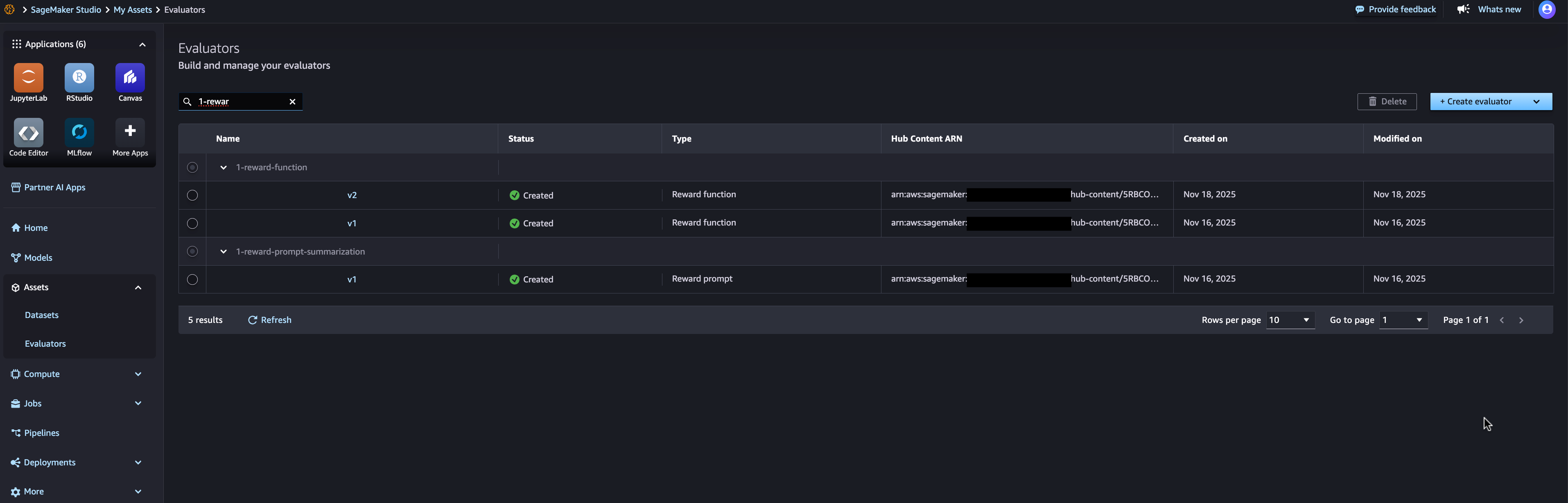
Automatic lineage tracking throughout the development lifecycle
SageMaker AI lineage tracking capability automatically captures relationships between assets as you build and evaluate models. When you create a fine-tuning job, Amazon SageMaker AI links the training job to input datasets, base foundation models, and output models. When you run evaluation jobs, it connects evaluations to the models being assessed and the evaluators used. This automatic lineage capture means you don’t need to manually document which assets were used for each experiment. You can view the complete lineage for a model, showing its base foundation model, training datasets with specific versions, hyperparameters, evaluation results, and deployment locations, as shown in the image below.
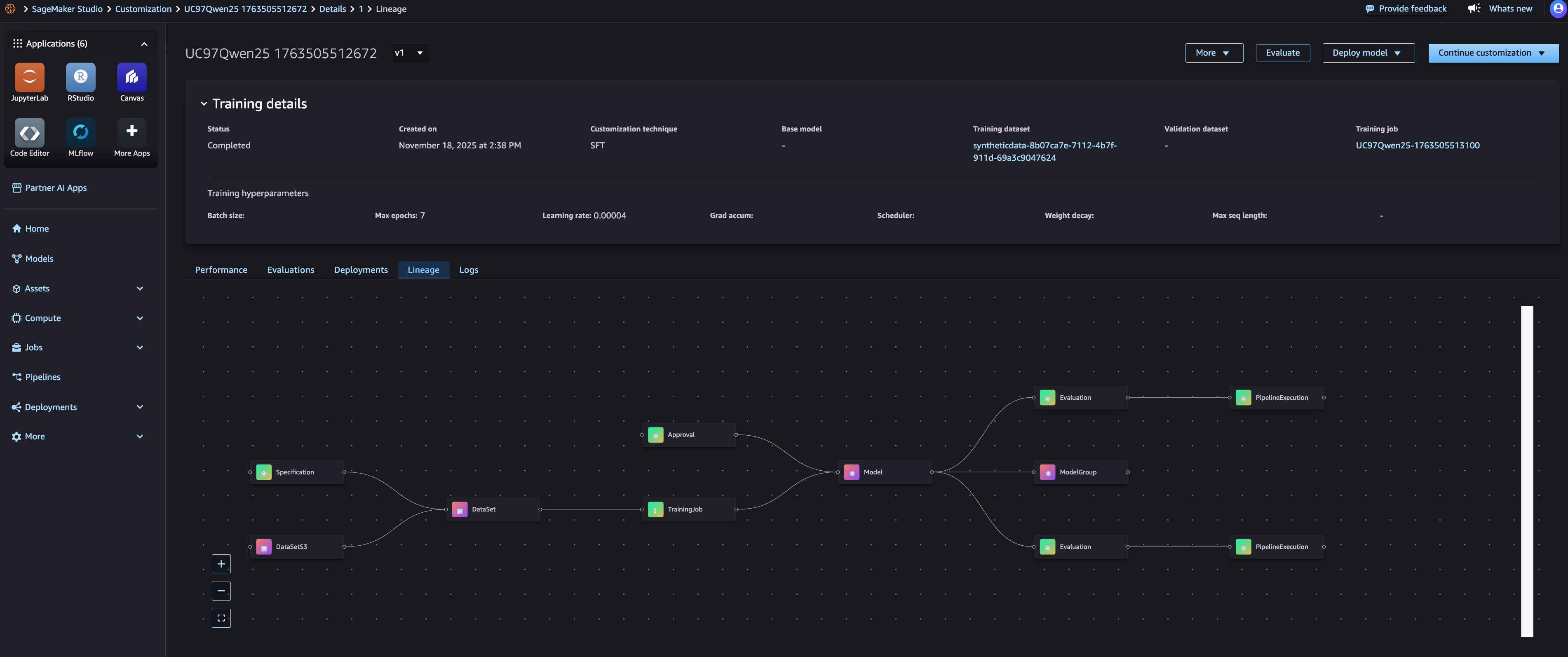
With the lineage view, you can trace any deployed models back to their origins. For example, if you need to understand why a production model behaves in a certain way, you can see exactly which training data, fine-tuning configuration, and evaluation criteria were used. This is particularly valuable for governance, reproducibility, and debugging purposes. You can also use lineage information to reproduce experiments. By identifying the exact dataset version, evaluator version, and configuration used for a successful model, you can recreate the training process with confidence that you’re using identical inputs.
Integrating with MLflow for experiment tracking
The model customization capabilities of Amazon SageMaker AI are by default behavior integrated with SageMaker AI MLflow Apps, providing automatic linking between model training jobs and MLflow experiments. When you run model customization jobs, all the necessary MLflow actions are automatically performed for you – the default SageMaker AI MLflow App is automatically used, an MLflow experiment selected for you and all the metrics, parameters, and artifacts are logged for you. From the SageMaker AI Studio model page, you will be able to see metrics sourced from MLflow (as shown in the following image) and further view full metrics within the associated MLflow experiment.
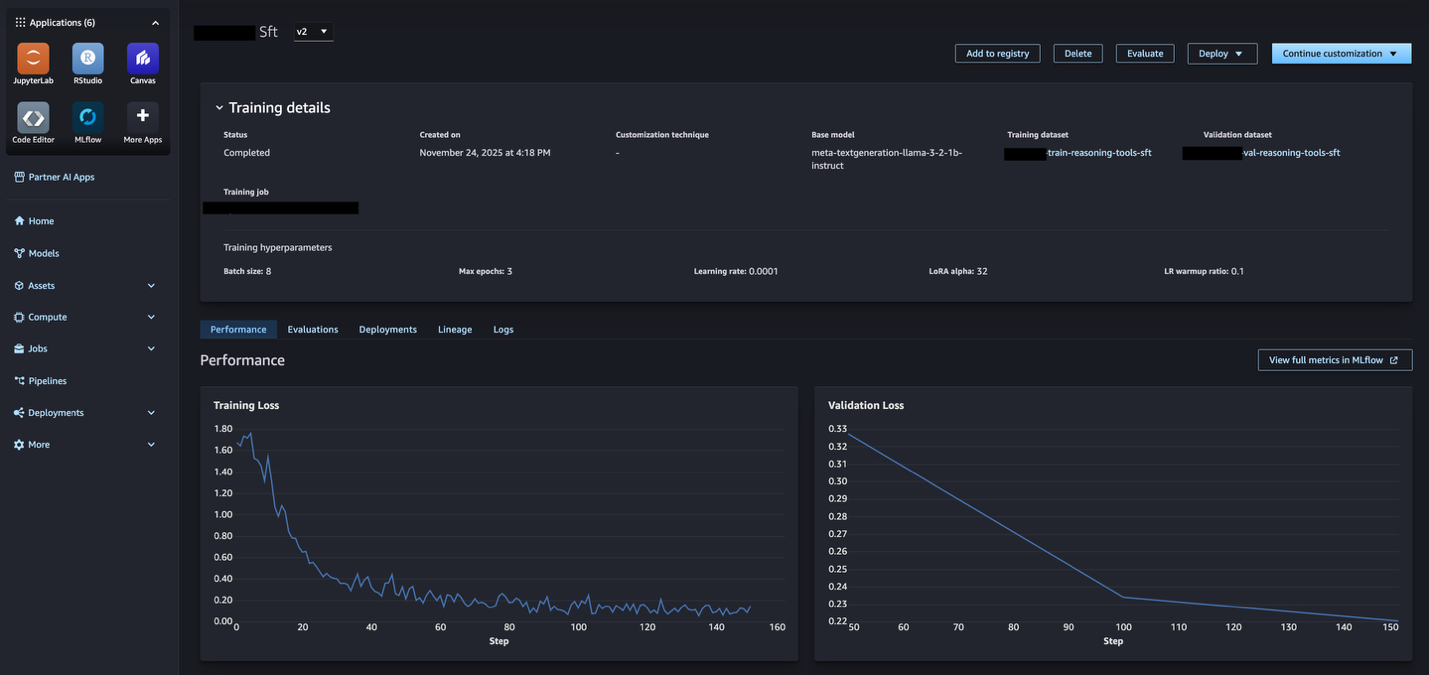
With MLflow integration it is straightforward to compare multiple model candidates. You can use MLflow to visualize performance metrics across experiments, identify the best-performing model, then use the lineage to understand which specific datasets and evaluators produced that result. This helps you make informed decisions about which models to promote to production based on both quantitative metrics and asset provenance.
Getting started with tracking and managing generative AI assets
By bringing these various model customization assets and processes—dataset versioning, evaluator tracking, model performance, model deployment – you can turn the scattered model assets into a traceable, reproducible, and production ready workflow with automatic end-to-end lineage. This capability is now available in supported AWS Regions. You can access this capability through Amazon SageMaker AI Studio, and the SageMaker python SDK.
To get started:
- Open Amazon SageMaker AI Studio and navigate to the Models section.
- Customize the JumpStart base models to create a model.
- Navigate to the Assets section to manage datasets and evaluators.
- Register your first dataset by providing an S3 location and metadata.
- Create a custom evaluator using an existing Lambda function or create a new one.
- Use registered datasets in your fine-tuning jobs—lineage is captured automatically.
- View lineage for the model to see complete relationships.
For more information, visit the Amazon SageMaker AI documentation.
About the authors
 Amit Modi is the product leader for SageMaker AI MLOps, ML Governance, and Inference at AWS. With over a decade of B2B experience, he builds scalable products and teams that drive innovation and deliver value to customers globally.
Amit Modi is the product leader for SageMaker AI MLOps, ML Governance, and Inference at AWS. With over a decade of B2B experience, he builds scalable products and teams that drive innovation and deliver value to customers globally.
 Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customer through their AIOps journey across model training, GenAI applications like Agents, and scaling GenAI use-cases. He also focuses on go-to-market strategies helping AWS build and align products to solve industry challenges in the generative AI space. You can connect with Sandeep on LinkedIn to learn about GenAI solutions.
Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customer through their AIOps journey across model training, GenAI applications like Agents, and scaling GenAI use-cases. He also focuses on go-to-market strategies helping AWS build and align products to solve industry challenges in the generative AI space. You can connect with Sandeep on LinkedIn to learn about GenAI solutions.







